速度比 GPT-5 快三倍,便宜六倍。
本周四,马斯克的 xAI 正式推出了旗下的最新代码模型 Grok Code Fast 1。
终于赶在了马斯克承诺的 8 月 deadline 之内。
该模型也被认为是 Grok 4 的代码版本,旨在为「agentic 编程」(AI 自动执行编程任务)提供极速且经济的解决方案。在这一范式内,AI 在 IDE 内会自动调用工具(如 grep、终端、文件编辑)并完成代码任务。
xAI 表示,虽然如今的大语言模型(LLM)功能强大,但它们往往并非专为智能体编码工作流而设计,对此,工程师们构建了更灵活、响应更快的解决方案,针对日常任务进行了优化。
grok-code-fast-1 是从零开始训练的语言模型,采用全新的模型架构。为了奠定坚实的基础,xAI 精心构建了一个包含丰富编程相关内容的预训练语料库。在训练后也精选了能够反映真实世界拉取请求和编码任务的高质量数据集。
在整个训练过程中,xAI 与发布合作伙伴密切合作,不断完善和优化模型在平台上的行为。据介绍,grok-code-fast-1 已经熟练掌握了 grep、终端和文件编辑等常用工具的使用方法,因此应该能够在人们常用的 IDE 中轻松上手。
本周发布时,xAI 宣布在大量平台上免费提供一周的 grok-code-fast-1,包括 GitHub Copilot、Cursor、Cline、Roo Code、Kilo Code、opencode 和 Windsurf。
其实在本周早些时候,该模型已在部分平台上静默上线了,当时的代号为 Sonic。
在博客文章与模型卡中,xAI 介绍了新模型的一些特性,但模型架构、数据和微调的细节并不详尽。xAI 的推理和超级计算团队开发了多项创新技术,显著提升了代码模型的服务速度,创造了独特的响应式体验。在人们读完 AI 思考轨迹的第一段之前,模型就已经调用了数十种工具。
xAI 还投入了大量精力进行快速缓存优化,在各个合作伙伴的平台上运行时,缓存命中率通常超过 90%。
grok-code-fast-1 在整个软件开发栈中都非常灵活,尤其擅长 TypeScript、Python、Java、Rust、C++ 和 Go。它可以在极少的监督下完成常见的编程任务,从构建从零到一的项目、提供对代码库问题的深刻解答,到执行精准的错误修复,不一而足。
比如使用 grok-code-fast-1,Danny Limanseta 一天之内就制作出了这样的小游戏:

grok-code-fast-1 的价格也相对便宜:
每百万个输入 token 0.20 美元
每百万个输出 token 1.50 美元
每百万个缓存输入 token 0.02 美元
它专为应对开发人员日常面临的任务而设计,在性能和成本之间实现了平衡,可以认为是快速高效地处理常见编码任务的多功能之选。
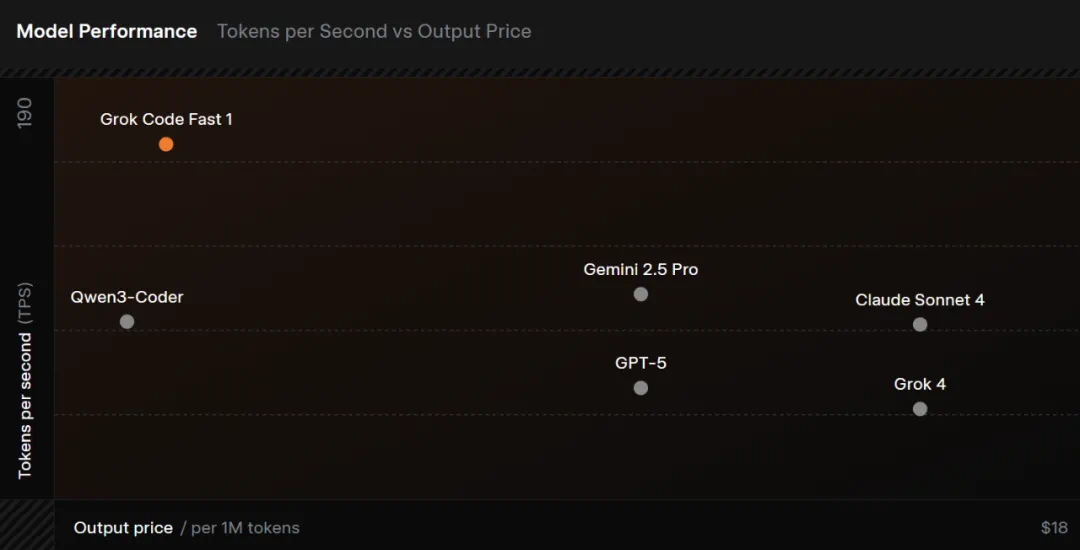
在 SWE-Bench-Verified 的完整子集测试中,grok-code-fast-1 使用内部测试工具获得了 70.8% 的得分,目前它在这个位置:
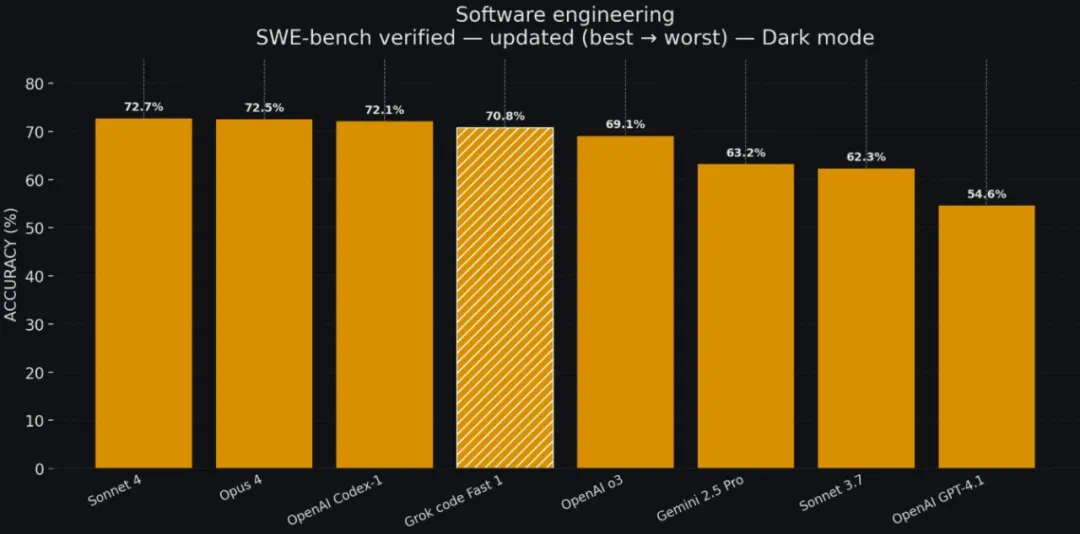
可见分数已经接近目前公认代码能力最强的 Claude 4 系列。不过 xAI 还表示,在开发 grok-code-fast-1 时,他们更多的以现实世界的人工评估为指导,专注于可用性和用户满意度。最终,很多程序员已将 Grok 模型评为快速可靠的日常编码任务模型。
xAI 表示,未来其团队还将专注于持续更新 grok-code-fast-1,一个支持多模态输入、并行工具调用和扩展上下文长度的新变体已在训练中。
参考内容:
https://x.ai/news/grok-code-fast-1
https://data.x.ai/2025-08-26-grok-code-fast-1-model-card.pdf


