大家好,我是肆〇柒。今天我们要探讨一篇由 DeepMind 联合 Stanford HAI(斯坦福以人为本人工智能研究院)共同发布的重磅实证研究报告。这份报告首次对GPT-5的空间智能能力进行了系统性、标准化的全面评估,其结论可能会更加清晰我们对当前AI能力边界的认知。
想想,当一个机器人需要在真实环境中导航、抓取物体或理解空间关系时,它依赖的不仅是视觉识别能力,更是对物理世界的空间理解与推理能力。这种被称为"空间智能"的认知能力,是实现真正人工智能(AGI)的关键却常被忽视的维度。没有空间智能,具身智能体(embodied agent)将无法完全在物理世界中操作、适应或交互。
假设这样一个场景:GPT-5被问及"如果将这张纸按虚线折叠,会形成什么形状?"——这个对5岁儿童来说轻而易举的任务,却让号称最强大的AI模型频频出错。 这不是虚构,而是最新研究中记录的真实案例。随着GPT-5的发布,这一问题变得尤为紧迫:号称最强大AI模型的GPT-5,是否已经攻克了这一基础性难题?基于此,研究团队构建了涵盖六项基础能力的评估体系,在八个最新发布的空间智能基准上测试了约31K图像、4.5K视频和24K问题,总成本超过十亿Token。这一严谨的方法论为回答"GPT-5是否实现空间智能"这一关键问题提供了坚实证据。
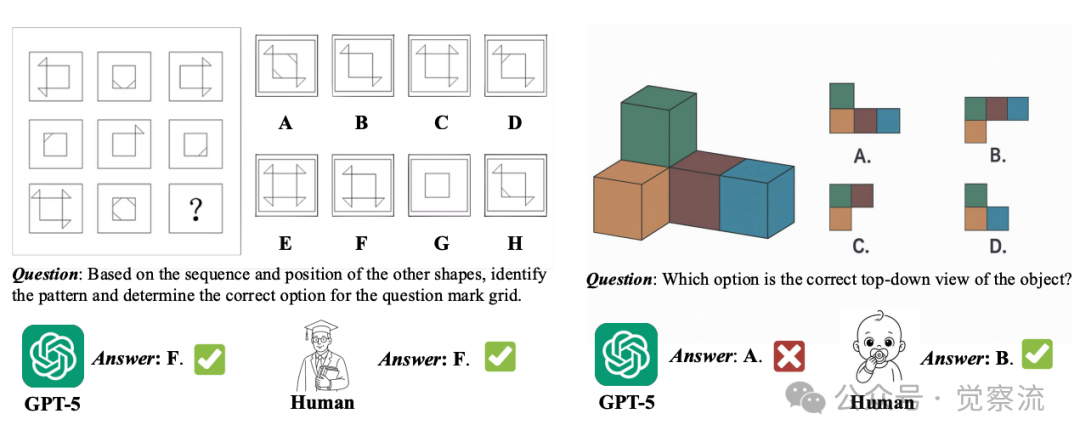
GPT-5在复杂问题与基础空间任务上的表现对比
上图:GPT-5在解决人类认为复杂的问题(左)表现出色,但在人类儿童能轻松理解的基础空间任务(右)上失败。
空间智能——通往 AGI 的"最后一公里"
空间理解与推理构成了一种关键却未被充分探索的智能维度,对实现人工通用智能(AGI)至关重要。正如研究明确指出,空间智能可以说是最未被探索的前沿领域之一。没有空间智能,具身智能体将无法完全在物理世界中操作、适应或交互。
空间智能代表着通往AGI道路上的关键瓶颈。没有强大的空间理解能力,AI系统将仅限于符号操作,而无法真正理解物理世界。研究发现表明,克服这一瓶颈不仅需要扩展现有架构,还需要开发3D表示和推理的根本性新方法。 这提示我们,空间智能的突破可能需要超越当前MLLM范式的创新。
尽管多模态大语言模型(MLLM)近年来取得了显著进展,但即使是当前最先进的模型,在人类认为简单的空间任务上仍频频失败。最新研究表明,空间智能(Spatial Intelligence, SI)是一项根本性不同的技能,与主流基准测量的多模态能力相比具有独特挑战性。
随着GPT-5的发布,整个AI圈自然好奇:它在这一维度上的表现如何?是否已经实现了空间智能?一篇题为《Has GPT-5 Achieved Spatial Intelligence? An Empirical Study》的技术报告首次通过系统性、标准化的实证研究,对这一问题给出了严谨回答。
方法论:构建统一的评估框架
六维能力模型:空间智能的科学解构
现有空间智能评估基准往往关注不同方面,并采用各异的分类体系。为整合这些分散的研究,该论文提炼出六项基础能力,构建了空间智能的统一评估框架:
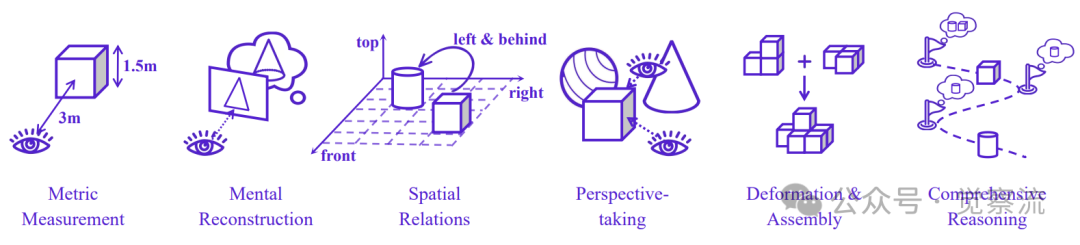
六项空间智能基础能力
- MM(度量测量,Metric Measurement):从2D观察推断3D维度(如度量深度或长度)。由于缺乏相机内参时这一推断本质上是模糊的,合理的估计反映了对物理尺度和典型物体尺寸的理解。
- MR(心理重构,Mental Reconstruction):从一个或多个受限视角推断物体的精细几何结构,要求模型从有限2D观察中推断完整3D结构并有时进行虚拟操作。这类技能赋能现实工程应用,包括解释或生成三视图。
- PT(视角转换,Perspective Taking):理解并推理不同视角之间的关系,包括相机-相机、物体-物体、区域-区域等视角转换。这是具身智能体理解物理世界的基础能力。
- SR(空间关系,Spatial Relations):识别和理解物体之间的空间关系(如"在...上面"、"在...前面"等)。
- DA(形变与装配,Deformation and Assembly):理解物体形状的变形(如折纸)和结构的组装(如积木搭建)。
- CR(综合推理,Comprehensive Reasoning):结合多种空间能力进行复杂推理,如计算被遮挡物体数量、理解多步空间变换等。
这一六维框架将此前碎片化的评估基准整合为系统性科学评估体系,为比较不同模型的空间能力提供了共同语言。图2直观展示了六项能力的层次关系,从基础的MM(度量测量)到高级的CR(综合推理),构成一个递进的能力金字塔。值得注意的是,MR(心理重构)和PT(视角转换)作为中间层能力,是连接基础测量与高级推理的关键枢纽。
严谨的评估协议:避免评估陷阱
研究评估了八项最新空间智能基准:VSI-Bench、SITE、MMSI、OmniSpatial、MindCube、STARE、CoreCognition和SpatialViz。这些基准均在2024-2025年发布,反映了该领域研究的最新进展。
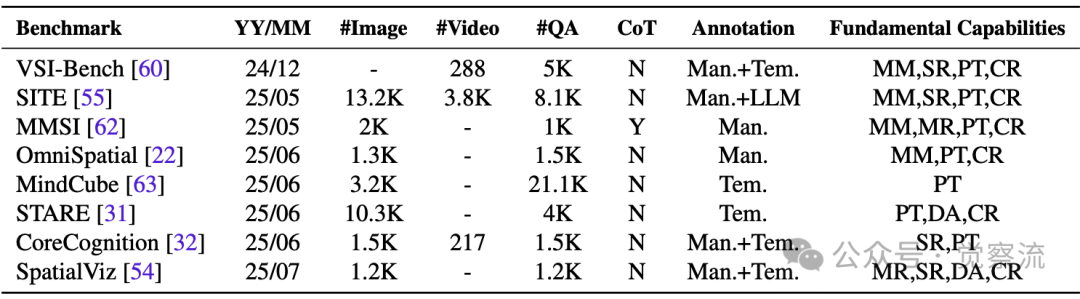
空间智能评估基准的关键要素
为确保评估的可靠性和公平性,研究团队建立了严格的评估协议。包括:
标准化提示(System Prompts):不同基准采用不同的系统提示,而提示对模型性能影响显著。为最大化模型空间推理能力,研究采用OmniSpatial提出的零样本思维链(zero-shot CoT)方法,并遵循SpatialViz指定的答案模板。
Chance-Adjusted Accuracy (CAA)指标:研究采用CAA消除随机猜测的混淆效应,确保评估不受选项数量影响,使不同基准间的结果具有可比性。CAA通过数学公式校正结果,其中是随机猜测的准确率。
答案匹配方法:采用三步匹配流程:1)初始基于规则的匹配:提取"<answer></answer>"标签内的答案;2)扩展基于规则的匹配:若第一步失败,使用额外模式如"<answer>"、"Answer:"等;3)LLM辅助提取:对规则方法失败的情况,使用LLM提取答案。
循环测试(Circular Testing):为确保评估的稳健性,研究团队对所有适用的基准进行了循环测试,通过测量同一图像在多次旋转下的性能,区分真正的空间理解与对答案选项位置的偏见。这一方法揭示了许多模型表面上的空间能力实际上主要归因于识别答案位置模式,而非真正的空间推理。硬循环评分作为更严格的任务能力度量,能有效揭示模型是否真正理解任务,而非依赖选项位置的随机猜测。
MindCube-Tiny的选择:MindCube包含21K问题,但其三个子集(among、around、rotation)分布不均,其中'among'子集包含18K问题。因此,研究采用MindCube-Tiny进行测试,包含1,050个QA对(among:around:rotatinotallow= 600:250:200)和428个独特图像。
评估总计涉及约31K图像、4.5K视频和24K问题,总成本超过十亿Token。这种大规模、标准化的评估为结论提供了坚实的统计基础,避免了小样本评估可能带来的偏差,也克服了不同基准间评估方法差异带来的可比性问题。
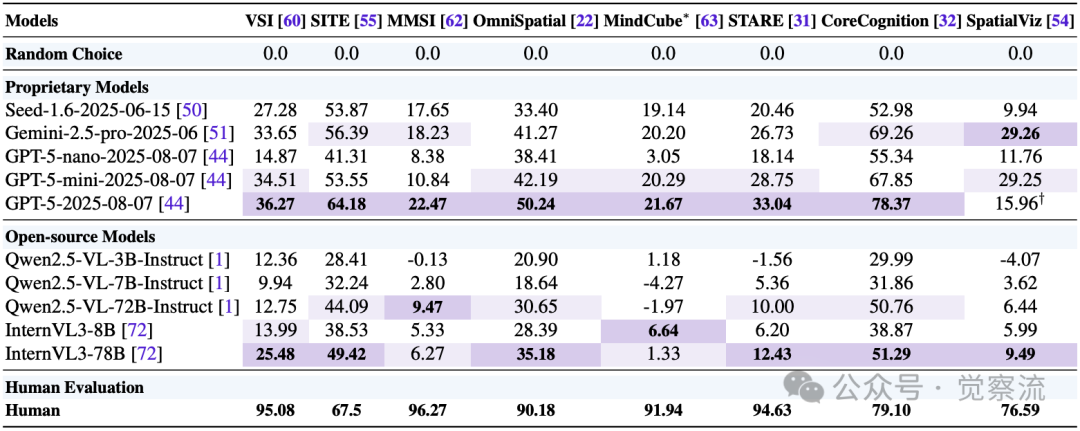
GPT-5与其他模型在空间智能基准测试上的性能对比,展示了其在多数任务上的领先优势,但在某些任务上与人类仍有显著差距。
核心发现:GPT-5 的能力全景与领域共性瓶颈
GPT-5 确立新 SOTA
研究结果显示,GPT-5在空间智能方面确立了新的最先进水平(state of the art),在绝大多数基准上超越了Gemini-2.5-pro和InternVL3等强大基线。它在SITE、MindCube和STARE的大多数子类别中展现出明显优势,同时在其他基准上保持高度竞争力。
在基础几何测量方面,GPT-5展现出前所未有的能力,甚至在某些MM子任务上超越了人类。如附录B.2所示,在VSI-Bench基准中,GPT-5在"物体尺寸"和"房间尺寸"任务上的表现已超过人类水平(人类:47.0和45.9分;GPT-5:50.53和63.73分),仅在"绝对距离"任务上略逊于人类(人类:94.3分;GPT-5:53.61分)。这一突破表明GPT-5可能通过大规模训练获得了强大的几何先验知识,类似于人类依赖典型物体尺寸的启发式假设。
GPT-5在SR任务上也表现优异,在SITE和CoreCognition基准的多个子任务中达到或接近人类水平。例如在SITE的"Counting & Existence"和"3D Information Understanding"任务上,GPT-5分别达到66.45和73.34分,与人类表现(66和83.3分)相当。然而,值得注意的是,SITE是唯一一个报告人类表现约为67.5分的基准,而其他基准的人类表现多在75分以上甚至接近90分,这凸显了跨基准比较的复杂性。
人类性能鸿沟依然显著
尽管GPT-5在空间智能方面取得了显著进步,但研究明确指出,它仍未实现真正的空间智能。在多项基础能力上,GPT-5与人类表现仍有明显差距:
- 心理重构(MR):在8个基准中的3个上表现不佳,特别是在SpatialViz的Mental Rotation和Mental Folding任务上,GPT-5仅得42.50和28.75分,远低于人类的90.00和79.16分
- 视角转换(PT):在8个基准中的6个上存在明显差距,在MMSI、OmniSpatial、STARE和CoreCognition中,PT任务与人类表现之间的差距尤为显著
- 综合推理(CR):在8个基准中的3个上表现欠佳,特别是在MMSI和SpatialViz中,模型在需要多阶段推理的任务上表现薄弱
- 形变与装配(DA):在SpatialViz基准上表现尤其薄弱,Paper Folding任务仅得28.81分(人类98.6分),差距达69.79分
特别是在MMSI这一高挑战性、综合性基准上,即使是GPT-5也远未达到人类水平。MMSI要求模型处理7种类型的视角转换(包括相机-相机、物体-物体、区域-区域等),这种综合性使其成为真正的"压力测试"。在OmniSpatial、STARE、CoreCognition和SpatialViz中,空间智能任务与人类表现之间的差距明显大于非空间智能任务。这表明空间智能任务对当前多模态模型构成了独特挑战。
任务难度决定优势格局:简单任务与复杂任务的模型表现差异
让我们来理解一个非常有意思的发现:AI模型在空间智能任务上的表现并非一成不变,而是取决于任务的难度。
想象一下,如果让AI模型玩不同难度的拼图游戏:
- 简单拼图:只有几块大块,图案清晰
- 复杂拼图:数百块小碎片,图案模糊
研究发现了一个关键规律:在简单任务上,商业闭源模型(如GPT-5)明显优于开源模型;但在真正复杂的任务上,所有模型都表现不佳,看上去差距大大缩小。
为什么会出现这种现象?
这就像让不同水平的学生解数学题:对于基础算术题(简单任务),优等生(GPT-5)能轻松得满分,而普通学生(开源模型)可能得80分;但对于高难度的微积分题(复杂任务),即使是优等生也只能得30分,普通学生得25分——两者的差距从20分缩小到了5分
在空间智能领域,这种现象尤为明显。研究团队测试了多种空间任务,发现:在简单的空间判断任务上,GPT-5等商业模型确实遥遥领先;但在需要综合空间能力的高难度任务上(如理解物体被遮挡的部分、进行多步空间变换等),所有模型——无论是否商业闭源——都表现不佳,且差距很小
一个典型例子:MindCube旋转任务
为了更清楚地理解,让我们看看MindCube的"旋转"任务是什么。MindCube是一个评估空间智能的重要基准测试,它包含三个主要子任务:
- Among(位置关系):判断物体是否在其他物体"之间"
- Around(环绕关系):判断物体是否"环绕"其他物体
- Rotation(旋转判断):判断图像旋转了多少度
在Rotation任务中,模型看到的是同一个物体从不同角度拍摄的图像,需要判断图像旋转了90度还是180度。关键点在于:这个任务中"相机位置固定不动,仅原地旋转",就像你把手机平放在桌上,然后原地转动它拍照,而不是围绕物体走动拍照。
这意味着模型不需要理解空间视角转换,只需判断图像旋转了90度还是180度——就像判断一张照片是正着还是倒着。对人类来说,这太简单了!GPT-5在这一任务上得分高达93.33分,看起来非常出色。
然而,真正的空间智能挑战是这样的:想象你站在房间一角,看到一个物体;然后你走到房间另一角,再看同一个物体。这时,物体在图像中的位置和形状都发生了变化,你需要理解这是同一个物体,只是视角变了。这种需要在脑海中进行视角转换的能力,才是真正的空间智能。
所以,这就像只转动你的头而不移动位置看同一个物体,与实际在空间中移动观察物体有本质区别。
为什么这个发现如此重要?
这一发现对AI研究社区具有重大意义:
- 开源社区的机遇:在空间智能的最前沿领域,开源模型与闭源模型表现相当,这意味着开源社区有平等的机会取得突破
- 研究方向的启示:如果所有顶级模型在最难任务上都表现不佳,说明这不是简单的数据或算力问题,而是需要根本性的方法创新
- 避免误判AI能力:不能因为模型在简单任务上表现好,就认为它真正理解了空间概念
也就是说,任务难度就像一把尺子,能更准确地衡量模型的真实空间智能水平。当任务足够复杂时,那些看似强大的模型优势就会消失,暴露出所有模型共同面临的基础性挑战。
推理深度的双刃剑效应
研究通过消融实验考察了GPT-5的"thinking mode"对性能的影响。在SpatialViz-Tiny测试集上,四种推理模式(Minimal、Low、Medium、High)的结果显示:
- Minimal模式:准确率48.31%,推理token为0
- Low模式:准确率54.24%,平均推理token 1899
- Medium模式:准确率56.78%,平均推理token 5860
- High模式:准确率52.54%,平均推理token 8567(排除超时/截断问题后为68.89%)
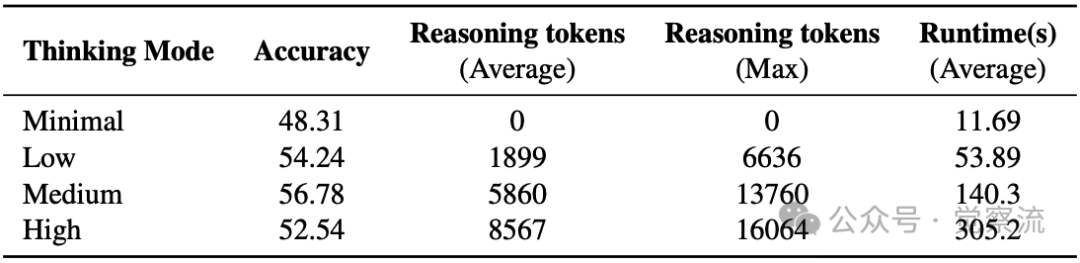
这一结果表明,适度的推理能提升性能,证明了链式推理的有效性。然而,在High模式下,28个问题(占118个测试问题的23.7%)因超过15分钟时间限制或达到token上限而被计为错误,导致准确率下降。这暴露了当前架构在执行长程、复杂空间推理任务时的稳定性缺陷,是导致CR任务表现不佳的重要原因。
这一发现具有重要启示:空间推理不仅需要深度思考,还需要在思考深度与执行稳定性之间取得平衡。当前模型在Medium模式下达到最佳性能,暗示着未来模型设计需要优化推理过程的稳定性和效率,而非简单增加推理深度。
案例分析:GPT-5 的空间认知局限
MR4:心理重构的根本缺陷

MR4:GPT-5在心理重构任务中的失败案例-无法正确推断3D结构的俯视投影
在"根据前视图、侧视图和俯视图重建3D结构"的任务中,GPT-5选择了A,而正确答案是B。该任务要求模型理解3D立方体结构的俯视投影,但模型似乎无法正确推断隐藏面的几何关系。
从GPT-5的思维过程可见,它尝试分析3D结构:

然鹅,它错误地认为"Option A correctly shows green above orange",而实际上在正确答案B中,绿色方块应位于L形结构的顶部角落。
这一错误表明GPT-5未能正确理解立方体堆叠的空间约束——它无法在心理上模拟3D结构的投影变换,仅能进行表面的模式匹配。这种根本性局限揭示了模型缺乏真正的3D心智模型构建能力,无法在脑海中进行动态的空间操作。
PT6:视角转换的根本局限
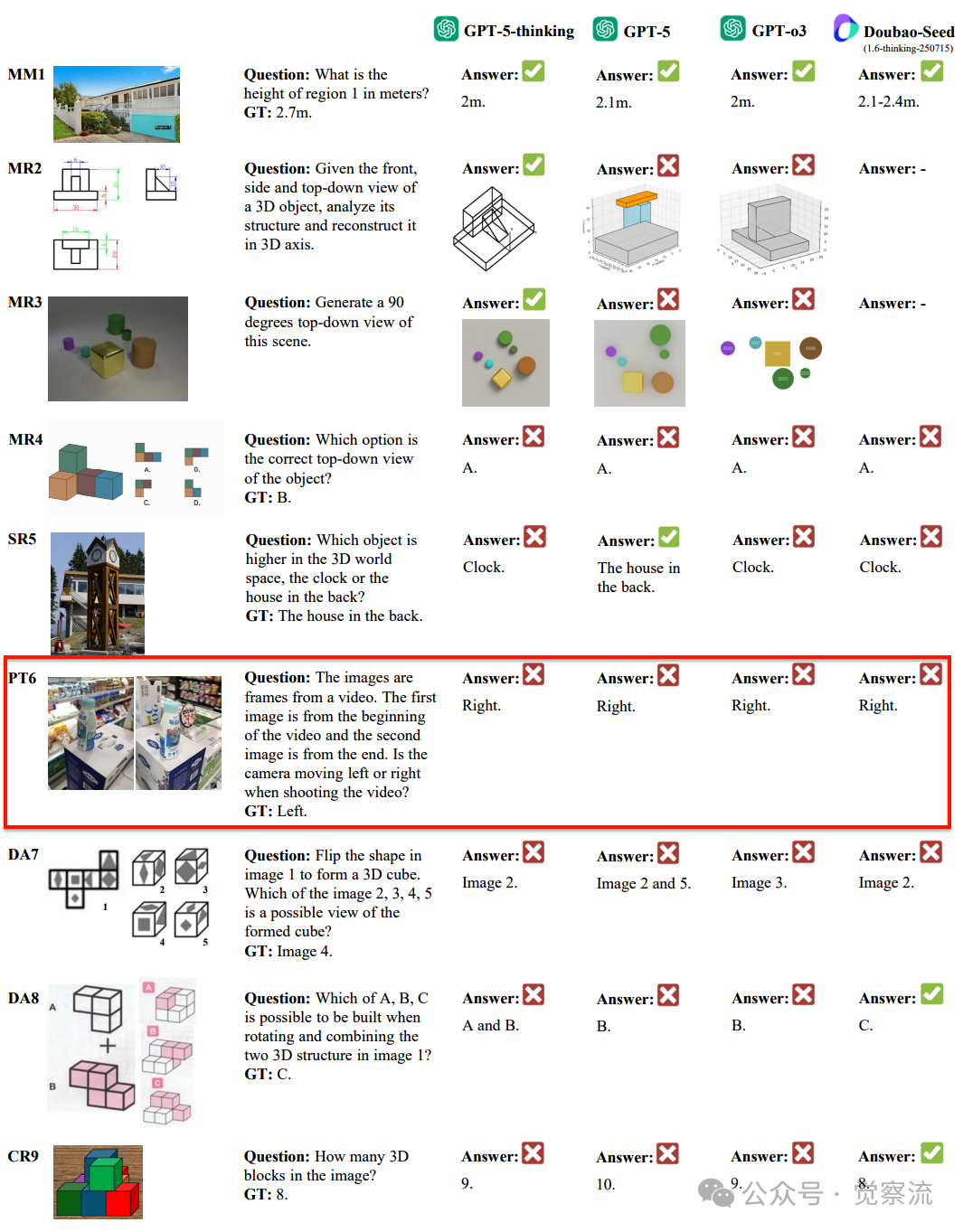
PT6:GPT-5在视角转换任务中的失败案例-误判相机移动方向
在这一任务中,模型需要根据视频前后帧判断相机运动方向。
人类能轻松看出相机向左移动,但GPT-5判断为向右。从其思维过程可见:"In the first image, we see more of the label's left side and a small circle '72'. In the second image, the front label ('每益添') faces more towards us. This suggests the camera moved clockwise to the right, revealing more of the bottle's front."

GPT-5错误地将物体在图像中的相对位置变化解读为相机向右移动,而实际上相机向左移动会导致右侧物体更突出。这与人类的空间推理能力形成鲜明对比——人类能直观理解视角变化与物体空间位置的关系。
DA7/8:形变与装配的认知断层
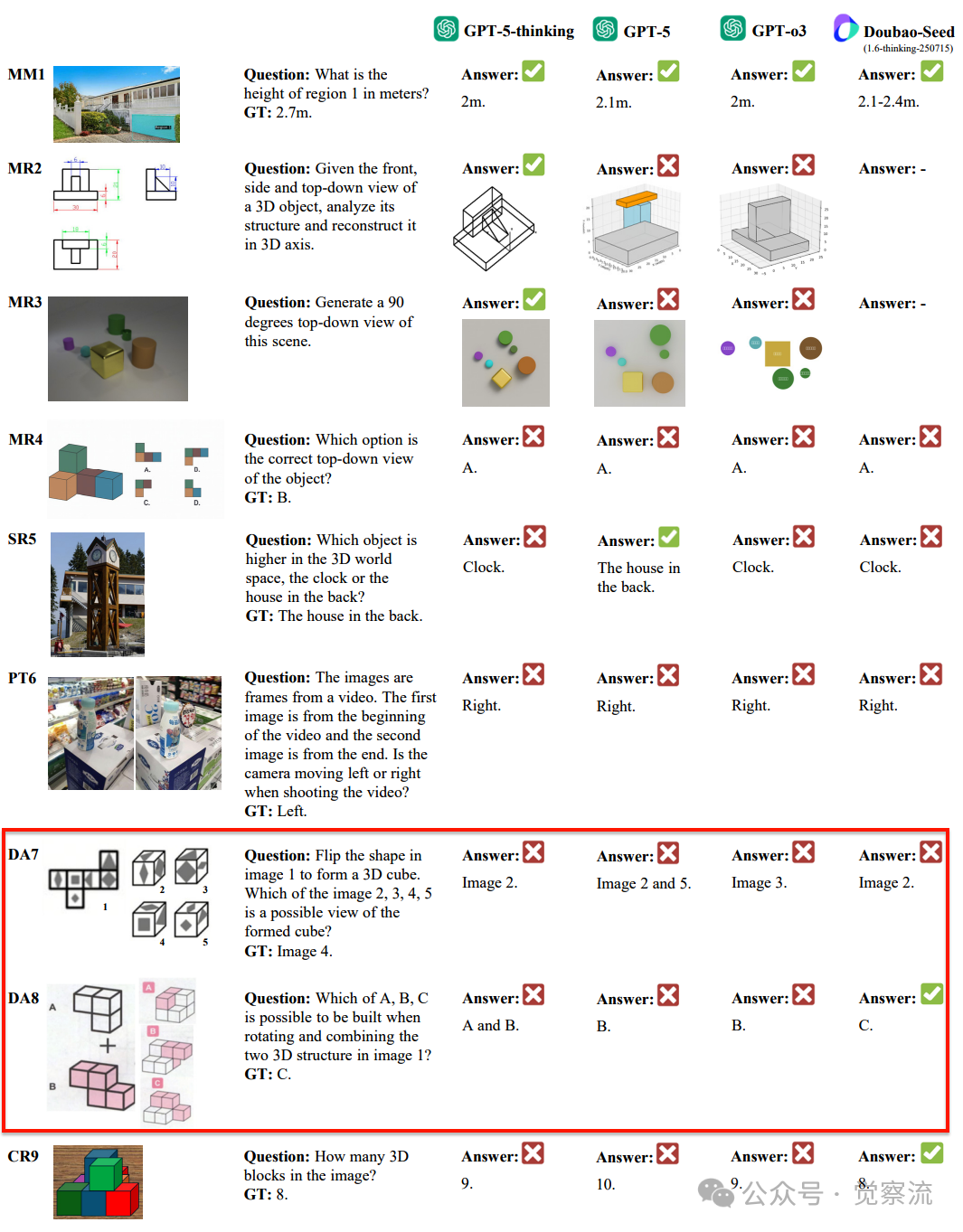
DA7/8:GPT-5在形变与装配任务中的失败案例-折纸与结构组装
在"将2D形状折叠成3D立方体"(DA7)和"旋转并组合3D结构"(DA8)任务中,GPT-5均表现不佳。这些任务要求模型理解形状的变形和结构关系,但模型似乎无法在心理上模拟这一过程。
在DA7任务中,GPT-5选择Image 2而非正确的Image 4。从思维过程可见,它尝试分析折叠过程:"The correct option is the one where the triangle is not mirrored across the pivot edge."

然而,它未能正确理解展开图中各面的空间对应关系,特别是忽略了立方体折叠时相邻面的约束条件。
在DA8任务中,GPT-5错误地认为"Which of A, B, C is possible to be built when rotating and combining the two 3D structure in image 1? Answer: B",而正确答案是C。

这表明模型缺乏对刚体变换和结构约束的深层理解,无法正确模拟3D结构的组合过程。
这些失败共同揭示了一个核心问题:当前MLLMs的根本局限在于无法构建和操作持久的3D心智模型。虽然它们在模式识别和符号推理方面表现出色,但缺乏人类空间智能所具有的动态空间模拟能力。 这种能力缺失使它们在需要具身化认知的任务上表现不佳,而这些任务对人类来说往往是直觉性的。
CR9:综合推理的短板

CR9:GPT-5在综合推理任务中的失败案例-无法推断被遮挡方块
在计算部分被遮挡物体数量的任务中,GPT-5能识别可见方块,但无法推断被遮挡方块的存在。人类能通过空间推理推断出总共8个方块,而GPT-5只识别出9个可见方块(实际应为8个,GT标注为8)。
从GPT-5的思维过程可见,它能够描述可见结构:"I can see nine cubes in the image..."但它未能进一步推理被遮挡部分:"I cannot see any cubes behind the visible ones."

这种局限性表明模型在多阶段空间推理、扩展记忆和逻辑推导方面存在根本缺陷,特别是在需要构建完整3D场景表示的任务上。 这解释了为什么GPT-5在CR9任务中能够识别可见方块,却无法推断被遮挡方块的存在——它缺乏构建完整3D场景表示的能力。
值得注意的是,当提供视觉模拟(VSim)时,GPT-5在STARE的Cube Net任务上表现显著提升(从47.06分提升至88.89分)。这表明适当的视觉辅助能有效弥补模型的空间推理缺陷,也暗示了未来改进方向:结合更强的视觉表示与空间推理能力。
总结:从评估到进化
研究清晰地展示出GPT-5在空间智能领域的全景:在MM(度量测量)和SR(空间关系)任务上,它已接近甚至超越人类水平;但在MR(心理重构)、PT(视角转换)、DA(形变与装配)和CR(综合推理)这四项核心能力上,与人类表现仍有显著差距,特别是在MMSI和SpatialViz等高挑战性基准上。
尤为关键的是,研究揭示了"任务难度决定优势格局"的现象——在最困难的空间任务上,闭源模型并未展现出决定性优势,这为开源社区提供了平等的突破机会。
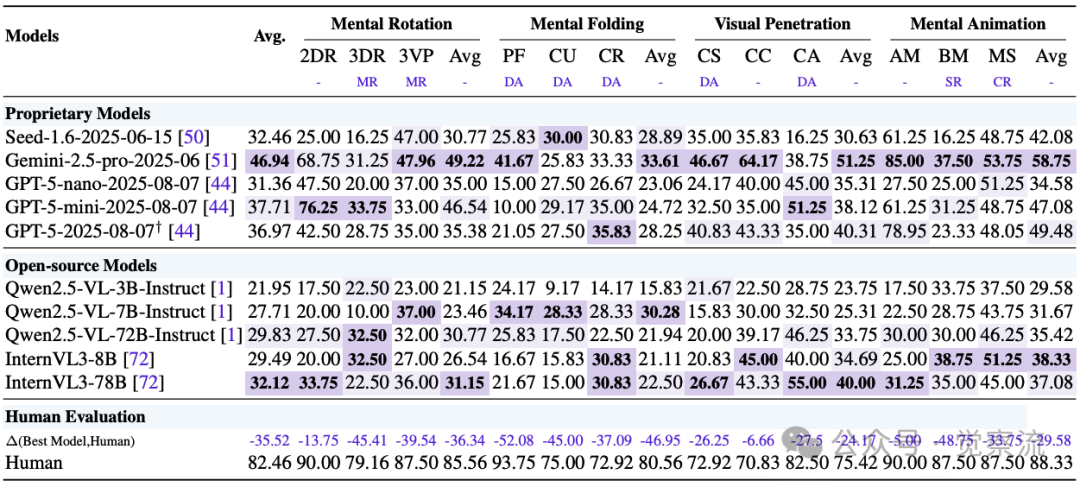 表14 GPT-5在SpatialViz基准上的表现与人类差距
表14 GPT-5在SpatialViz基准上的表现与人类差距
上表:GPT-5在SpatialViz基准上的表现,展示了其在心理重构(MR)、形变与装配(DA)等关键空间能力上与人类的巨大差距,特别是在复杂任务如Mental Folding(人类90.00分 vs GPT-5 28.75分)上。
简而言之,GPT-5在空间智能方面的真实表现可以总结为:
- 它在基础测量任务上表现出色,甚至在某些MM任务上超越人类,表明其已获得强大的几何先验知识
- 但在需要构建3D心智模型的核心任务上,它仍然落后,特别是在心理重构、视角转换、形变与装配和综合推理方面
- 任务难度决定了模型优势:在简单任务上GPT-5领先明显,但在最具挑战性的任务上,所有模型都面临相似的局限
- 推理深度需要平衡:过度思考反而导致性能下降,揭示了当前架构在执行长程空间推理时的稳定性缺陷
这一研究揭示了空间智能领域的几个关键点:
空间智能的根本瓶颈是领域共性难题,而非简单的资源或数据壁垒。研究发现,在复杂的语音识别(SI)任务中,专有模型并没有显示出比开源模型显著的优势。这一发现可能重塑空间智能研究的格局。在MMSI、OmniSpatial、STARE和SpatialViz等最具挑战性的基准上,所有先进模型都面临相似的局限。
任务难度决定了模型优势格局。在低难度任务上,闭源模型优势明显;但在高难度任务上,所有模型都面临根本性挑战。这一发现提示我们,空间智能可能需要超越当前MLLM架构的特定能力,如真正的3D心智模型构建。
推理深度与稳定性需要平衡。GPT-5的消融研究表明,适度的推理能提升性能,但过度推理反而导致稳定性下降。这对未来模型设计具有重要启示:空间推理不仅需要深度思考,还需要优化推理过程的效率和可靠性。
基于这些发现,未来:
开发显式3D心智模型表示:未来研究应致力于在MLLMs中开发显式的3D心智模型表示,使模型能够构建和操作物理世界的内部表征。这需要突破当前架构的限制,实现真正的3D空间表征能力。
设计针对性训练目标:应设计专门针对空间推理能力的训练目标,而非依赖通用多模态训练。这可能包括空间关系预测、视角转换任务和3D结构重建等特定任务。研究表明,通用训练不足以发展出强大的空间推理能力。
整合基于物理的模拟:将基于物理的模拟与空间推理相结合显示出巨大潜力。研究已证明,当提供视觉模拟输入时,GPT-5在Cube Net任务上的表现显著提升(从47.06分提升至88.89分),这为未来研究指明了方向。物理模拟可以作为模型空间推理的"外挂",弥补其内在能力的不足。
采纳标准化评估:研究提出的六维能力框架和公平评估协议为领域提供了重要基础。采纳这些标准将促进可比、可复现和累积性的研究进展,避免"基准过拟合"问题。未来研究应关注任务难度的梯度设计,区分基础能力和高级能力。
这项研究的发现为不同领域的实践者提供了清晰的指引。对于AI研究者,GPT-5在复杂空间任务上的局限表明,单纯扩大模型规模已接近瓶颈,未来的关键在于让模型具备构建和操作3D心智模型的能力。对开源社区而言,研究发现顶尖模型在最难任务上差距不大,这意味着开源项目在空间智能的前沿探索中拥有与闭源模型同等的机遇,创新和协作可能成为突破的关键。对于应用开发者,研究提醒我们,在机器人或AR/VR等依赖空间理解的场景中,不应完全依赖模型的推理能力;引入视觉辅助或简化任务流程是当前更可靠的解决方案。对于所有关注AI进展的人,理解AI在基础空间任务上的这些根本性局限,有助于我们更客观地看待其能力,避免被过度宣传所误导,从而更理性地评估技术发展的现状与未来。
空间智能作为通往AGI道路上的关键瓶颈。没有强大的空间理解能力,AI系统将仅限于符号操作,而无法真正理解物理世界。这项研究最大的价值,在于清晰揭示了AI空间认知的"卡壳点":GPT-5能解复杂的数学题,却搞不定一张折纸;能写文章、编代码,却数不清被遮挡的方块。这种反差表明,AI智能并非单一维度,而是由多个能力模块组成的拼图。当前AI在语言和知识领域已堆砌得很高,但空间认知能力仍显薄弱。
问题的核心在于:当前MLLM的根本局限是无法构建和操作持久的3D心智模型。虽然它们在模式识别和符号推理方面表现出色,但缺乏人类空间智能所具有的动态空间模拟能力。它们更像是"猜"答案而非"想"出答案,没有能在脑海中反复操作、推演的"3D小模型"。
然而,这一局限也带来了希望:当任务难度达到最高时,闭源与开源模型的差距显著缩小,所有模型都面临相似的挑战。这表明空间智能的突破不在于算力堆砌,而在于创新性的架构设计。这为研究社区提供了公平的竞技场,无论资源多寡,都有机会在这一关键领域取得突破。
未来的突破点可能在于三个方向:开发显式的3D心智模型表示、设计专门针对空间推理的训练目标,以及整合基于物理的模拟。特别是当视觉模拟与空间推理结合时展现出的巨大潜力(如Cube Net任务中从47.06分提升至88.89分),提示我们物理模拟可作为弥补模型内在能力不足的有效"外挂"。
当AI能够像人类一样自然地理解并推理物理空间时,它将不再仅仅是信息处理工具,而成为能在现实世界中自如行动的智能伙伴。跨越空间智能这一关键障碍,或许是通往真正AGI的必经之路。这项研究不仅评估了当前技术的边界,更为未来研究铺设了道路——当AI能够真正理解并推理物理世界时,它将开启人机协作的新时代。