GPT-5比人类医生还会看X光片?!
最新研究显示,GPT-5对医学影像的推理和理解准确率分别比人类专家高出24.23%和29.40%。
 图片
图片
来自埃默里大学医学院的研究团队把GPT-5和GPT-4o以及更小的GPT-5变体(GPT-5-mini、GPT-5-nano)进行了比较,分析它们在医疗领域处理多模态信息的能力。
 图片
图片
通过一系列标准化测试发现GPT-5在所有测试中的表现都比其他模型好,尤其是在MedXpertQA的多模态测试中,它的推理和理解得分比GPT-4o分别提高了近30%和36%,甚至比人类医生还高。
 图片
图片
AI看病历常见,可是比人类医生还会看就不常见了,所以GPT-5是怎么做到的?
AI在多模态医学领域超越人类新手医生
研究人员对GPT-5、GPT-4o以及GPT-5的mini和nano版本进行了系统测试。
测试分为三类:纯文本的USMLE考试、多模态的MedXpertQA测试还有放射科的VQA-RAD,都是零样本设置,不依赖数据微调。
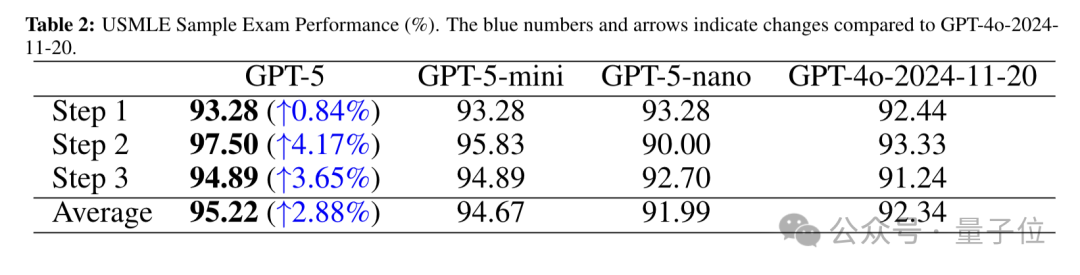
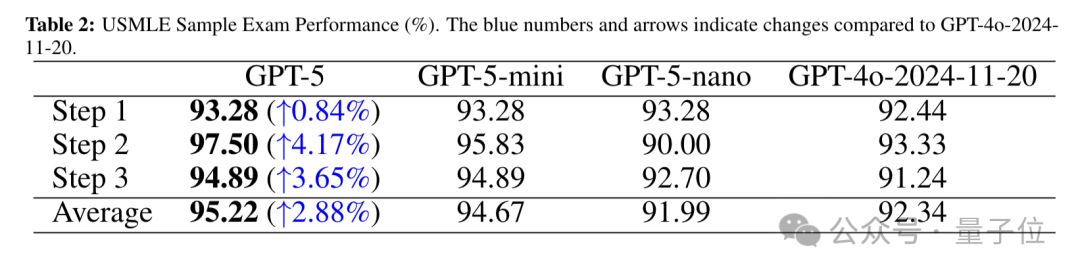
USMLE是美国医师执照考试,有标准化的命题和严格的评分体系,是全球医学教育和人才评估的重要参考基准。
该考试分为三个步骤:Step1主要考察基础医学知识,Step2聚焦临床应用知识,Step3侧重实践。
在此次研究中,GPT-5在USMLE考试中全面超越GPT-4o,且平均得分领先于其他模型。
 图片
图片
MedXpertQA测试是一个用于评估模型专家级医学知识与高级推理能力的综合基准,有文本测试和多模态测试,共涵盖4460道题目,涉及17个医学专科和11个身体系统,其数据源自超20个美国医师执照考试、欧洲放射学委员会考试等权威内容。
其中多模态的MedXpertQA测试利用它的MM子集展开,MM子集引入了带有多样化图像及丰富临床信息(病历、检查结果等)的专家级考试题。
为增加难度,多模态子集的题目还扩充至5个选项,能更有效地评估模型在贴近真实场景下的医学诊断推理能力。
依据之前的数据,GPT-5推理和理解得分比GPT-4o分别提高了近30%和36%。
 图片
图片
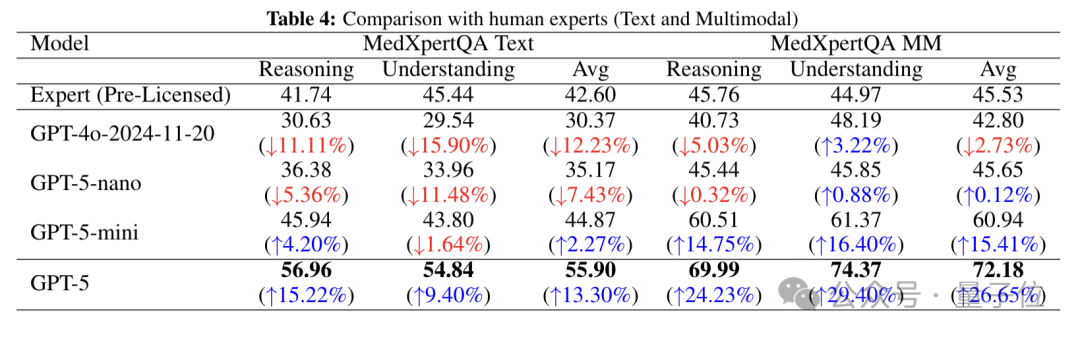
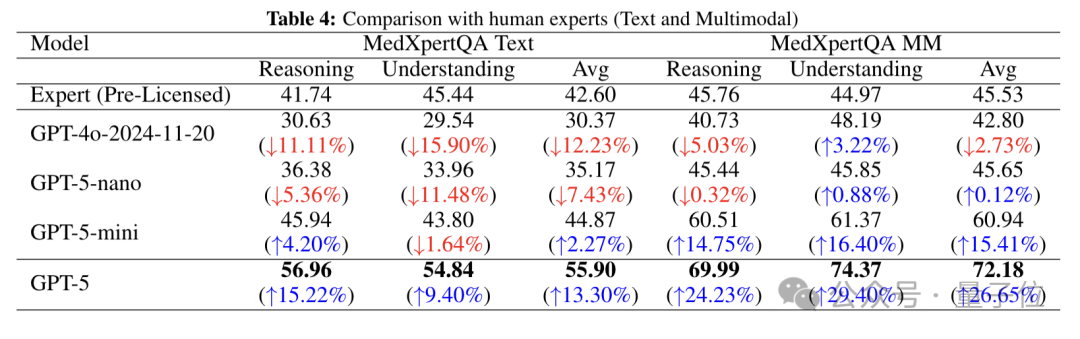
下图详细对比了未取得执照的人类专家与GPT-5系列模型及GPT-4o在MedXpertQA测试的文本子集(Text)和多模态子集(MM)中的表现,涵盖推理、理解及平均三个维度。
 图片
图片
在文本测试中,GPT-4o三项得分均低于人类专家,GPT-5-nano同样全面落后,GPT-5-mini 推理和平均得分略超人类专家,而GPT-5表现最优,得分大幅领先。
在多模态测试中,GPT-4o推理和平均得分略低,GPT-5-nano整体与人类专家持平,GPT-5-mini大幅超越人类专家,GPT-5优势最为显著,推理超人类专家24%、理解得超人类专家29%,展现出强大的多模态医学推理能力。
VQA-RAD测试是医学视觉问答测试,该数据集包含315张放射影像以及与之对应的3515个问答对。常用于评估医学多模态大语言模型解读复杂医学图像并生成准确文本描述的能力。
在此次研究中,GPT-5的匹配率为70.92%,高于GPT-4o及小变体GPT-5-nano,而其轻量化变体GPT-5-mini的表现略优,严格匹配率达到74.90%。
 图片
图片
考虑到VQA-RAD规模相对较小且具有放射科专项属性,这种得分差异可能源于较小模型存在数据集特定的过拟合现象。
看了这么多测试结果,那么GPT-5为什么能全面碾压前辈GPT-4o呢?
GPT-5构建了端到端的多模态架构
团队认为,GPT-5能力提升核心源于其跨模态注意力与对齐能力的增强。
GPT-5与GPT-4o的核心差距,本质上是从文本主导的混合处理到原生多模态深度融合的代际跨越。
GPT-4o在处理跨模态任务时,仍依赖文本转译+外部工具调用的间接模式:例如解析医学影像时,需先通过第三方模型将图像信息转化为文本描述,再基于文本进行推理。
这种模态转换中介不仅增加了信息损耗(如图像中的细微病变可能在转译中被忽略),还导致推理链条断裂——模型难以直接建立影像特征-病理机制-治疗方案的因果关联。
而GPT-5构建了端到端的多模态架构:通过共享标记化技术,将文本、影像、音频等信息编码为统一向量空间的符号,再借助跨模态注意力机制实现感知-推理-决策的无缝衔接。
并且,团队认为在MedXpertQA Text、USMLE Step 2这样的推理密集型任务中,GPT-5的进步更突出是因为思维链提示与GPT-5增强的内部推理能力形成了协同效应,使其能更准确地完成多步推理。
不过研究人员也指出,尽管GPT-5在标准测试中表现优秀,但要说明的是,这些测试都是在理想环境下进行的,题目和数据都是标准化的,现实中患者的情况千奇百怪,还可能遇到各种突发状况。
所以,GPT-5要真走进诊室当助理,还得经过更多实战考验。
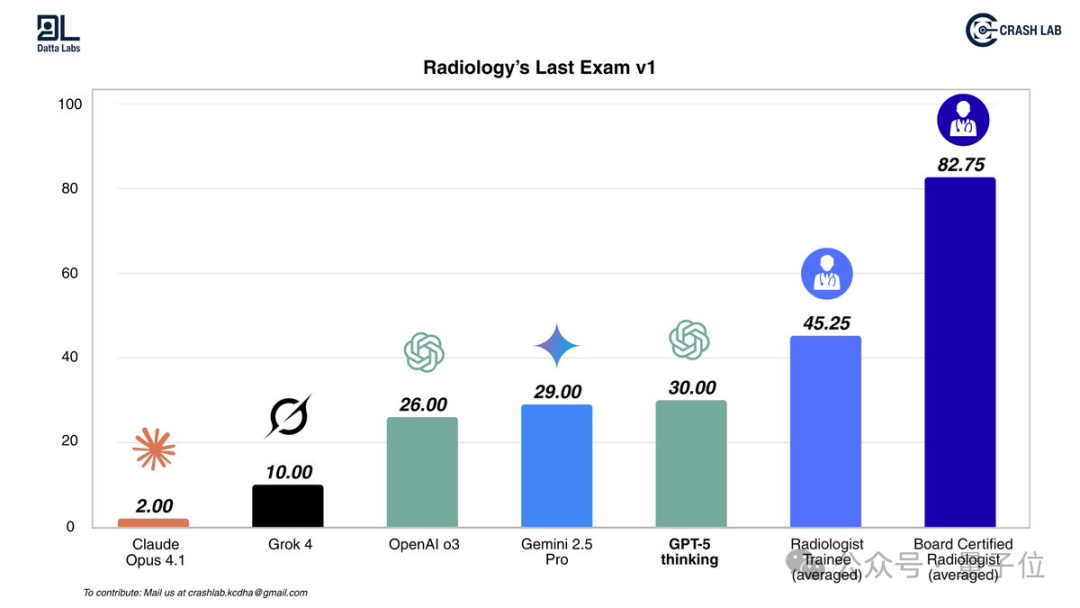
这不,KCDH_A数字健康研究中心对AI进行了放射科的终极考试,这是一项AI从未见过的、跨模态的检测任务,涵盖了CT、MRI和X光,模拟日常实践中实际遇到的复杂真实病例。
测试结果显示,所有AI模型得分均低于实习医生,而拥有执业资格的放射科医生比AI领先更多,虽然GPT-5刚刚进入顶尖AI的位置,但也远低于人类。
 图片
图片
该实验室的研究人员表示:
虽然我对AI发展感到兴奋,我们实验室也在每天使用AI模型,但AI取代放射科医生与现实的差距仍然很大。
由此可见,AI独自看病历之前,还是得先磨练磨练。
论文地址:https://arxiv.org/abs/2508.08224
参考链接:
[1]https://x.com/omarsar0/status/1955252499142627788
[2]https://x.com/emollick/status/1955381296743715241
[3]https://x.com/DrDatta_AIIMS/status/1954586822849523789