Google 今日宣布,Gemini 2.5 Pro 与 Gemini 2.5 Flash 现已进入稳定状态并全面上线。同时,Google 还推出了全新的 Gemini 2.5 Flash-Lite(预览版) ——这是目前最快、最具成本效益的 Gemini 2.5 模型。
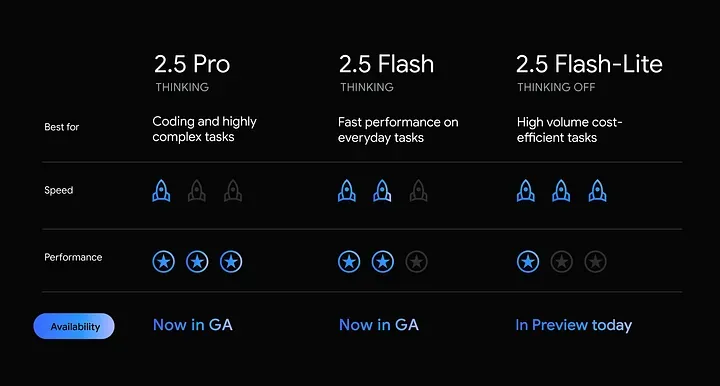
Gemini 2.5 Pro(稳定版)
- 推理能力增强:模型具备“思考预算”机制,可在响应前先进行“思考”,提高整体准确率,尤其在数学与科学类基准测试中表现优异。
- 原生多模态处理能力:支持文本、图像、音频、视频等输入输出,并按格式计费。
- 上下文窗口扩大至 100 万 token:适用于长文档处理与多轮对话。
- 原生音频(预览):支持实时语音输出,可在 24 种语言间自然切换,并具备语气控制、环境噪音过滤能力。
- 高级代码能力:在 Web 开发相关任务中表现突出,在 WebDev Arena 等基准测试中得分领先。

- 工具调用能力:支持实时信息访问、代码执行、结构化输出、函数调用、搜索增强等功能。
Gemini 2.5 Flash(稳定版)
- 价格优化:输出 token 成本从 降至2.50 /百万,输入成本略升至 $0.30 /百万。
- 统一计价模型:取消了“思考”与“非思考”之间的计费区分,简化开发流程。

Gemini 2.5 Flash-Lite(预览版)
- 主打速度与低延迟:相比旧版 Flash 模型,Flash-Lite 提供更快响应、更低首 token 延迟。
- 默认关闭思考模式:以压缩成本为优先,开发者可通过 API 参数开启推理模式。
- 支持核心工具能力:包括代码执行、搜索增强、URL 上下文引用、函数调用等。
- 适合场景:高吞吐量任务,如文本分类、摘要、轻量对话系统等。
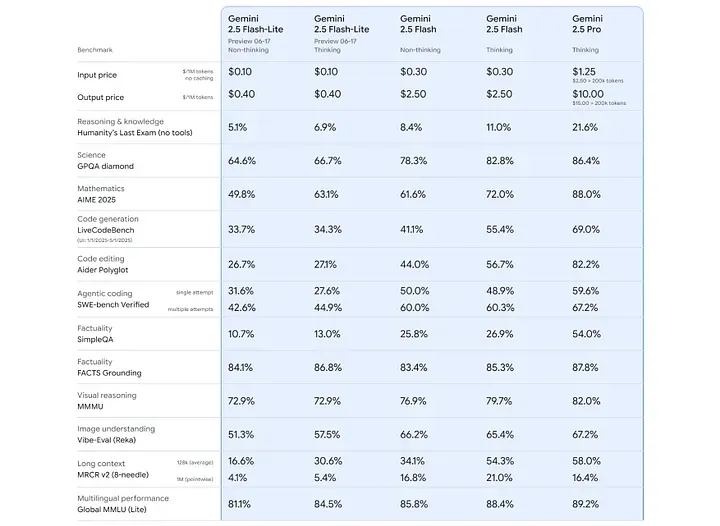
性能对比(思考 vs 非思考模式)
任务类型 | Flash-Lite 非思考 | Flash-Lite 启用思考 |
数学推理 | 49.8% | 63.1% |
编码能力 | 33.7% | 34.3% |
长上下文处理 | 16.6% | 30.6% |
图像理解与多语言任务 | 普通表现 | 明显提升 |
简单摘要/分类任务 | 84.1% | 86.8% |
对于性能敏感型项目,可默认关闭推理,以获得最大吞吐率;在需要更高准确率场景下再开启推理模式,实现灵活折中。
如何访问 Gemini 2.5 模型?
途径一:Gemini Chat App
在左上角模型选择器中可切换至 2.5 Pro 或 2.5 Flash 模型使用。
途径二:Google AI Studio
可自定义温度、思考模式、预算等高级参数,适合开发者调试及部署。
途径三:Google Vertex AI API
通过 Vertex AI 提供的 API 接口接入 Gemini 2.5 系列模型,支持 CLI 或 Python 等方式调用。
示例(Python 接入 Gemini 2.5 Pro):
复制from google import genai
from google.genai import types
client = genai.Client(vertexai=True, project="YOUR_PROJECT_ID", locatinotallow="global")
response = client.models.generate_content(
model="gemini-2.5-pro",
cnotallow=[
"What is shown in this image?",
types.Part.from_uri(
file_uri="gs://generativeai-downloads/images/scones.jpg",
mime_type="image/png",
),
],
)
print(response.text)开发者注意事项
- Gemini Pro Preview 05–06 将于 2025 年 6 月 19 日下线;
- Preview 06–05 用户需更新模型 ID 至 "gemini-2.5-pro";
- 建议升级旧版 Flash 1.5/2.0 用户至 Flash-Lite,以获取更快速度与更优性价比。
小结
Gemini 2.5 的发布表明 Google 正在持续加码生成式 AI 模型的产品化与实用化。无论是 Pro 版本的推理能力与多模态支持,还是 Flash-Lite 的极致效率,在 AI 工具开发者社区中都具有广泛应用潜力。
开发者可根据自身项目需求,在 Pro 深度推理能力与 Flash-Lite 高吞吐性能之间做出灵活选择。


