从AI技术维度分类,大约可以将LangExtract归为RAG框架,但从细处分辨,二者实有比较明显的区别。RAG的关注重点是检索,LangExtract的重点则如其名,是对数据的提取,且主要针对非结构化文本数据进行结构化提取。
LangExtract官网对它的介绍为:“一个使用大语言模型从非结构化文本中提取结构化信息的 Python 库,具备精确的源定位和交互式可视化功能。”提取结构化信息是其核心功能,而其亮点则是能够提供精确的源定位,并完成交互式的可视化呈现。
之所以能提供精确的源定位,在于LangChain并没有使用embedding的机制通过向量进行相似度计算和检索,而是采用了一套精巧的确定性文本对齐算法:“首先通过指令让LLM返回原文片段,然后利用WordAligner进行多层次匹配——从精确字符串匹配到模糊相似度计算,但始终避免了基于向量embedding的模糊对齐。”
例如,运行官方提供的医疗文本的提取代码,可得到如下结果:
复制结果清晰给出了提取的实体在文本所处的位置。在生成的jsonl文件中,以Dosage为例,输出的结构化数据为:
复制其中的char_interval属性值就是提取结果在原文中的位置,很好地体现了它的溯源能力。
完成提取后,LangExtract会自动生成一个HTML文件,打开网页能够看到提取结构的一种交互式可视化呈现:
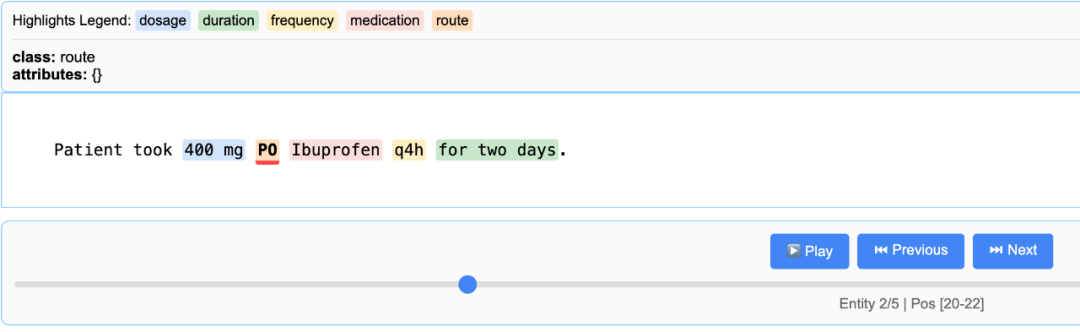 图片
图片
虽说LangExtract官网将其定位为“Gemini 驱动的信息提取库”,这大概是为了配合Google大模型的宣传手段,但它显然不会愚蠢得仅支持Gemini模型。事实上,它可以支持任何LLM,即便官方没有提供支持,也可以自定义模型的Provider。事实上,前面输出的结果使用的模型是我通过Ollama在本地部署的lamma3:7b模型:
复制复制除了受控生成技术,LangExtract还通过运用“少样本”示例尽可能确保结果的稳定性:
复制复制虽然LangExtract完全可以精确提取超长文本的高价值信息,却是以消耗极高的token数量为代价,因此在生产使用时,必须考虑时间成本、基础设置的资源成本以及算力成本。就以官方使用的《罗密欧与朱丽叶》为例,整个提取操作会消耗约44000 tokens。而这个所谓的长文本,其实还不到3万个单词。
我在本机尝试使用lamma:7b的LLM对《罗密欧与朱丽叶》的文本进行提取,运行没有多久,CPU就开始疯狂运转,不断散发热量,风扇开始卖力的工作,结果没等执行完毕,就抛出了ResolverParsingError错误。我将LLM切换为更匹配LangExtract的gemma2:9b大模型,仍然出现同样错误。显然,真要让LangChain为大量非结构性文本提供精确的提取服务,背后需要更好的LLM和更强大的算力支持。
另一个不足之处在于LangExtract目前仅支持文本字符串作为文本源,一些常见的文本文档文件,如PDF、DOCX,暂时都不支持。当然,社区已经看到了这一问题,目前作为Proposal的Issue提交到了LangExtract的Issue列表中。
无论如何,LangExtract为我们处理非结构化文本提供一个不错的选择。


