LRM通过简单却有效的RLVR范式,培养了强大的CoT推理能力,但伴随而来的冗长的输出内容,不仅显著增加推理开销,还会影响服务的吞吐量,这种消磨用户耐心的现象被称为“过度思考”问题。
针对这一缺陷,来自美团等机构的研究团队提出可验证的过程奖励机制(VSRM),鼓励CoT中的“有效步骤”,惩戒“无效步骤”,最大限度保持性能的同时,实现高效推理。

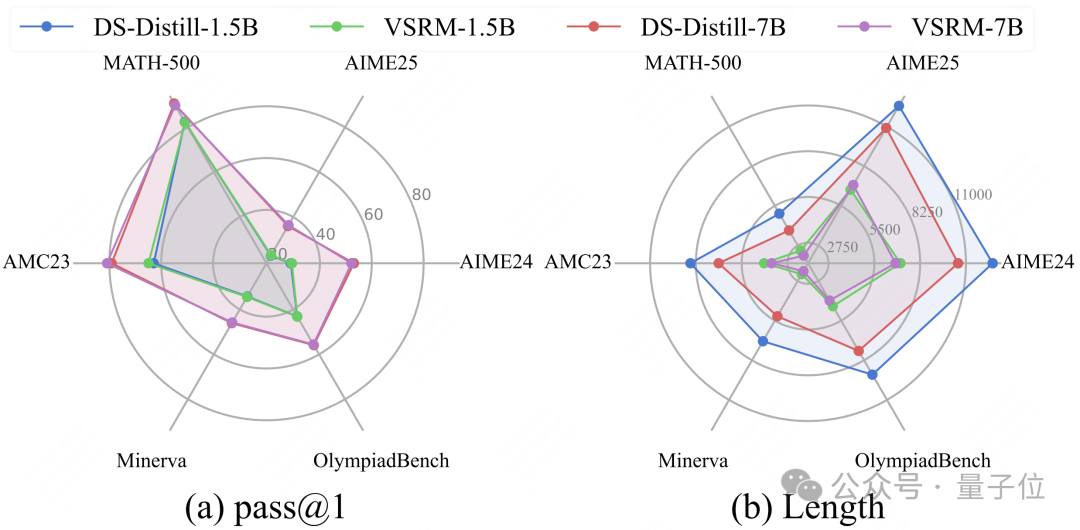
通过在数学任务上的实验显示,在多个常用benchmark上,VSRM加持的后训练使得不同尺度的模型实现了输出长度的大幅缩减,甚至在部分情况下提升了模型表现。
过度思考问题的本质
此前的工作将过度思考问题的现象总结为:对于一个问题,模型倾向于给出多种不同的解答,特别简单的问题。在这一认识的基础上,作者团队更进一步,对现有LRM在MATH-500上做出的回复进行了深入的case study。

如图所示,在这个例子中,模型为解决一个非常简单的子问题([-500,0]中有多少个小于0的整数)进行了反复的思考,在正确和错误之间反复横跳,最终得出了一个不正确的中间结论,进而导致了最终结论的错误。
这些无效步骤不但不能指引推理路径的发展,反而会导致中间过程出错。
这样的案例并不孤立,甚至频繁出现。
基于上述观察,作者团队提出:大量无效的中间步骤是导致模型过度思考的根本原因。因此,抑制这些无效步骤,鼓励有效步骤,是后训练的核心优化目标。
设计可验证的逐步骤奖励
现有RLVR的机制,通过奖励函数以可验证的二元结果奖励促进模型探索能够获得正确答案的解法。
但是结果奖励无法精确地奖惩不同的步骤,也因此无法达到作者所期望的目标。
过程奖励机制虽然能满足这一要求,但过程奖励模型(PRM)往往难以训练且预测结果的可靠性有限,针对数学问题/代码编程等推理任务更是严重欠缺可解释性。
作者团队将可验证奖励与步骤级奖励结合在一起,创造性地提出VSRM,为推理过程中的每个中间步骤分配奖励信号,从而实现对不同步骤的鼓励和抑制,天然地契合推理任务分步作答的特点。
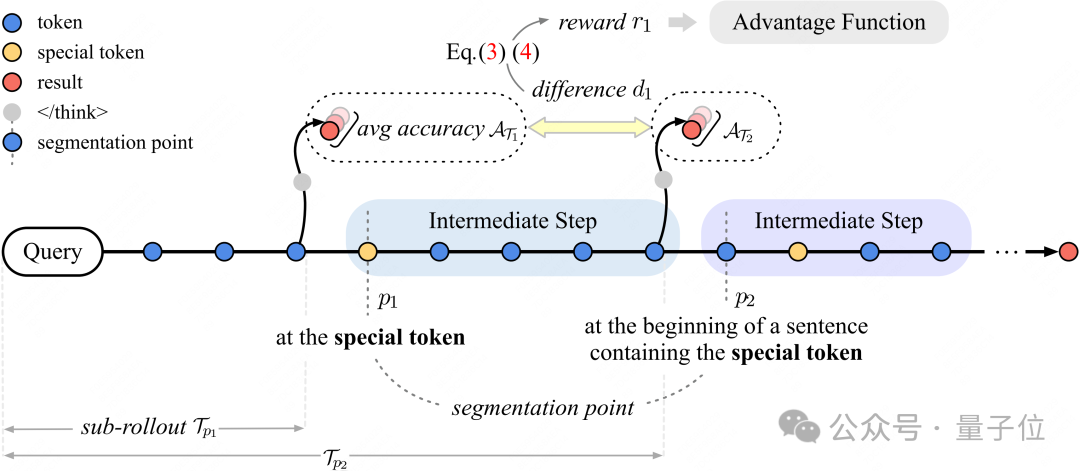
引入步骤级奖励的第一步是定位所有的步骤。
在CoT中,一些特殊的token,比如“However”、“Therefore”、“So”、“But”、“Wait”等往往表示模型已经完成了一个推理步骤,即将进行下一步推理(递进或是转折)。这些特殊token的存在将整个轨迹划分成了多个中间步骤。
为了保证划分后内容的可读性,作者额外设计了三条规则:1. 跳过最初的若干token,这部分内容往往是对问题进行重述。2. 相邻划分点之间必须至少间隔一定距离,避免过度分割。3. 若特殊token位于句子内部,将划分点放在该句句首。
为了评估中间步骤有效与否,最直接的方式就是评估该步骤完成前后带来的正确率增益。而正确率是完全可以通过可验证的方式得到的。
只需要在每个划分点的位置前,加上一个token,这样,从query开始,到该处的,就构成了一条子轨迹。以每个子轨迹为prompt,模型能够产生多个候选答案,平均正确率体现了当前步骤得到正确答案的概率。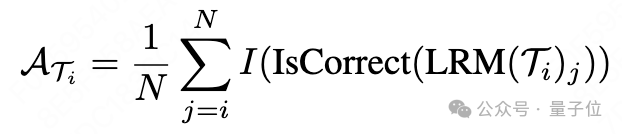
相邻子轨迹的正确率差值,即为完成当前步骤后获得的正确率增益。
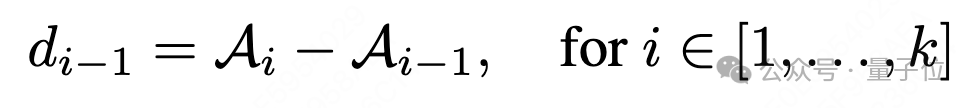
直接将增益作为步骤级奖励就能够指导模型区分有效与无效步骤。但考虑到,往往若干个步骤才能够导致解题过程的实质性推进,因此,多个连续步骤的平均正确率很可能保持不变,进而导致稀疏的奖励信号,不利于优化。
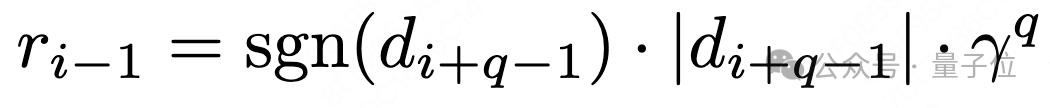
为了避免这种情况,作者引入一个前瞻窗口机制,将未来的正确率变化通过折扣因子传播给当前步,从而确保奖励信号尽量密集。
通过这种机制,VSRM机制实现了为每个步骤分配可验证的,步骤级奖励信号,从而鼓励模型减少无效步骤的输出。与直接施加长度惩罚不同,VSRM直接从源头上给予模型最清晰明了的奖励信号,引导模型更多选择对提升最终正确率有帮助的步骤,在缓解过度思考问题的同时,最大限度地保留模型性能。
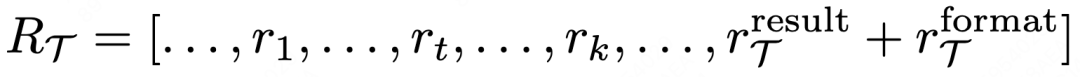
VSRM机制本身与强化学习算法解耦,能够天然地适配支持过程奖励的方法,只需将逐步奖励添加到最终的reward tensor即可,搭配常用的结果二元结果奖励和格式奖励,即可无缝实现高效推理。
实验结果
作者在数学问题最常用的benchmark上,使用三个不同base model,两种RL算法,将VSRM与多种最新的相关工作进行对比,实验结果展现出VSRM在降低输出长度的同时,能够最大限度地保持性能,取得很好的均衡。
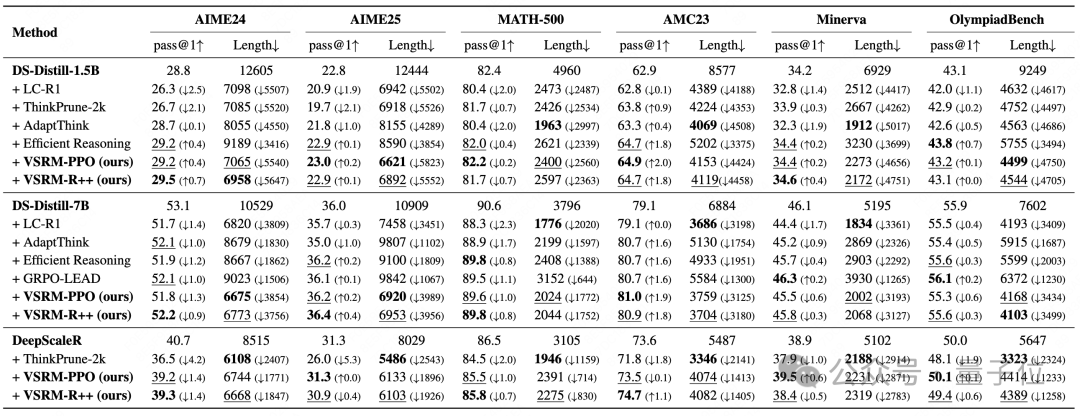
消融实验的结果显示了VSRM中,前瞻窗口机制的有效性,以及,额外的显式长度惩罚对于VSRM机制并无帮助。

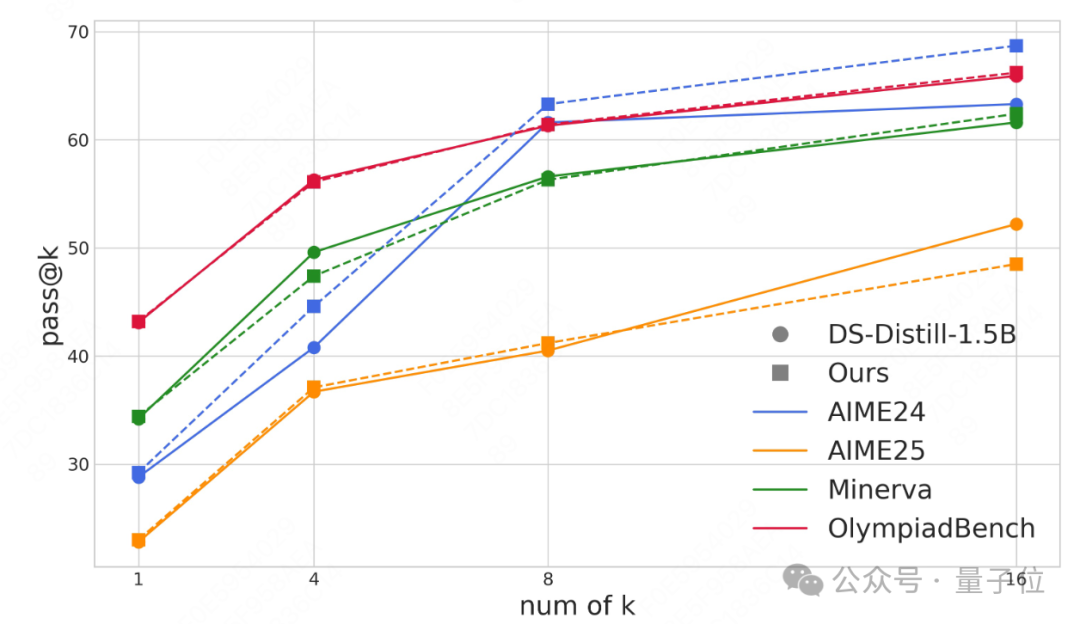
在困难benchamrk上,随着k的增加,Pass@k指标的提升趋势能够反馈模型探索更多可行解的能力。可以看到VSRM-PPO训练后的模型,体现了与原本模型一致的趋势,说明模型并没有因为输出长度的压缩而失去了最重要的探索能力。
总结
通过广泛的对比实验,作者证明了可验证的过程奖励在不同RL算法,不同base model的设置下,均能实现保持性能的同时,极大缓解过度思考问题。消融实验以及进一步的实证分析也展示出,可验证的过程奖励,真正起到了抑制无效步骤,鼓励有效步骤的作用,是从根本上解决过度思考问题,保持模型良好推理行为的有效途径。
论文链接:https://arxiv.org/abs/2508.10293项目链接:https://github.com/1benwu1/VSRM-Efficient-LRMs


