
大家好,我是肆〇柒。今天,我们不聊技术的表象,而是探讨一个正在重塑软件开发未来的核心议题。这篇深度解析,源自英国利兹大学(University of Leeds)的综述《AI Agentic Programming: A Survey of Techniques, Challenges, and Opportunities》。他们系统性地梳理了AI编码智能体的技术谱系,并犀利地指出:我们今天的编程工具,都是为人类设计的,这正是阻碍AI智能体真正落地的“元挑战”。
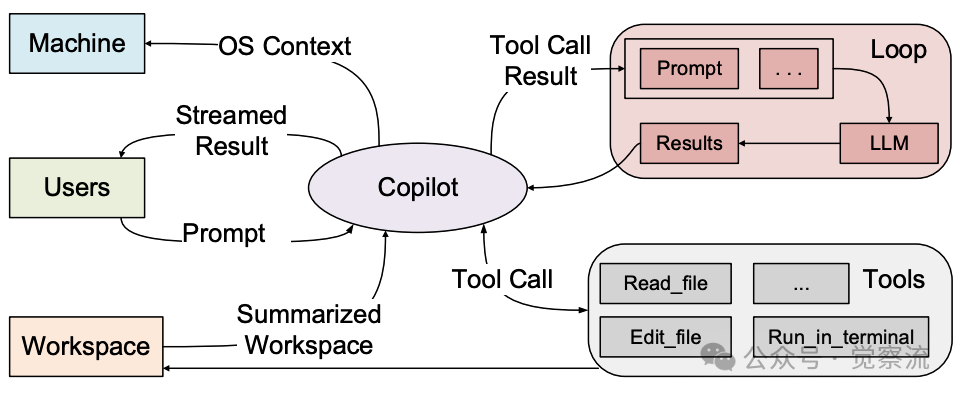
一个AI编程智能体的典型工作流程
在当下的软件开发领域,一个令人振奋的现象就是:最先进的AI编码智能体(如Devika、OpenDevin)已经能够连续工作数小时,自主完成从代码生成、测试到调试的复杂任务链。这些系统不仅能够理解自然语言指令,还能与编译器、调试器和版本控制系统等工具交互,通过多轮迭代逐步完善代码,展现出前所未有的自主能力。某些前沿系统甚至能在避免死锁、维持任务一致性的同时,从失败操作中恢复,持续推动开发进程。
然而,一个关键问题摆在眼前:尽管这些技术演示令人印象深刻,为何AI编码智能体尚未大规模进入企业级生产开发流程?"能做"与"可信"之间为何存在巨大鸿沟?究其原因,AI Agentic Programming 的成功不仅取决于LLM(Large Language Model)的智能水平,更取决于其安全性、可评估性、人机协作性等"非功能性"属性。而这些挑战的深层根源,往往在于一个被忽视的事实:我们今天的编程语言、编译器和调试器,都是为人类开发者设计的,而非为AI智能体。这种根本性的错配,正成为阻碍其规模化应用的"元挑战"。
智能体能力谱系:理解技术现状
在深入探讨挑战前,有必要理解AI编码智能体的能力谱系。AI编码智能体可根据行为特征分为四类维度:反应性vs主动性(如GitHub Copilot仅响应提示,而Claude Opus 4能主动规划子任务)、单轮vs多轮执行(能否维持状态进行迭代)、工具增强vs独立智能体(是否集成外部工具)以及静态vs自适应(能否根据反馈调整策略)。这些差异直接影响智能体处理复杂任务的能力。
工具增强vs独立智能体这一维度尤为关键:工具集成使智能体能够执行"计划-执行-验证"的闭环工作流,通过与编译器、调试器等工具的交互获取真实反馈,从而避免LLM常见的"幻觉"问题,确保代码的正确性和实用性。缺乏工具集成的智能体只能依赖内部推理,无法验证其输出是否真正有效。
下表提供了主流AI编码智能体的详细分类比较,揭示了不同系统在关键能力上的差异:
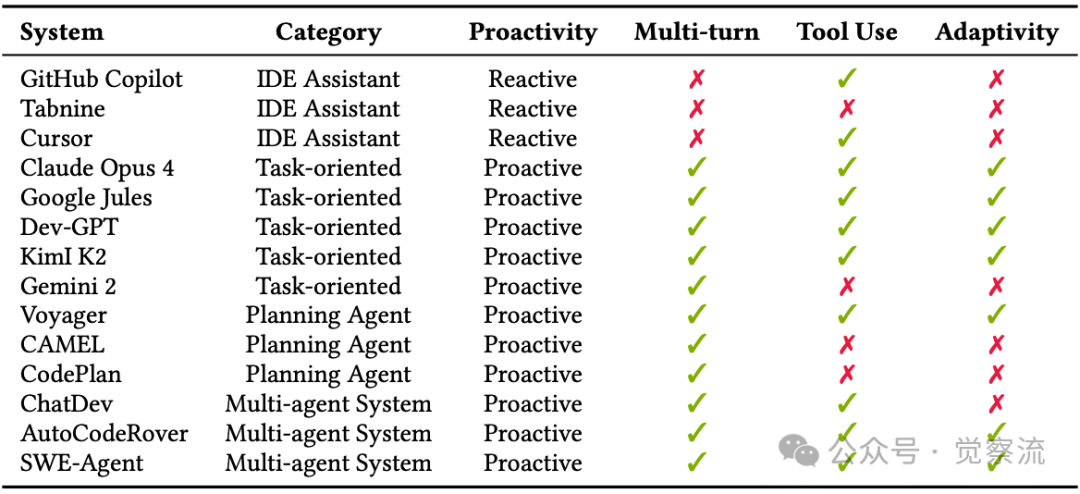
具有代表性的“AI主体”编程系统的比较
- 交互式代码助手(如GitHub Copilot、Tabnine):这类系统主要提供反应式服务,通常不维护长期状态,缺乏工具集成能力。它们在代码补全方面表现出色,但难以处理需要多步骤推理的复杂任务。关键限制:这些系统缺乏持久记忆,依赖滑动窗口或动态token预算管理,无法维持跨会话的上下文一致性。
- 自主任务导向智能体(如Claude Opus 4、Google Jules):这些系统具备高度主动性,支持多轮执行和工具集成,能够自主规划任务并根据反馈调整策略。例如,当被要求"添加用户认证模块"时,智能体不仅能生成登录逻辑,还能更新数据库、集成UI并编写测试。
- 规划中心智能体(如Voyager、CAMEL):这类系统将问题解决分为结构化任务分解和执行监控两个阶段。CAMEL采用"用户"和"助手"双智能体角色扮演机制,通过协作细化目标和策略,产生下游代码生成器可执行的计划。具体而言,"用户"智能体可以不断质疑和细化需求,而"助手"智能体则提供技术可行性评估,最终形成更可靠的执行计划——这种机制模拟了人类团队的讨论过程,显著提高了任务分解的质量。
- 多智能体协作系统(如SWE-Agent、ChatDev):这些系统引入多个专业化的智能体角色(如架构师、编码员、审查员),通过结构化对话和共享记忆协同解决复杂任务。SWE-Agent中的"Architect"负责高层设计,"Coder"负责实现,"Reviewer"负责质量保证。
理解这一分类框架至关重要,因为不同类别的智能体在应对企业级开发挑战时表现差异显著。例如,缺乏持久记忆的智能体(如GitHub Copilot)难以维持跨会话的上下文一致性,而具备多轮执行能力的智能体(如OpenDevin)则能处理更复杂的长期任务。
核心挑战:阻碍规模化应用的"拦路虎"
当前的软件开发工具链——从编程语言到编译器、调试器——其设计哲学是以人为本,强调易用性、抽象性和降低认知负荷。它们将复杂的内部状态和决策过程封装起来,只向开发者呈现简洁的错误信息和结果。然而,这种"黑箱"式设计对需要进行因果推理、错误溯源和策略调整的AI智能体而言,却是致命的。智能体无法"看到"编译器为何拒绝某次优化,也无法"理解"调试器输出的堆栈跟踪背后的确切语义。这种信息的缺失,直接导致了安全、评估和协作等一系列问题。
挑战一:评估体系的严重不足
广泛使用的基准(如HumanEval、SWE-Bench)主要聚焦于小型、孤立的编程任务,且严重偏向Python。下表详细列出了当前编程评估基准的局限性:
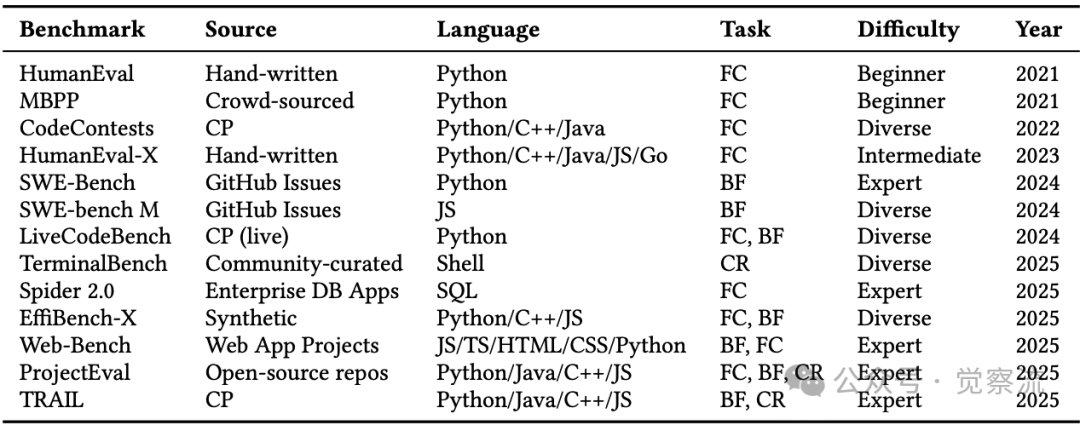
用于评估大语言模型和智能体系统在编程任务中的基准测试。CP = 竞赛编程,BF = 修复漏洞,FC = 函数补全,CR = 命令行推理
这些基准普遍缺乏对交互性、多轮迭代和工具集成任务的支持,无法真实反映智能体在大型代码库中协调编译、测试、版本控制等工具的复杂工作流。例如,HumanEval和MBPP主要针对初学者级别的函数完成任务,而SWE-Bench虽然处理更复杂的bug修复,但仍然局限于单一语言(Python)和特定上下文。
关键缺失在于缺乏衡量智能体鲁棒性(从失败中恢复的能力)、效率(工具调用的开销)和可解释性的综合指标。以LiveCodeBench评估结果为例,即使是最新的GPT-5模型,其AI Intelligence Score也仅为69,表明超过30%的挑战仍未被解决。

在LivecodeBench平台上,大型语言模型(LLM)的AI智能评分(涵盖数学、科学、编程和推理能力)以及速度(每秒输出的标记数量)
更值得注意的是,智能、速度与成本的权衡:GPT-4o以148 tokens/秒的速度领先,而Claude 4虽智能评分较低(59),但速度达100 tokens/秒。DeepSeek R1虽成本低(输入$0.55/1M tokens),但速度仅21 tokens/秒。这些数据表明,当前系统在智能、速度、成本三者间难以兼得。
这一挑战的解决方案在于开发更全面的评估框架,如前面提到的SWE-Bench M和ProjectEval等新基准,它们开始支持多语言环境和更复杂的开发工作流。未来评估应超越功能正确性,纳入工具使用效率、失败恢复能力和反馈整合能力等维度。
此外,现有评估体系严重忽视了多语言支持。大多数基准集中于Python,而对C++、Rust等静态类型语言的支持有限。这使得评估结果难以推广到更广泛的开发场景。例如,在嵌入式系统开发中,C/C++占据主导地位,但相关评估数据极为匮乏。
挑战二:工具链与智能体需求的根本错配
现有工具为人类设计,隐藏了内部状态,导致智能体"盲人摸象"。问题根源在于:今天的编程语言、编译器和调试器都是为人类开发者设计的,而非为AI智能体。这些工具强调易用性,往往抽象掉内部状态和决策过程,以降低人类的认知负荷。然而,这种设计对需要进行因果推理的智能体来说却是致命的。
GitHub Copilot Agent支持的工具类型极具代表性,涵盖编译器(gcc、clang、javac)、调试器(gdb、lldb、pdb)、测试框架(pytest、Jest)、代码检查工具(eslint、flake8)以及版本控制系统(git)等。

GitHub Copilot Agent 支持的工具示例
这些工具构成了完整的开发环境,使智能体能执行"编写-编译-测试-调试"的闭环工作流。然而,当智能体调用这些工具时,往往只能获得有限的、非结构化的反馈,难以理解错误的根本原因。

用于实现REST任务的代理式工作流程
上图展示了智能体实现REST API任务的完整工作流:从自然语言理解到代码生成,再到工具调用(Pytest测试、Sphinx文档生成),最后验证结果。这一流程凸显了多轮迭代和工具集成的核心价值——智能体不是一次性生成代码,而是通过"计划-执行-验证"循环持续改进。然而,当智能体面对编译错误时,现有工具仅提供"编译失败"这样的通用信息,而非解释失败的具体原因。
例如,当一次代码转换导致构建失败时,智能体需要的不仅是"编译失败"这样的错误消息,更需要追溯到具体的中间步骤和变更影响。考虑一个具体场景:当智能体尝试修改一段关键代码导致构建失败时,现有工具仅提供"编译失败"这样的通用信息,而智能体实际需要知道"由于第47行的类型不匹配导致模板实例化失败,建议检查泛型参数约束"。这种细粒度的反馈缺失迫使智能体进行盲目尝试,大大降低了开发效率和安全性。
这一挑战的解决方案直接指向"重塑工具链":编译器需要提供结构化反馈,解释为何特定优化(如向量化或内联)失败,这需要识别语义障碍如未解决的别名、模糊的数据/控制流或缺少注解。这种反馈机制将使智能体能够精确修正问题,而非盲目尝试。
挑战三:安全与隐私的严峻挑战
具备高自主性的智能体在无直接监督下,可能引入隐蔽的bug、安全漏洞,甚至因恶意Prompt或被"中毒"的API误导而执行有害操作。在私有仓库或云集成环境中,智能体可能访问敏感项目数据,存在数据泄露风险。例如,在私有仓库环境中,智能体可能无意中将敏感API密钥包含在生成的代码中,或在无意识中引入安全漏洞(如SQL注入)。由于缺乏对代码安全含义的深层理解,智能体可能无法识别这些风险,而现有工具链也未提供针对AI的专门安全检查机制。
此外,恶意攻击者可能通过精心构造的Prompt或篡改的工具链,诱导智能体执行有害操作。解决这些问题需要构建内置的访问控制机制、行为验证流程和异常检测能力,以及为智能体操作提供类似"沙箱"的隔离执行环境。
评估AI编码智能体的实际可行性,必须考虑成本与Token消耗。不同推理策略对成本影响显著:短推理(直接生成代码)消耗最少tokens但准确率低;标准CoT(链式思维)消耗约两倍tokens但提高首次正确率;而工具增强迭代推理(多次测试修正)虽最可靠,却大幅增加token消耗和时间成本。
下表提供了不同模型的详细定价数据:
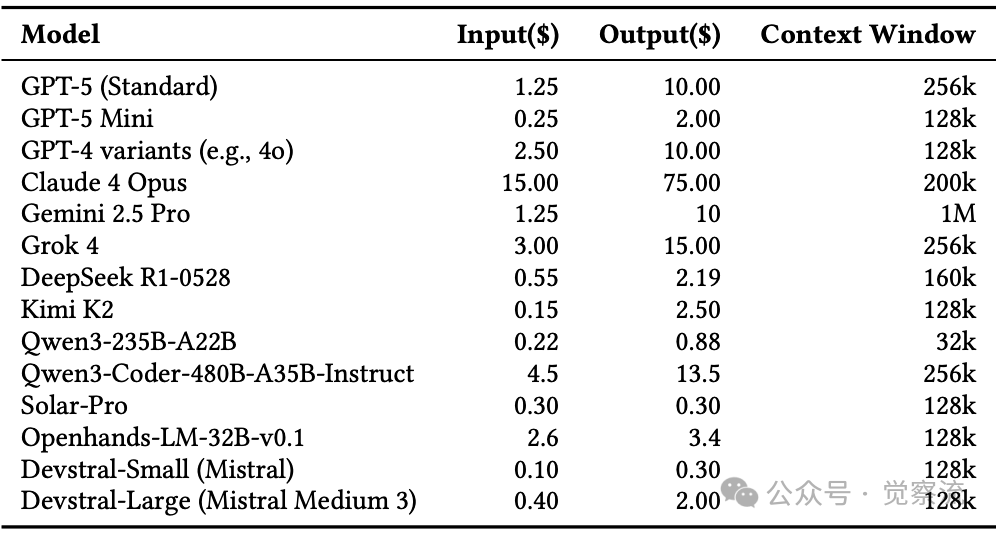
用于编程任务的大型语言模型的代表性代币定价(截至2025年8月,每100万代币的美元价格)
例如,GPT-5输入1M tokens成本为 $1.25,输出则高达$10.00,而Claude 4 Opus输出成本更是达到 $75.00。考虑一个中等规模的重构任务:若采用工具增强迭代推理策略,平均需要10轮迭代才能成功,每轮消耗约3000 tokens(输入)和2000 tokens(输出)。使用GPT-5将产生约$62.5的成本(10×(3000×$1.25/1M + 2000×$10/1M)),而使用DeepSeek R1则仅需约$14.4(10×(3000×$0.55/1M + 2000×$2.19/1M))。这种成本差异在大型项目中可能达到数千美元,直接影响企业的技术选型决策。
挑战四:人机协作的"信任鸿沟"
在Agentic Programming中,开发者从单纯的"命令者"转变为"协作者"和"监督者",需要与智能体进行动态交互。要建立这种协作关系,开发者必须能够信任智能体的行为。这意味着智能体必须能清晰地解释其决策(Why?)、展示其推理依据(How?)、并在不确定时表达其置信度。
然而,由于现有工具链不提供程序状态追踪与回放机制,智能体难以重建"为何某次修改引入了类型错误"或"哪个变更导致了性能退化"的完整因果链,从而限制了其解释和沟通的能力。当智能体建议重构一段关键代码时,开发者需要了解其推理过程、考虑的替代方案以及潜在风险,而不仅仅是最终结果。
真正有效的协作不是简单的任务分配,而是动态责任转移。开发者可设定高层次目标与架构约束,智能体则主动探索设计空间、生成代码并执行测试,随后开发者审查结果。例如,当智能体面对"make this more efficient"的模糊指令时,应能识别需优化的维度(速度、内存或可读性),生成多种方案并附带测试结果,由开发者选择最佳路径。这种双向协作模式要求智能体具备解释决策、引用文档和突出权衡点的能力,而非仅提供最终答案。
有效的混合主动工作流应允许控制权在开发者和代理之间流畅转移。例如,当代理遇到模糊指令"使此功能更高效"时,应能识别可能的优化维度(速度、内存或可读性),生成多种方案并附带性能基准测试结果,由开发者选择最合适的路径。这种协作模式要求代理不仅能执行任务,还能理解开发者的隐含偏好和项目上下文。
此外,下表揭示了主流AI编码智能体在上下文管理上的显著差异:
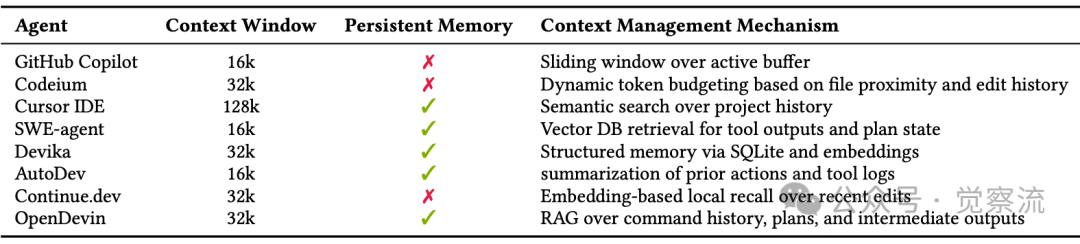 主流编程智能体支持的上下文管理机制
主流编程智能体支持的上下文管理机制
上表可以看到一个关键事实:缺乏持久记忆的智能体(如GitHub Copilot和Codeium)在处理跨会话任务时将面临严重限制。当需要修改一个涉及多个文件的复杂功能时,这些系统无法记住之前的操作和结果,导致重复错误或丢失关键上下文。相比之下,使用向量数据库存储工具输出和计划状态的SWE-agent和OpenDevin能更好地维持长期一致性。GitHub Copilot和Codeium缺乏持久记忆,依赖滑动窗口;而SWE-agent和OpenDevin则使用向量数据库存储工具输出和计划状态。这种差异直接影响智能体处理长期任务的能力——没有持久记忆的智能体难以维持跨会话的上下文一致性,导致在复杂项目中重复犯错或丢失关键信息。
破局之道:面向未来的机遇
要弥合这一"信任鸿沟",不能仅靠提升LLM的参数规模,而必须从系统层面进行重构。以下机遇均是对前述挑战的直接回应,其核心是将AI智能体视为开发生态中的"一等公民",并为此重新设计我们的工具和范式。
机遇一:重塑工具链,实现AI原生支持
针对工具链与智能体需求的根本错配,需要从基础设施层面进行变革:
- 结构化诊断:编译器应超越简单的错误信息,提供结构化的反馈,解释"为何优化失败"(如存在别名冲突、控制流不明确、缺少必要注解等)。例如,当向量化失败时,编译器可以指出是由于数据依赖性、内存对齐问题还是其他具体原因。这种细粒度的反馈使智能体能够精确修正问题,而非盲目尝试。
- 开放内部表示:允许智能体直接访问和操作中间表示(IR)(如LLVM IR、MLIR),使其能在语义层面进行推理、验证和变换。通过与编译器API(如Clang的LibTooling)的深度集成,智能体可以执行更精确的代码分析和修改。例如,当需要重构代码时,智能体可以直接操作AST(抽象语法树),确保变换保持语义等价。
- 语言级注解:引入Agent-aware的扩展或注解,让开发者能用自然语言或领域特定语言(DSL)向智能体传达意图。例如,通过注解"@optimize_for_speed"或"@must_be_thread_safe",开发者可以指导智能体在优化过程中的优先级和约束条件。这不仅提高了代码生成的准确性,还为智能体提供了明确的验证标准。
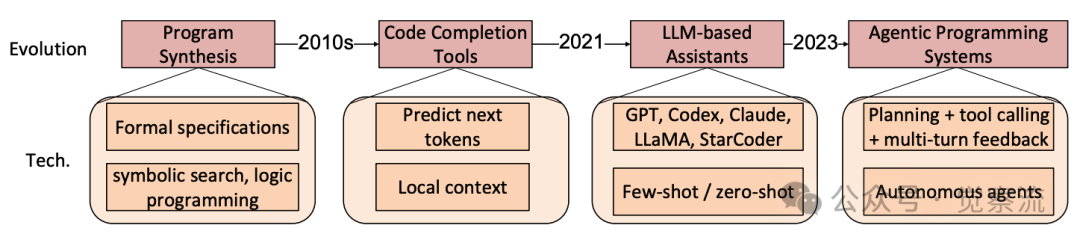
一张展示编码智能体从程序合成发展到代码补全工具,再到人工智能编码智能体的演变过程的图表
这种工具链的"AI原生化"重构,是解决安全、评估和协作问题的基础设施级突破,将使智能体从"猜测者"变为"知情参与者",大幅提升其可靠性和可解释性。例如,当智能体尝试修改一段关键代码时,编译器可以提供"此更改可能导致竞态条件,因为共享资源未正确锁定"的精确警告,而非仅显示"编译失败"。
机遇二:领域专业化与意图对齐
针对嵌入式系统、高性能计算(HPC)或形式化验证等特定领域,通用智能体往往表现不佳。这是因为这些领域通常有严格的约束条件和专业化的工具链,而这些在通用训练数据中往往代表性不足。
未来应发展领域基础模型(Domain Foundation Models),通过在领域特定数据、工具和语义上进行预训练或微调,使其具备深度的领域知识。例如,一个面向嵌入式系统的智能体需要理解内存布局、实时约束和硬件特定API,而一个面向科学计算的智能体则需要熟练使用NumPy、MATLAB等工具。
同时,应超越模糊的自然语言Prompt,探索使用结构化输入(如形式化约束、输入-输出测试用例、高层次目标)来精确表达用户意图。设计结构化语言,让开发者可以明确声明"必须做"、"禁止做"和"可接受解"的边界。智能体的行为应受到这些规则的约束,并可与静态分析工具结合,实现轻量级的自动验证。
在安全关键领域(如航空航天、医疗软件),这种意图对齐尤为重要。智能体必须能够遵循严格的编码标准、法规要求和认证指南,而不仅仅是生成"看起来正确"的代码。例如,MISRA C编码标准为汽车软件定义了140多项规则,智能体应能理解并遵守这些规则,同时能够解释为何特定代码变更符合或违反这些规则。
机遇三:可扩展记忆与上下文管理
当前LLM受限于固定的上下文窗口(通常在128k-1M tokens之间),难以处理涉及多文件、长历史的复杂任务。当智能体需要在大型代码库中工作时,这一限制尤为明显。
下表可以看到主流AI编码智能体在上下文管理上的显著差异:GitHub Copilot和Codeium缺乏持久记忆,依赖滑动窗口;而SWE-agent和OpenDevin则使用向量数据库存储工具输出和计划状态。这种差异直接影响智能体处理长期任务的能力——没有持久记忆的智能体难以维持跨会话的上下文一致性。
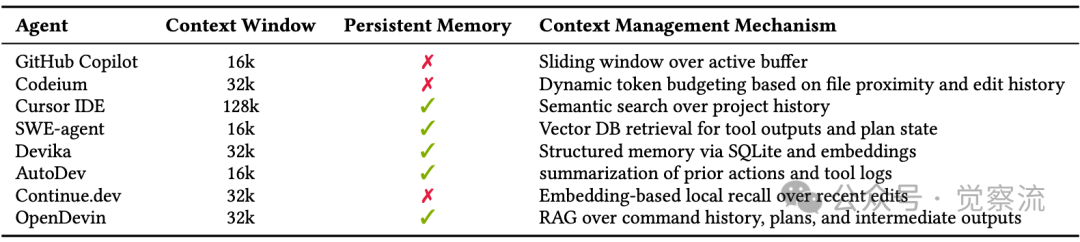
主流编程智能体支持的上下文管理机制
未来方向包括:
- 分层记忆模型:一种区分短期交互历史、中期规划目标和长期项目知识的记忆架构,使智能体能在不同时间尺度上维持上下文一致性。短期记忆存储最近的工具调用和结果,中期记忆跟踪当前任务的子目标和决策,长期记忆则保存项目特定的模式、用户偏好和过往经验。例如,当处理一个长期项目时,智能体可以记住之前在类似模块中遇到的特定问题及其解决方案。
- 代码感知检索:发展基于代码结构的注意力机制,利用抽象语法树(AST)、控制流图(CFG)和数据依赖关系,使智能体能精准定位相关信息。例如,当调试一个函数时,智能体应能自动关注该函数的调用链和相关数据流,而非简单地搜索语义相似的内容。这比传统的基于向量相似度的检索方法更精确,能显著减少无关信息的干扰。
- 持久化存储:实现跨会话的持久化记忆,使智能体能够从过去的交互中学习并积累经验。这需要设计高效的向量数据库和记忆索引机制,支持快速检索和更新。例如,智能体可以记住某个特定API的最佳使用模式,或识别出项目中反复出现的设计模式。
这些技术将使智能体能够处理更复杂的任务,维持更长时间的一致性,并从历史经验中不断改进。例如,一个智能体可以记住之前在类似项目中遇到的特定问题及其解决方案,从而更快地诊断和修复新项目中的类似问题。在大型开源项目贡献中,这种能力尤为重要——智能体需要理解项目特有的代码风格、架构约束和贡献流程,而这些信息往往分散在多个文件和历史提交中。
总结:通向可信AI开发的路径
AI Agentic Programming 的未来,不在于创造一个完全取代人类的"超级智能",而在于构建一个人与AI协同进化的生态系统。一个成功的智能体,其价值不仅在于"聪明",更在于它是安全的、可解释的、可评估的、可协作的。实现这一愿景的关键,是承认并解决现有工具链与AI智能体需求之间的根本错配。
这一"元挑战"的根源在于软件开发工具数十年来一直针对人类认知特点设计——强调抽象、隐藏复杂性、提供简洁错误信息。而AI智能体恰恰需要相反:细粒度的结构化反馈、内部状态的透明访问、以及决策过程的完整解释。例如,当编译器拒绝某次优化时,它向人类开发者隐藏了复杂的依赖分析过程,但这些正是AI智能体诊断和修复问题所必需的信息。解决这一根本性错配,需要重新思考整个软件开发生态系统的设计哲学。
这一挑战需要跨学科的深度协同:编程语言(PL) 领域专家需要设计AI友好的语言特性和编译器接口;软件工程(SE) 专家需要构建端到端的评估框架和验证方法;人工智能(AI) 研究者需要探索更高效的规划、记忆和对齐机制;以及人机交互(HCI) 专家需要设计直观、高效的混合主动协作协议。
随着这些努力的推进,AI Agentic Programming 将从当前的"炫技"阶段迈向真正的"可用"阶段,成为软件开发中不可或缺的智能伙伴。在这个过程中,我们不仅会创造出更高效的开发工具,更会重新定义软件开发的本质,开启人机协作的新纪元。成功的AI编码智能体必须在智能、安全、效率与协作之间取得平衡。唯有通过这种跨学科协同,我们才能将AI编码智能体从当前的"炫技"阶段,带入真正"可用"的新纪元。
在企业级部署的道路上,技术决策者需要认识到:AI Agentic Programming 不仅是一项技术革新,更是一场开发范式的转变。它要求我们重新思考软件开发的每一个环节——从编程语言设计到工具链构建,从评估方法到人机协作模式。只有当我们把AI智能体视为开发生态中的"一等公民",并为此重构我们的工具和流程,才能真正释放其潜力,实现软件开发的智能化跃迁。


