 人类已经走上了创造 AGI(通用人工智能)的道路,而其中一个关键方面是持续学习,即 AI 能通过与环境互动而不断学习新的知识和能力。
人类已经走上了创造 AGI(通用人工智能)的道路,而其中一个关键方面是持续学习,即 AI 能通过与环境互动而不断学习新的知识和能力。
为此,研究社区已经在探索多种不同的道路,比如开发能够实时更新状态的循环神经网络(RNN),或者试图通过极大的缓存空间来容纳海量历史。然而,真正的 AGI 或许不应仅仅被动地「存储」信息,而应像人类一样在阅读中「进化」。
想象一下你生命中的第一次机器学习讲座:你或许记不清教授开口说的第一个单词,但那场讲座留给你的直觉和逻辑,此刻正潜移默化地帮助你理解这篇复杂的论文。这种能力的本质在于压缩。
近日,Astera 研究所、英伟达、斯坦福大学、加州大学伯克利分校、加州大学圣地亚哥分校的一个联合团队提出的TTT-E2E(端到端测试时训练)沿着这条 AGI 的必经之路迈出了重要一步。它彻底打破了传统模型在推理时静态不变的局限,让长上下文建模从一种「架构设计」进化为一种「学习问题」。

该方法可以在测试阶段通过给定上下文的下一个 token 预测持续学习,将读取的上下文信息压缩至权重参数中。

论文标题:End-to-End Test-Time Training for Long Context
论文地址:https://arxiv.org/abs/2512.23675
代码地址:https://github.com/test-time-training/e2e
困难是什么?召回与效率的永恒博弈
论文开篇明确了当前长上下文建模的两难境地。
Transformer 的全注意力机制虽然在长文本上表现优异,但其推理成本随长度线性增长,这在处理 128K 甚至更长的上下文时会产生巨大的延迟压力。为了解决效率问题,业界曾转向循环神经网络(RNN)或状态空间模型(SSM,如 Mamba)。这些模型虽然拥有恒定的每 token 计算成本,但在处理超长文本时,性能往往会大幅下降,无法像 Transformer 那样有效利用远距离的信息。
这种性能下降的根源在于「压缩率」的固定。
传统的 RNN 将无限的序列压缩进固定大小的状态向量中,这不可避免地会导致信息丢失。
于是,该团队思考:是否能找到一种方案,既能像 RNN 一样拥有恒定的推理延迟,又能像 Transformer 一样通过增加「存储空间」来维持长距离性能?
端到端的测试时训练(TTT-E2E)
TTT-E2E 的核心思想是将模型在测试阶段(推理阶段)的行为定义为一个在线优化过程。
具体而言,当模型读取长上下文时,它不仅仅是在做前向传播,还在同步进行梯度下降。
这种方法基于这样一个逻辑:如果我们将上下文看作一份学习资料,那么模型在预测下一个 token 之前,可以先在已经读过的 token 上进行自监督学习。
通过这种方式,上下文中的信息就被编码进了模型的权重 W 中,而不是存储在外部的 KV Cache 里。这就像是在阅读一本书时,你不断根据新读到的内容修正自己的认知模型。
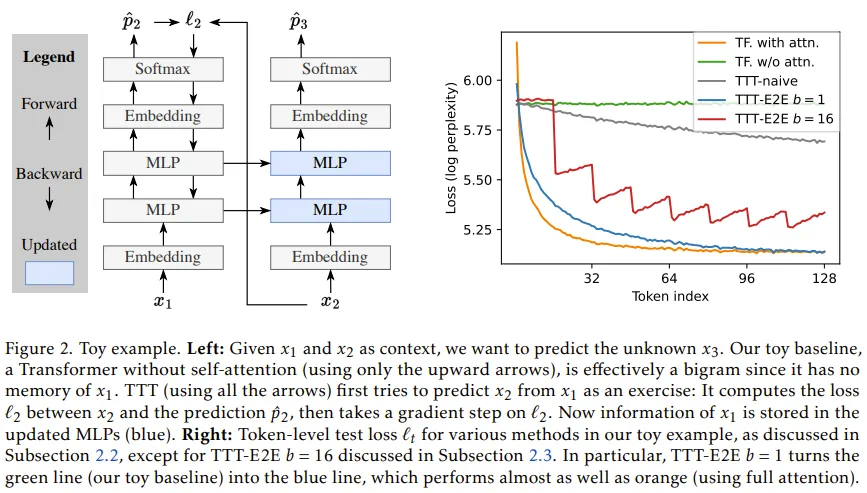
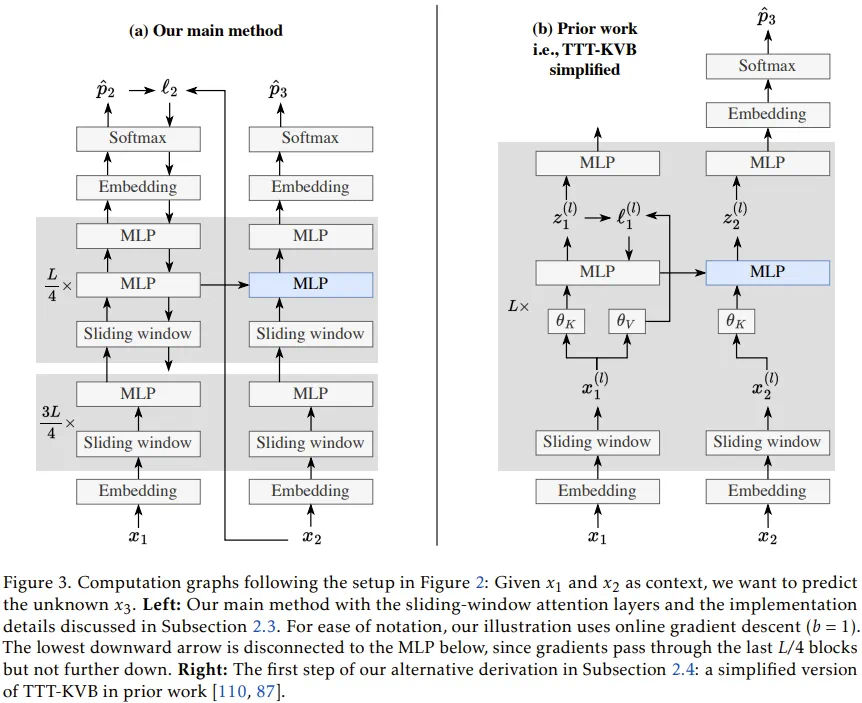
为了使这一构想在工程上可行且高效,团队引入了两大核心技术支撑。
首先是元学习(Meta-Learning)。传统的模型在预训练时并未考虑测试时的更新逻辑,这会导致训练与测试的脱节。TTT-E2E 通过外层循环(Outer Loop)优化模型的初始化参数,使得模型「学会如何学习」,即经过少量测试时梯度更新后,能达到最优的预测效果。
其次是架构的微调与滑动窗口的结合。该团队意识到,如果完全摒弃注意力机制,模型会丧失局部精确记忆能力。因此,TTT-E2E 采用了一种混合架构:使用一个固定大小(如 8K)的滑动窗口注意力(SWA)来处理短期记忆,确保局部逻辑的严密;而对于超出窗口的长期记忆,则交给 TTT 更新后的 MLP 层来承担。这种设计模仿了生物记忆系统的层级结构:滑动窗口如同瞬时感官记忆,而动态更新的权重则如同长期经验。
为了平衡计算开销,团队在实现细节上也极具匠心。他们并非更新模型的所有层,而是仅针对最后四分之一的 Transformer 块进行 TTT。
同时,他们为这些块设计了双 MLP 结构,一个保持静态以锁定预训练知识,另一个则作为「快速权重」在测试时动态更新,从而解决了知识遗忘的问题。
详细的数学描述请参阅原论文。
实验结果:性能与速度的双重飞跃
实验数据证明了 TTT-E2E 的强大潜力。研究团队在 3B 参数规模的模型上进行了系统性扩展实验。
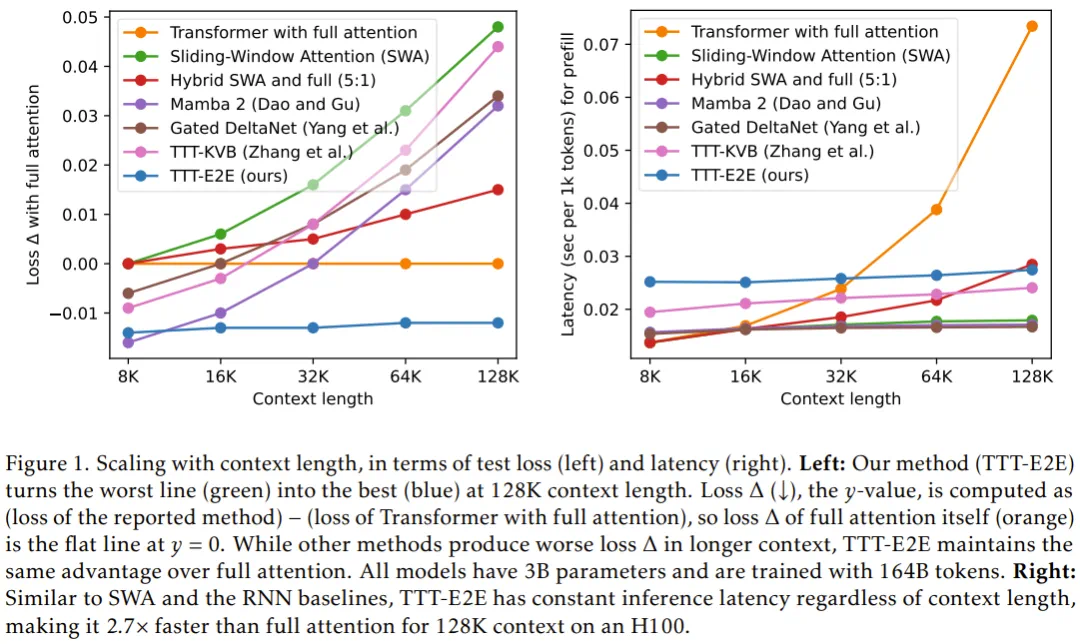
在性能扩展性方面,TTT-E2E 展现出了与全注意力 Transformer 几乎一致的性能曲线。
随着上下文长度从 8K 扩展到 128K,其他 RNN 基准模型(如 Mamba 和 Gated DeltaNet)的测试损失在达到 32K 之后开始显著回升,这意味着它们无法处理更长的序列。而 TTT-E2E 的损失函数则持续下降,始终保持着对 Transformer 的追赶态势,甚至在某些指标上更优。
在推理效率方面,TTT-E2E 展现了压倒性优势。
由于它不需要存储海量的 KV Cache,其推理延迟不随上下文长度增加而改变。在 128K 上下文的测试中,TTT-E2E 的处理速度比全注意力 Transformer 快了 2.7 倍。
这意味着开发者可以在不牺牲模型表现的前提下,极大地降低长文本应用的响应时间。
然而,研究也坦诚地指出了天下没有免费的午餐。尽管推理极快,但 TTT-E2E 的训练成本目前仍然较高。由于训练时需要计算「梯度的梯度」(二阶导数),其在短上下文下的训练速度比传统模型慢得多。
不过,该团队提出,可以通过从预训练好的 Transformer 节点开始微调,或者开发专门的 CUDA 内核来弥补这一短板。
此外,在大海捞针(NIAH)这类极端依赖精确召回的任务中,全注意力模型依然是无可争议的霸主。这进一步印证了作者的观点:TTT 的本质是压缩和理解,而非逐字的暴力存储。
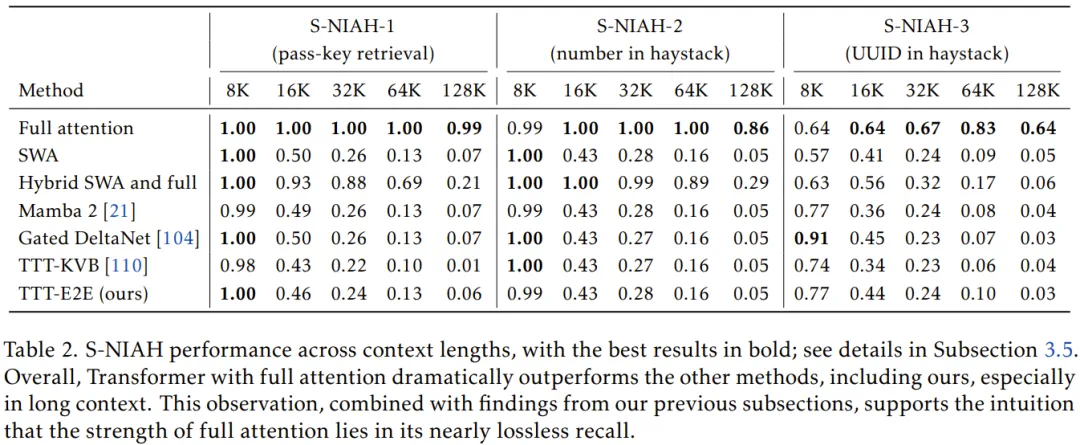
通往无限长度的未来
TTT-E2E 的意义远不止于一个更快的算法。它标志着大模型正在从静态模型转变为动态个体。在这一框架下,模型处理长文档的过程,本质上是一次微型的自我进化。

这种「以计算换存储」的思路,为我们描绘了一个充满想象力的未来:或许有一天,我们可以让模型在阅读一万本书的过程中不断调整自身,最终将人类的整个文明史浓缩进那跳动的参数矩阵之中,而无需担心硬件缓存的枯竭。


