核心突破:首次将LLM推理中的P/D分离思想扩展至多模态场景,提出EPD(Encoder-Prefill-Decode)三阶段解耦,并通过「空分复用」彻底解决编码器引发的行头阻塞问题。
随着多模态大语言模型(MLLM)广泛应用于高分辨率图像理解、长视频分析等场景,其推理流程中的多模态编码(Encoding)阶段正成为性能瓶颈。
当前主流系统(如vLLM)在服务MLLM时,仍沿用「时间复用」(time-multiplexing)策略:GPU先执行视觉/音频编码器,完成后才切换上下文运行文本解码器。
这一设计在高并发下引发严重的行头阻塞(head-of-line blocking):一个高分辨率图像的编码可能耗时数百毫秒,在此期间,所有等待生成文本的解码请求都被迫阻塞。
结果是:解码器长期「饥饿」,TPOT(每输出token耗时)随请求率飙升,服务吞吐急剧恶化。
SpaceServe:从「时间复用」到「空分复用」
NeurIPS 2025接收论文《SpaceServe: Spatial Multiplexing of Complementary Encoders and Decoders for Multimodal LLMs》提出全新解决方案:空分复用(Space Multiplexing)。
该研究由中国科学院计算技术研究所处理器芯片全国重点实验室编译与编程团队博士生李志成与副研究员赵家程等人共同完成。
其核心洞察源于对MLLM资源消耗的定量分析:
- 视觉编码器:计算密集,内存带宽需求低;
- 文本解码器:内存密集,严重依赖HBM带宽存储KV Cache。
二者资源需求高度互补,却在时间复用架构下被迫串行执行,造成GPU资源严重浪费。
SpaceServe的关键创新在于:
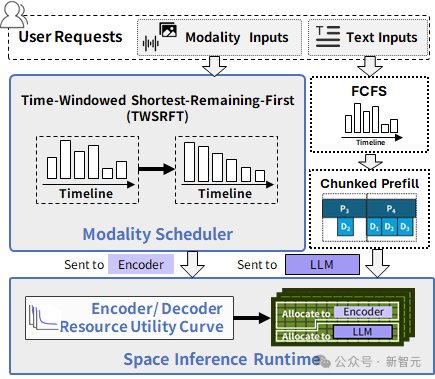
1. EPD三阶段逻辑解耦+物理共置
- 将所有模态编码器从共享文本解码器中完全解耦,支持独立调度;
- 利用现代GPU运行时(如NVIDIA libsmctrl / green-ctx, AMD cumask)提供的细粒度SM分区能力,将编码器与解码器共置在同一GPU上,实现并发执行。
这并非简单并行,而是让计算密集型与内存密集型任务在微观层面形成资源互补。
2. TWSRFT编码器调度策略
- 在时间窗口内,按「剩余工作量最短优先」批处理编码请求;
- 避免大图阻塞小图,平滑解码器输入流,提升吞吐稳定性。
3. 基于资源利用曲线的资源动态分配运行时(Space Inference Runtime)
- 离线构建资源-效用曲线,刻画不同输入(如图像分辨率)下编码器/解码器的延迟与SM占用关系;
- 在线根据请求元数据(patch数、上下文长度),动态分配SM计算单元,最小化端到端延迟。
实测性能:高并发下超越vLLM
在Qwen2-VL系列模型(2B–72B)上,SpaceServe显著优于vLLMv1:
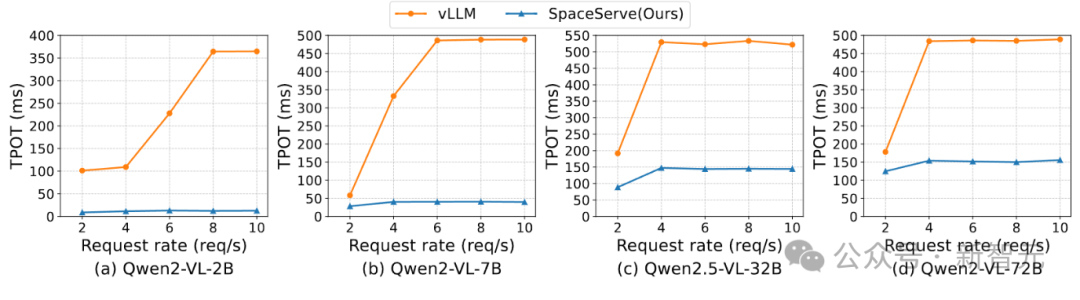
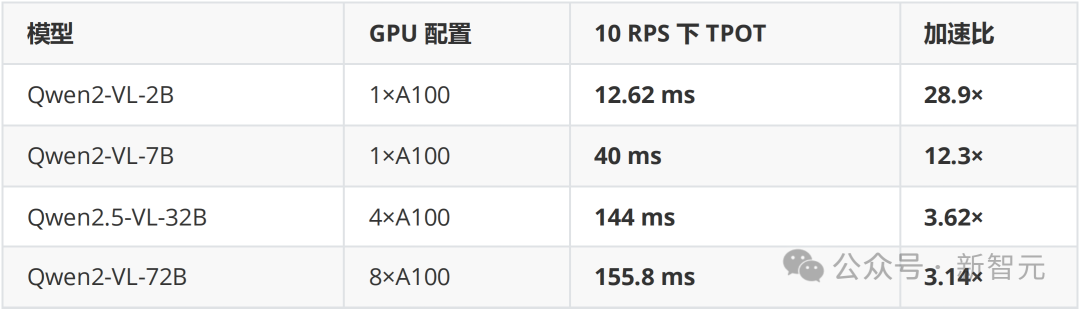
关键现象:vLLM的TPOT随请求率急剧恶化(如2B模型从101ms→365ms),而SpaceServe几乎保持稳定(8.85ms→12.62ms)。
根本原因:vLLM中,编码器独占GPU时,解码器无法推进;而SpaceServe通过空分复用,让解码器在编码器运行的同时持续生成token,彻底解耦执行流。
为何比MPS更优?
细粒度SM隔离是关键
为验证设计有效性,SpaceServe还对比了NVIDIA MPS(Multi-Process Service)方案。结果显示:
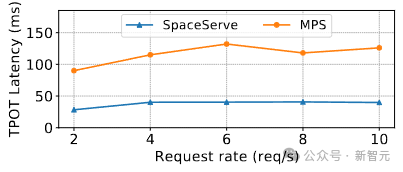
- MPS版本在10 RPS下TPOT为132ms;
- SpaceServe(细粒度SM分区)仅为40.68ms,提速3.3×。
原因:MPS仅在进程级隔离,编码器与解码器仍会争抢同一SM内的寄存器、L1 cache等资源,导致缓存污染与occupancy下降。
而SpaceServe通过SM级物理分区,实现真正的资源隔离,最大化各自执行效率。
行业意义:为MLLM推理树立新范式
- 首次系统性解决MLLM推理中的行头阻塞问题;
- 无需修改模型结构,兼容Qwen2-VL、Kimi-VL等主流MLLM;
- 代码开源,有望集成至vLLM、SGLang等框架,推动多模态服务高效落地。

项目地址:https://github.com/gofreelee/SpaceServe
值得注意的是,SpaceServe主要优化稳态吞吐(TPOT),对首token延迟(TTFT)影响有限——这与设计目标一致:解码器持续高吞吐,而非单次编码加速。


