
我们发现,在国内的头部厂商中,火山发动机的豆包系列视频生成模型已经很长时间没有大的版本更新了。前代 Seedance 1.0 pro 的问世已经过去半年时间了,这也让我们对其下一代 Seedance 1.5 的关注度越来越高。


到底在蓄什么大招?在今天上午举办的火山发动机2025年冬季原力动力大会上,最新一代豆包视频生成模型「Seedance 1.5 pro」正式亮相。

这一次,Seedance 1.5 pro 做到了原始音画高精同步,覆盖环境音、动作音、合成音、乐器音、背景音乐及人声等全场景,音画同步率全球领先。同时,该模型能够更好地遵循复杂指令,支持更多外国语言与中文方言的自然对白,更精准地捕捉运动细节,叙述与连贯性更强,人物情绪表情也呈现得更加细腻。
在一系列新能力的加持下,Seedance 1.5 pro在整体完成度、更细粒度的镜头控制与画面表现力上已经不可同日而语。
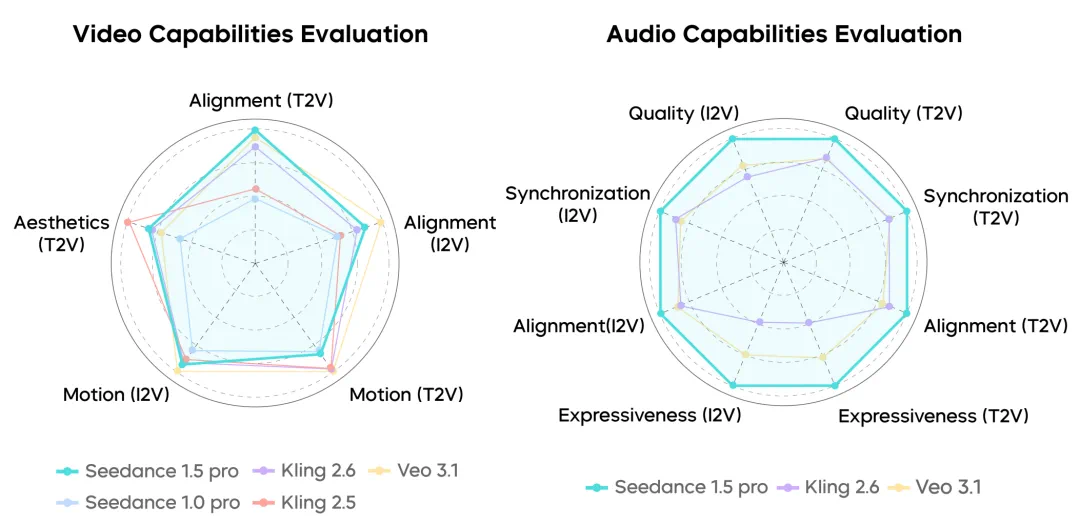
如下图所示,在视频能力评估中,Seedance 1.5 pro 在文本生成视频(T2V)的视觉度(Alignment)指标上取得领先,并在其他指标指标(T2V 的画面美感以及图像生成视频 I2V 的视觉度与运动)上位居前列。而在音频能力评估中,Seedance 1.5 pro 在生成质量、同步性、视觉度、表现力等参数指标上超越 Veo 3.1 和克林2.6。
目前,Seedance 1.5 pro已经上线火山方舟体验中心,预计12月23日通过火山个人引擎为企业用户提供API。用户则可以通过即梦网页版和豆包App使用。
链接:https://exp.volcengine.com/ark/vision?launch=seedance
接下来,我们就奉行上一手实测。
一手实测:能说16种方言,还能飙演技
很长一段时间里,AI生成的视频都是「默片」,画面再精致,没有声音,观感上总觉得差口气。
直到谷歌Veo3彻底打破僵局,引发音画同步热潮,其他厂商也纷纷朝着这个方向发力。
此次Seedance 1.5 pro最大更新就是原声画同步,甚至更进一步,不仅实现了一个视频中多个超自然对白、口型实现精准级精准定位,还支持中文、方言、英文及小语种等多种语言。
就拿中文来说,除了普通话,还可以轻松拿捏捏话、四川话、东北话、台湾腔、闽南语、粤语等16种方言口音。
这几天,网友们对GPT-5.2的「怨气」很重,嫌它太平淡、过度安全、「把问题当做幼儿园幼儿对待」。
大家这么不爽,我们决定整个花活儿,让山姆·奥尔特曼用美式中文和陕西话吐槽下。
视频中,奥特曼满脸嫌弃的小表情相当够,眉毛微皱,嘴巴一撇,用蹩脚的中文吐出「GPT-5.2 不好用」几个字,最后还耸肩,一脸无奈。
后半段,Altman陕西说法得贼地道、贼带劲,口音就是《武林外传》中佟掌柜那味儿。
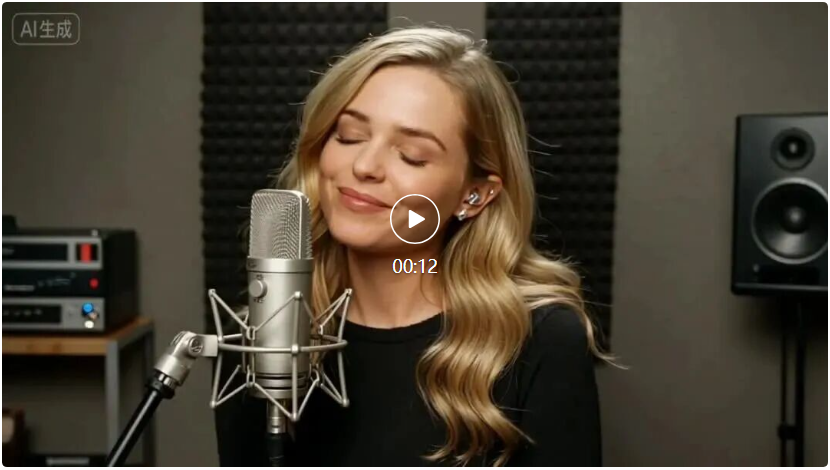
提示词:金发美女在录音棚里对着麦克风唱中文歌。
前面还只是个人秀,多人多语言对白才是重头戏。
我们整理了一个复杂的提示词,其中包括头部镜头运动、表现、光影效果、音效层次、跨语言对话等等多项测评要素。
Seedance 1.5 pro 严格遵循文本描述,动态的手持拍摄效果,镜头转换丝滑。
男主持与美国游客一个说中文,一个说英文,口型完全对得上,连说话时的气口、调侃的语调都很自然。
提示词:一段动态的手持镜头紧跟着一位自信的男主持人穿梭在熙熙攘攘的街头。他手持麦克风,拦住一位美国游客,嘴一笑,问道:“你觉得 Seedance 是目前最好的视频生成模型吗?” 美国游客轻笑一声,回答道:“这要看情况——它能让我看起来比现实生活更好吗?”镜头缓慢拉近,附近的行人发出笑声,霓虹灯在雨后湿滑的人行道上暗示。采用手持拍摄的松散跟踪镜头,景深较浅,将拍摄对象从模糊的城市运动背景中分离出来。霓虹灯招牌倒映在水坑和玻璃上,而路灯柔和的氛围围光则突出了人们的脸庞。都市写主义,色彩堵塞度高,实感干燥,动感强烈。画面安静聚焦于表情人物。对话语气轻松自信,玩笑的含义。环境音是汽车喇叭声、人群熙熙攘攘的交谈声、四周喧闹的音乐声、笑声。
仅仅一个简单模糊的提示,模型自动脑补出完整的相同相声内容,一个捧哏,一个逗哏,一个普通话得贼准,一个四川话得贼溜。
提示词:两个年轻人在台上表演相声,一个用普通话,一个用四川话,台下时不时发出笑声。
前段时间,AI生成的ASMR视频非常火,在社交媒体上动可能就能获得上百万的播放量。
此类视频主要是通过各种声音刺激,如敲击声、耳语声等,触发的感官愉悦反应,帮助人们放松和入睡。
Seedance在这方面表现也不错。比如让ASMR创作者敲键盘然后对着麦克风吹气说话,它生成的机械轴声、吹气声、说话声层次分明,音画配合的精准度,完全堪比美谷歌的Veo3.1。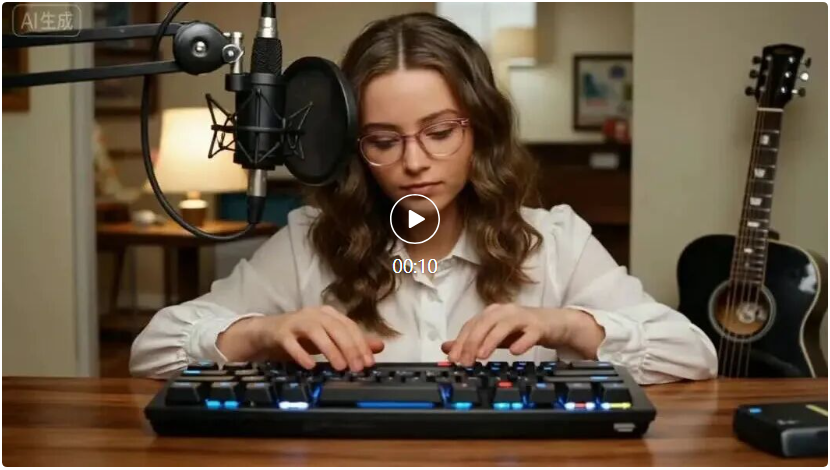
提示词:asmr创作者在嘈杂的键盘上打字,然后抬头对着麦克风吹气说话。
表演这块,AI也越来越「戏老骨」了。Seedance 1.5 pro实现影视级转录张力,整个短剧不成问题。
我们上传一张女生特色素颜照,分别输入提示词:生成女生开怀大笑的表情、愤怒的表情、悲伤的表情、悲伤的表情。

它生成的胸部情绪都挺细腻,大笑时见眼角纹,愤怒时眉头紧蹙、呼吸穿戴,悲伤时不自觉落泪,还有倦时深深的叹息,一看就是老打工人了。
这个架势,以后演员的饭碗可能真的悬了。
在赛车等强调速度动态、或者战争类重大事件处理上,Seedance 1.5 Pro 剧场不打怵。
好像它生成的红白相间F1赛车在城市赛道上疾驰,运动幅度大,但滋润且有张力。画面自带80年代胶片颗粒感,模糊动态处理得极好,那种速度视觉带来的冲击力,还真有老式赛车纪录片的感觉。
提示词:镜头高高掠过阳光普照的摩纳哥悬崖,几乎与空中的飞行高度相当。下方,一身红白相间的20世纪80年代一级赛车疾驰在城市上,闪亮的漆面和澎湃的动力令人目眩神迷。镜头拍摄出由浅色调的建筑、狭窄的弯道以及侧壁波光对称的地中海结构的精美画卷。赛车的速度与精准度令人惊叹——它的造型在发夹弯和隧道照亮中翩翩起舞,不时被明亮的阳光轻抚。影片的画面光泽粗粝而真实:自然的动态模糊、柔和的胶片颗粒以及照射下的高光,仿佛覆盖了老式35毫米赛车纪录片的风采。
场景中,手持镜头的眩晕动呼应了士兵的奔跑,爆炸声、脚步战声、喘息声混在一起,紧迫感扑面而来。
提示词:一战战场上的电影场景,一名英国士兵在泥泞的地面上全速奔跑,迫击炮弹在附近爆炸,扬起尘土和硝烟。镜头以手持拍摄的方式横向紧随他,轻微晃动,与他的动作相呼应,给人一种紧张感。爆炸隆作响,炮弹呼啸而过,最终飞溅,冲击波席卷起整个场景,营造出一种紧张而真实的氛围。
还有的FPS的追逐戏,这种复杂的动态场景对AI来说其实还是有挑战的,既要保证画面的连贯性,又要处理更多层次的运动元素,还要兼顾环境音效和冲击视觉力。
从结果生成来看,手持自然的晃动、支架飞掠、发动机轰鸣、跑步的呼吸声、脚步声,都捕捉到了精准,没有逻辑崩坏和僵硬感。
提示词:第一人称手持拍摄,镜头晃动:观众在茂密的丛林中全速奔跑,追逐前方疾驰的摩托车手。树枝在镜头前飞舞,落叶在脚下嘎吱作响,引擎的轰鸣声在树林间回荡。随着追逐愈演愈烈,光线在树冠间闪烁。电影动作镜头
最后,我们看看它在商业广告上的潜力。
该模型挺擅长处理复杂空间变化,箱体开启、汽车拆分、展厅元素串联起来,轻轻松松给特斯拉「拍」了一个概念大片,最难得的是它能严格遵循这么长的复杂提示词,把极简风格、科技感、品牌调性这些抽象概念都精准还原出来。
提示词:电影级镜头,一个极简风格、带有特斯拉品牌标识的箱体以魔法般的方式开启,进行出一辆完整成型的特斯拉汽车,同时其周围瞬间组成了一个流线型、特斯拉主题的展厅。画面中不出现任何文字。电影感,固定视角镜头,在关键热点进行重点的聚焦推进;可控的高频灯光布局,从昏暗逐渐过渡到明亮、干净;空旷的未来感空间,逐步转变为极简风格的特斯拉展厅,元素包括带发光盒子的特斯拉品牌箱体、特斯拉汽车(如Model 3 / Model Y / Cybertruck)、充电桩、极简展示面板、流线型展厅家具、环境占用灯光元素;箱体面板顺滑、安静地收回,车辆陈列;展厅要点精准且迅速升起、展开并完成结构;竣工画面整洁、纯粹、汽车占地的展厅,作为画面中心。
测下来整体感觉,Seedance 1.5 pro生成效果还是稳定靠谱的。
用过AI视频生成的朋友都知道,输入同样的提示词,往往需要生成多次,才能在一堆崩坏的画面里挑出一个能用的,这就是所谓的“抽卡”。
在 Seedance 1.5 Pro 测试中,它表现出了极高的指令遵循度,基本不需要反复「抽卡」,甚至我们还发现,往往第一次生成的视频效果就是最佳的,后续为了追求更好而反复重试的版本,反而在自然度和逻辑性上初不如版本。
总之,对于日常内容创作、轻量级商业广告以及AI短剧制作,Seedance 1.5 Pro完全够用。
Seedance 1.5 专业版:最初音视频联合生成的更优解
在多个场景的实测中,Seedance 1.5 pro在多语言与方言调整、运动表现力、镜头调度、整体视听一致性等多个关键指标上的表现给我们留下了深刻的印象。
这让我们更加好奇,近日于前代 Seedance 1.0 pro,新版本在底层能力上实现了哪些设想的突破?
作为字节跳动豆包大模型团队(以下是团队)的最新视频生成基础模型,Seedance 1.5 Pro在架构层面即初步支持音视频联合生成,包括文本到音视频生成和基于图像引导的音视频生成。

技术报告地址:https://arxiv.org/pdf/2512.13507
在实现过程中,Seedance 1.5 pro融合了几项关键技术创新,包括统一的多模态联合生成架构、全面的音视频数据框架、精细化的后期训练优化策略和高效的推理加速方案,从而在架构范式、数据工程、训练策略与系统效率等方面形成了系统性优化。我们接下来一一来看。
首先在框架层面,团队提出了一个基于MMDiT架构的统一建模框架,是实现原生音视频联合生成的重要基础。
该框架支持跨模态的深度交互,确保视觉与听觉信号实现时间维度上的精准同步以及语义层面的以及高度一致。另外通过在大规模混合模态集数据上进行多任务预训练,模型在不同类型的下游任务中执行出良好的泛化能力,包括文本音视频、图像生成音视频生成单态模的视频生成。
其次在数据层面,团队构建了一套面向高质量视频视频生成的整体数据框架。
该框架涵盖了多阶段数据筛选与清洗、先进的数据标注系统以及可高效规模化的基础。这套数据管道以实现音画一致、运动表现力和基于课程学习的数据调度为核心目标,配套的数据标注系统能够为音视频模态提供丰富、专业水准的基础。同时,整个框架依托描述的工程架构,针对大规模数据处理进行了深度优化。
接下来的训练阶段,团队在高质量的音频视频数据集上进行了监督校正(SFT),并引入了基于人类反馈的强化学习(RLHF)算法的音频视频场景定制。
具体来说,团队利用多维度奖励模型有效提升了文本到视频和图像到视频生成任务的整体表现,在运动质量、视觉美感和音频保真度等方面取得了明显提升。同时,针对RLHF训练流程进行了专门的工程优化,使整体训练速度提升近三倍。
最后在推理阶段,团队进一步优化了多阶段升级框架,显着降低了生成过程中所需要的函数评估次数(NFE)。同时结合量化、精度计算等推理基础层面设施的优化,在保持模型性能的前提下,实现了10倍+的最终推理加速。
下图为 Seedance 1.5 pro 的整体训练推送流程,其中通过「联合预训练 + SFT+RLHF」学习音视频生成能力,并在推理阶段以「统一文本条件」驱动音视频联合生成与精修,最终输出质量、强同步、高可控的音视频内容。
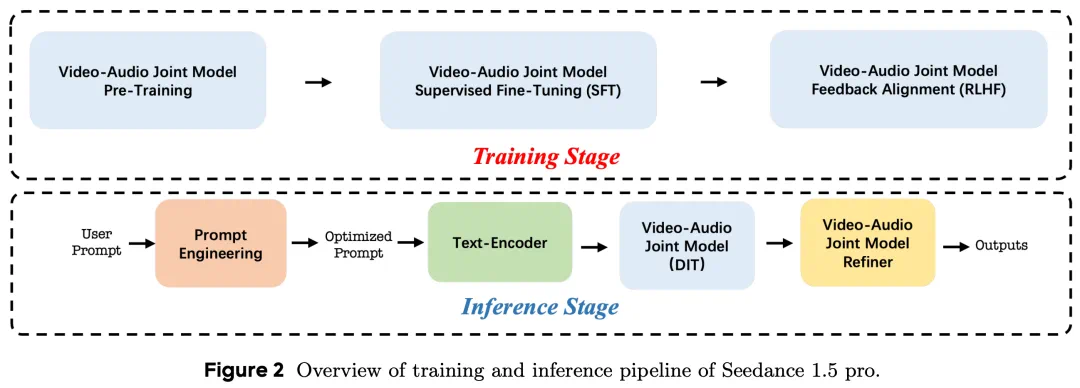
这一系列技术突破带来了音频视频生成能力的代际提升,为 Seedance 1.5 pro 在实例核心生成任务中的领先表现奠定了基础。
下图 3 和图 4 分别展示了 Seedance 1.5 pro 与前代 Seedance 1.0 pro、其他竞品模型在 T2V 和 I2V 任务中的性能比较结果。在 T2V 生成任务中,Seedance 1.5 Pro 在方向遵循(垂直度)指标上取得了前面的表现,在画面美感、运动质量等指标上也证明了对抗。在 I2V 任务中,Seedance 1.5 Pro 1.5 Pro同样保持了稳定而突出的整体表现。
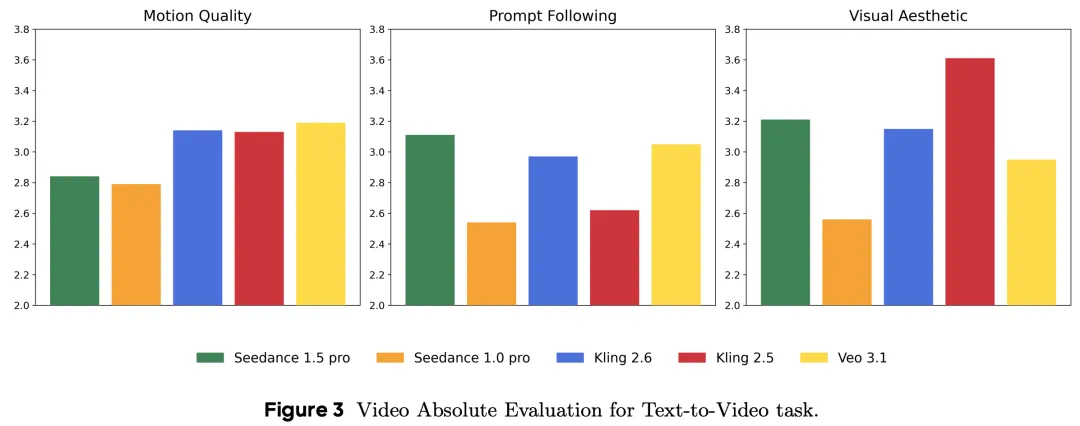
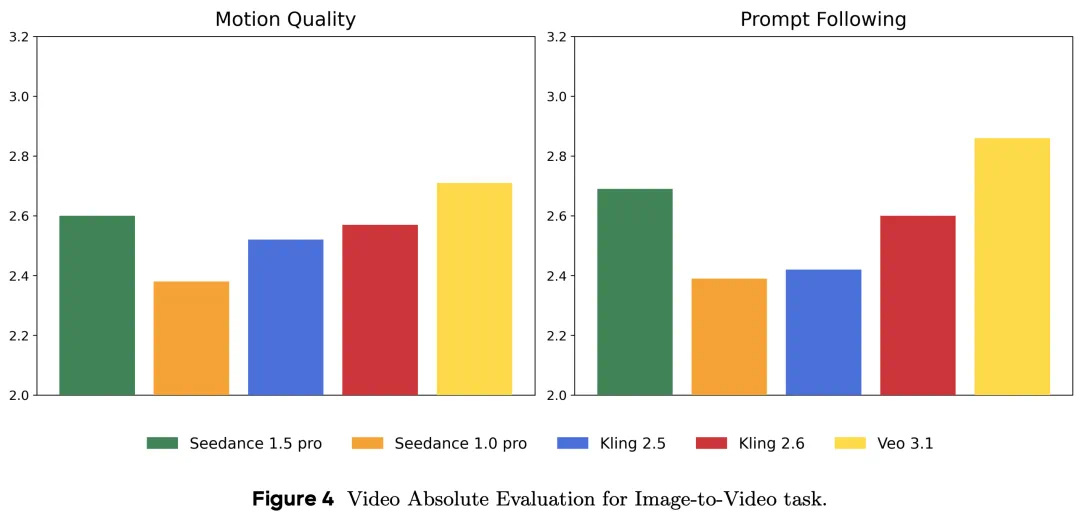
可以说,从Seedance 1.0 pro到1.5 pro,最大的技术进步不在于一点能力的增强,而是完成了从视频生成模型到原始音视频联合生成基础模型的跃迁。
写在最后
而Seedance 1.5 pro的亮眼表现,正是自2024年初以Sora为代表的产品级模型亮相以来,视频生成领域快速演进了一个缩影。在不到两年的时间里,视频生成技术便从学界的研究热点迅速走入大众视野,成为普通人也能洞察感受和使用的创作工具。
几乎每一次重磅模型的发布,都是在刷新人们对「AI视频可以进化到什么程度」的认知,并带来超出预期的体验。
如今,从生成时长、主体物理一致性到音画同步、镜头连续性,一个技术难点被攻克;再加上首尾帧约束、参考角色、分镜控制等更多样玩法的出现,视频生成了数十次迈过「人类直觉」的阶段,并开始真正迈向「创作级、生产级」阶段。借助 AI 视频创作工具,几个人甚至单人小团队就可以完成过去需要影视工作室的内容才能完成的视频。
作为该领域技术进步与玩法拓展的重要参与者,火山引擎Seedance系列视频生成模型虽然问世不长,但一直是战场关注的焦点之一。1.5 Pro在补全模型能力的同时,加快了系统化竞争的幅度。新版本在可玩性、实用性上显着提升,持续缩小模型输出与真实视频制作需求之间的差距。此外,通过API对外开放时间,为模型能力的规模化调用与工程化落地提供稳定的基础设施支持。
目前,Seedance 1.5 pro正在多样化的视频生成场景释放巨大的应用潜力,尤其是多镜头视频生成的实际制作。这意味着,该模型在更能满足日常创意表达需求之外,逐步向支撑专业级视频内容创作转变。
在即将到来的2026年,人们对视频生成领域有着更高的期待。马斯克曾表示,希望其推出的大模型Grok能在明年年底前叠加至少能看的电影,到2027年能制作出真正好看的电影。

我们无法准确地判断预算的设想是否能够如期实现,但可以预见的是,在未来的视频生产体系中,包括 Seedance 1.5 pro 内的视频生成大模型将以更加成熟的方式参与从创意生成到内容制作的全过程,它们的使用比重将继续提升,承担的角色也更加重要。


