当AI遇上复杂网络搜索
随着大型语言模型(LLM)的快速发展,AI Agent的能力边界不断扩展。网络搜索Agent作为这一发展的重要组成部分,能够自主地从广泛的在线资源中检索信息。然而,现有的开源网络Agent在处理复杂搜索任务时表现有限,而更强大的商业模型又缺乏透明的训练细节。人工智能需要在多个网站间进行复杂的推理和搜索,这正是长视野(Long-Horizon)网络Agent面临的挑战。
近日,香港科技大学(HKUST)与AI公司MiniMax的联合团队,在arXiv上发表了一篇题为
《WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents》的论文,直指Web Agent当前问题核心:不是模型参数不够多,而是缺乏足够有挑战性的训练数据。
研究者提出了一种构建高质量QA对的方法,将这些数据用于模型训练之后的结果表明,即使是较小的模型,也可以在复杂、长程的搜索任务上超越更大的模型。
核心挑战:优质训练数据的稀缺
近年来,随着大型语言模型(LLM)的快速发展,AIAgent的能力边界不断扩展。网络搜索Agent作为这一发展的重要组成部分,能够自主地从广泛的在线资源中检索信息。然而,现有的开源网络Agent在处理复杂搜索任务时表现有限,而更强大的商业模型又缺乏透明的训练细节。人工智能需要在多个网站间进行复杂的推理和搜索,这正是长视野(Long-Horizon)网络Agent面临的挑战。
WebExplorer论文的作者们发现,开发高能力网络Agent的根本挑战在于训练数据的质量。当前的评测基准已经发展到了极其困难的程度——例如,在BrowseComp-en基准测试中,超过一半的问题连人类标注者都无法在两小时内解决。虽然这样的难题在典型用例中很少见,但构建高质量、困难的问答对对于开发能够实现超人性能的信息搜索Agent至关重要。
目前的常见方法都有局限性,可能带来不自然的查询表达和有限的合成灵活性。
创新解决方案:WebExplorer的探索-演化框架
第一阶段:模型驱动的探索
WebExplorer提出了一个新颖的两阶段方法来解决这些限制。第一阶段是模型驱动的探索(Model-Based Exploration),让模型更自主灵活地探索信息空间。
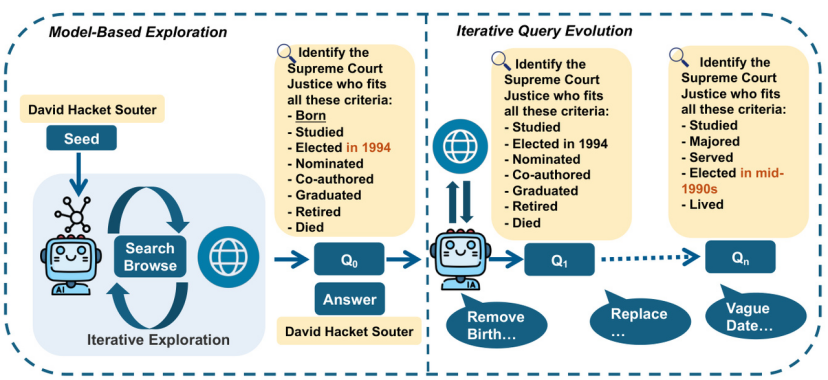
图1:WebExplorer核心框架示意图。从种子实体出发,LLM通过“搜索-浏览”迭代探索生成初始QA(Q0);再通过“移除信息、模糊细节”等操作,逐步进化出更具挑战性的QA(Q1到Qn),最终得到需要多步推理的训练数据。
具体来说,从一个种子实体开始,系统利用强大的LLM,通过迭代搜索和浏览操作来模拟图构建过程。这种方法能够灵活、动态地探索与种子实体相关的信息空间。基于这个初始的信息空间,模型再来构建初步问答对。
第二阶段:从长到短的查询演化
对于模型而言,初步问答对仍然相对简单。于是WebExplorer引入了第二阶段的迭代查询演化(Iterative Query Evolution)过程。
这一阶段的工作思路为:WebExplorer系统地移除明确线索和引入战略性模糊,来提高查询难度。这种方法采用"从长到短"的演化策略,通过以下三个战略方向改进查询:
1.移除显著信息:去掉过于明显的提示
2.引入战略性模糊化:对日期、地点和专有名词等具体细节进行模糊处理
3.寻找替代描述:用模糊的描述符替换原始的明确引用
例如,一个初始查询可能包含“这位球员44岁时去世”这样的明确信息,经过演化后变成模糊的描述如“这位球员于中年去世”,需要更多探索性搜索尝试才能到达正确答案。演化过程,也将解决问题所调用的工具次数从7.9增加到9.9。
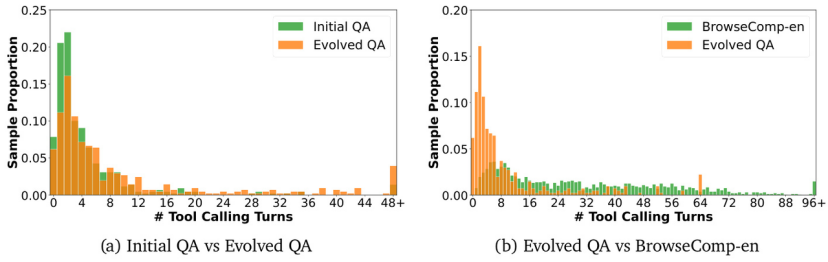
图2:工具调用次数分布比较。左图显示初始问答对vs演化问答对,右图显示演化问答对vs BrowseComp-en。演化过程显著增加了解决问题所需的工具调用次数,表明查询变得更加困难。
通过这个探索-演化过程,研究者构建了WebExplorer-QA数据集,包含大约4万个演化后的最终问答对。为了验证数据质量,他们使用Claude-4-Sonnet模型进行了全面的比较分析。
结果显示,演化过程的效果显著:准确率从86.6%大幅下降到67.1%,而解决问题的平均工具调用次数从7.9次显著增加到9.9次。这表明演化过程成功创建了需要广泛多步推理和探索的复杂查询。
研究者使用得到的WebExplorer-QA,使用SFT与RL两段式的经典训练法,模型出8B大小的WebExplorer-8B。该模型在多个信息搜索基准测试中取得了同等规模下的最先进性能。
实验结果:小模型的大成就
WebExplorer-8B基于Qwen3-8B模型训练,实现了支持128K上下文长度和100次工具调用的长视野推理,在多个基准测试中,达到了同等规模模型的最优成绩。
更令人惊讶的是,尽管只有8B参数,WebExplorer-8B在多个基准测试中持续超越了更大的开源模型。作为一个 8B 规模的模型,WebExplorer-8B 在强化学习训练后能够平均高效搜索 16 轮,在 BrowseComp-en/zh 上实现了比 WebSailor-72B 更高的准确率,并在 WebWalkerQA 和 FRAMES 数据集上取得了高达 100B 参数模型中的最佳性能。
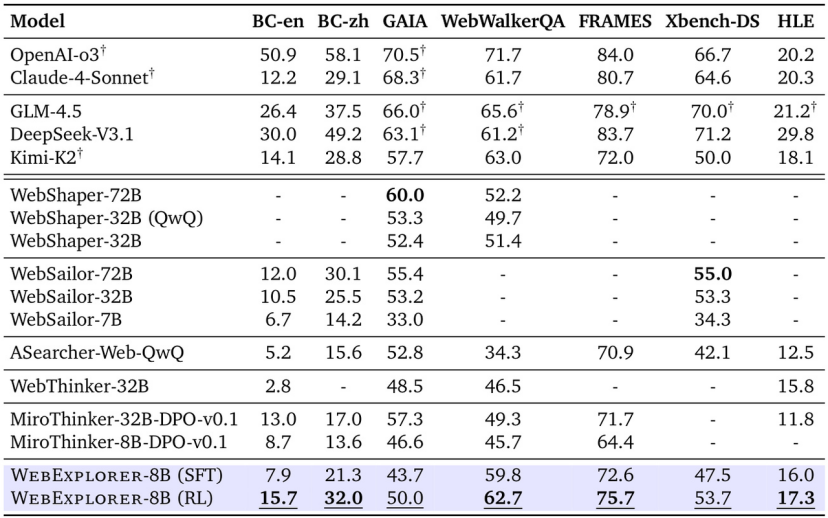
图3:WebExplorer-8B在BrowseComp-en、BrowseComp-zh和HLE基准测试中的性能比较。尽管参数规模较小,但在多个测试中都取得了最佳性能。
值得注意的是,尽管WebExplorer的问答对合成方法受到BrowseComp-en的启发,但该模型在不同基准测试和领域中都表现出了有效的泛化能力。更令人印象深刻的是,尽管训练数据并非专注于STEM领域,该模型在学术前沿基准HLE上取得了17.3%的成绩,超越了之前的32B模型,进一步验证了这种方法的稳健性和可转移性。
WebExplorer为训练高级网络Agent提供了一条实用的路径。证明了通过精心设计的数据合成方法和训练策略,较小的模型可以在复杂任务上超越更大的模型。这种参数效率对于AI技术的实际应用和部署具有重要意义,特别是在资源受限的环境中。
WebExplorer方法的成功还表明,对于复杂的推理任务,数据质量可能比模型规模更为重要。通过系统地构建需要多步推理的挑战性问答对,研究者能够训练出在长视野任务中表现卓越的Agent。
论文地址:https://arxiv.org/abs/2509.06501
Github:https://github.com/hkust-nlp/WebExplorer


