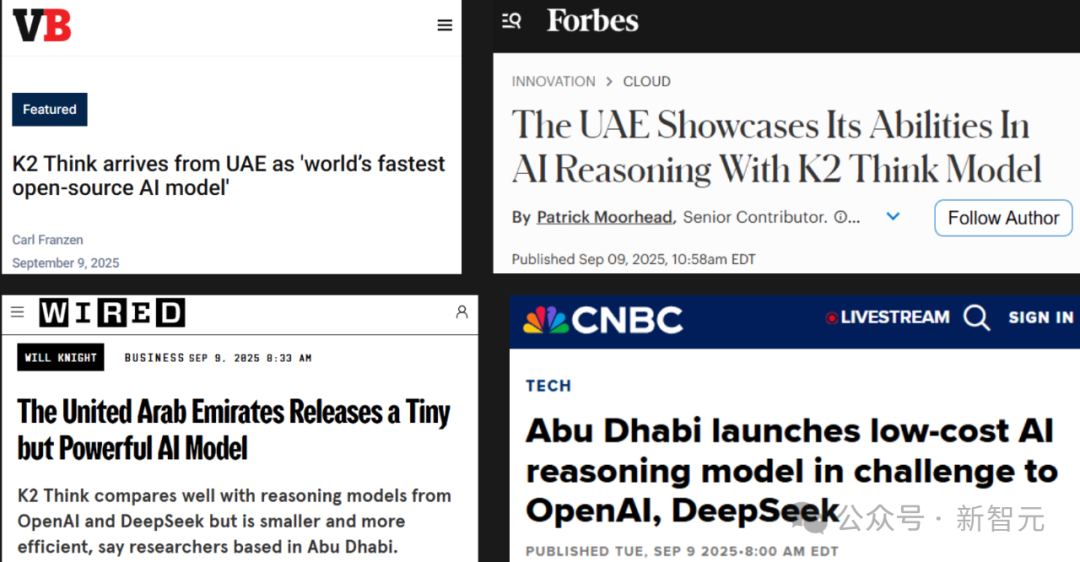
全球最快开源AI推理模型!
这个标签为K2‑Think带来轰动效果:福布斯、VentureBeat、Wired、CNBC等媒体争先报道,甚至图灵奖得主转发相关推文介绍!
然而,苏黎世联邦理工学院计算机科学系SRI实验室的研究者,却泼了一盆冷水:
虽然K2-Think不错,但报告的性能被夸大了。
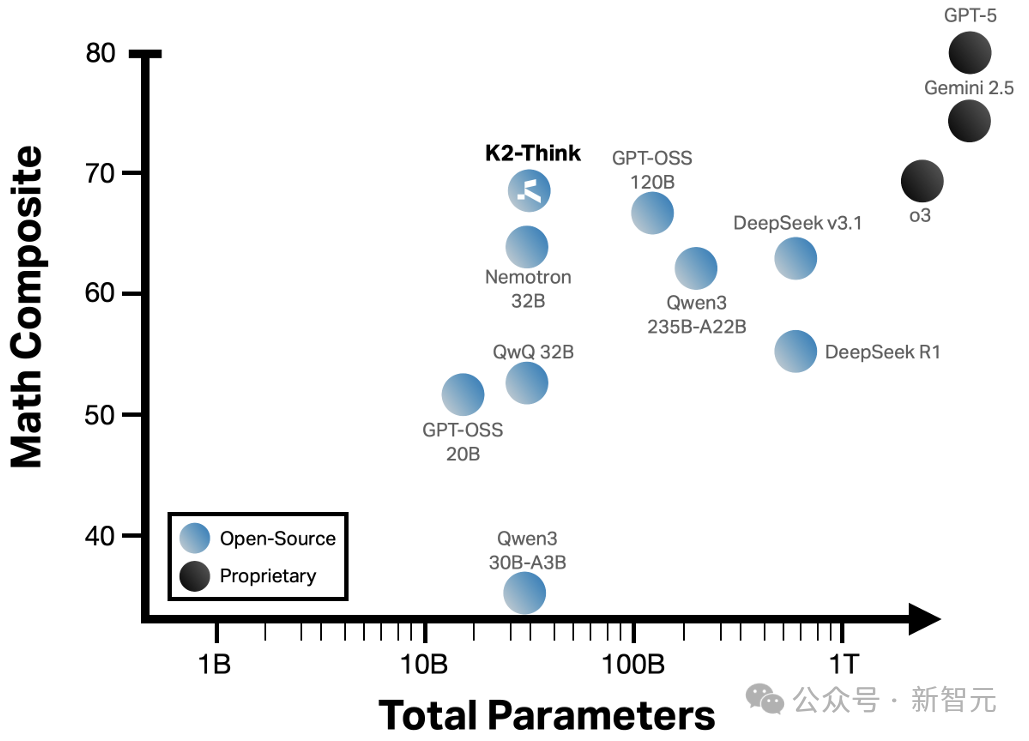
32B参数比肩o3 high?
上周,MBZUAI与G42等开源了一款号称是「全球最快的开源AI推理模型」——K2-Think。

当地媒体报道:K2-Think证明提升效率,不必牺牲模型性能
在数学能力上,只有32B参数的K2-Think,甚至能比肩OpenAI此前的旗舰——o3 high。
堪称是对Scaling Law的颠覆。
论文中,作者把六个没人费心整合过的技术诀窍组合到了一起:
长思维链微调、具有可验证奖励的强化学习(RLVR)、推理前的Agentic规划、测试时扩展、投机解码和优化推理的硬件。
其中的「先计划再思考」的架构不仅让模型变得更聪明,还实实在在地把token消耗降低了12%。
数据方面,据称仅使用开源数据集,无专有训练数据、无封闭API。
速度方面,它能在Cerebras上跑到每秒2000个token。而大部分推理模型,每秒只有200个token。复杂的证明,过去要等3分钟,现在只要18秒,这就是差距。
基准跑分更是逆天。
在AIME 2024测试中,它得分率高达90.83%,要知道,大多数前沿模型连85%的门槛都过不了。
在复杂的数学竞赛中,它拿下了了67.99%的分数——一举击败了那些参数量超过1000亿的模型,如GPT-OSS 120B 和DeepSeek V3.1。
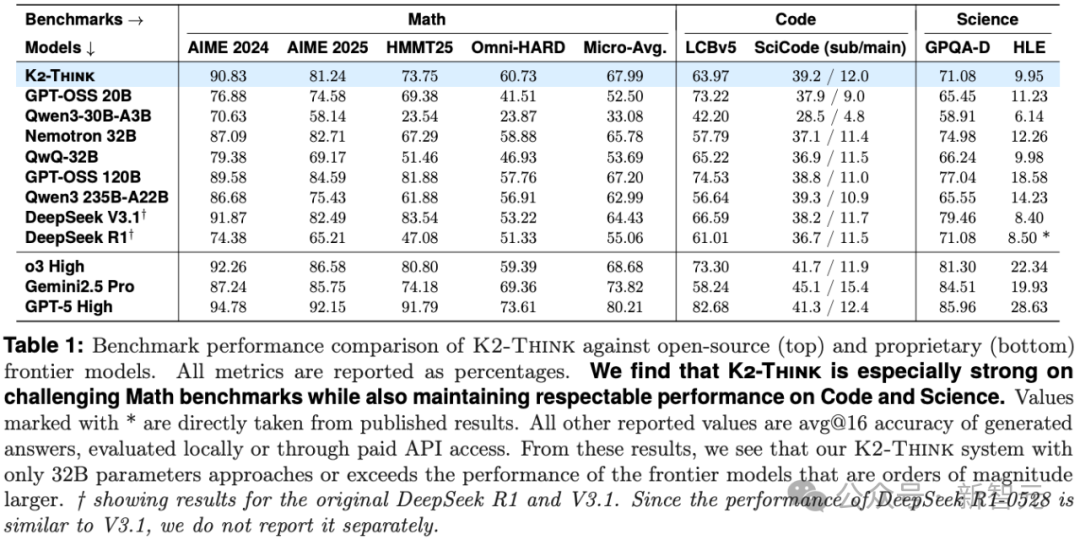
过去,大家都认为「模型越大越好」;这一下就彻底终结了这种论调。此前被OpenAI独占的推理能力,现在小型实验室也能部署了。
现在所有人都在惊叹它的速度记录。但真正的核心是:在推理层面,他们把参数效率这个难题给攻克了。
效果如此出色,不仅在网上引发了广泛关注,还有多家新闻媒体对此进行了报道,包括福布斯、VentureBeat、Wired、CNBC等。
甚至,连Yann LeCun都亲自下场,转发了一条介绍这篇论文的推文。
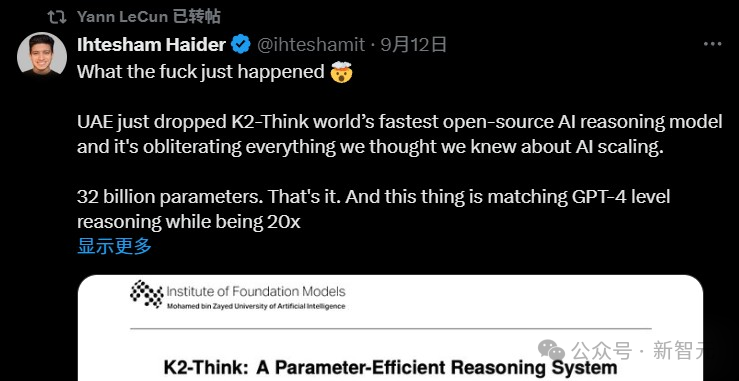

然而,3天后,9月12日,故事迎来了逆转!
逆转:ETH发文遭「打假」
然而,就在论文发布后的第3天,5位来自ETH苏黎世的研究员就出来「打假」了。

博客地址:https://www.sri.inf.ethz.ch/blog/k2think
根据分析,他们列出了4个关键问题:
- 数据污染
- 以三打一
- 只比旧模型
- 平均分替代最高分
具体问题,请往下看;ETH的独立测评和结论在文末。
数据污染,评估无效
在数学能力评估方面,K2-Think所使用的监督式微调(SFT)和强化学习(RL)数据集中,均包含DeepScaleR数据集,而后者又包含了Omni-Math的题目。
由于K2-Think又使用Omni-Math来评估其性能,评测与训练集可能存在重叠——这表明存在数据污染。
通过近似字符串匹配,研究人员确认了这一点:
K2-Think用于评估的173个Omni-Math题目,至少有87个也出现在其训练数据里。
另据称,RL数据集Guru的创建者与论文作者重合度高,而K2-Think又使用了Guru进行强化学习训练。
在代码基准LiveCodeBench评估中,也发现了类似问题。
评估中K2-Think所用样本的约22%,出现在其SFT数据集中。
虽然SFT数据集的原作者(AM-Team)执行了去污染步骤,移除了2024年10月之后的问题。
但K2-Think的LiveCodeBench评估,却使用了自2024年7月以来的所有问题,导致其中22%的问题是模型在训练阶段就已经见过的。
这直接导致其在数学和代码方面的评估结果大打折扣。
不公平比较:采用「Best-of-N」和外部模型
该论文的主要结果表报告的是,K2-Think在「3选1」(Best-of-3)策略下的性能。这是一种众所周知的提升模型表现的技巧。
而所有其他模型均采用「单次生成」(best-of-1)进行评估,这让它们处于极为不利的位置。
更甚的是,「3选1」的判断是由一个未指明的「外部模型」完成的,该模型的规模可能是任意的。
同样是这个外部模型,还为K2-Think提供了详细的解题计划。
作者将这整套流程定义为「K2-Think」,而32B模型本身只是其中一个组件。但原论文却声明「K2-Think仅依赖一个32B小模型」。

如论文所示,将这套流程与没有采用该流程的其他模型进行比较,是无效的。
这套流程本就可以轻松应用于其他模型,并同样能提升其得分。
在没有外部辅助的情况下,K2-Think的性能不如Nemotron 32B——
后者是一个同等规模的模型,于今年7月发布,基于Qwen2.5 32B并采用类似方法训练。

表1:K2-Think(无外部辅助)、Nemotron 32B(两者均为Qwen2.5 32B的微调版本)以及Qwen3 30B的性能对比。Qwen3(*)的结果取自其模型页面。所有其他结果均取自K2-Think的论文
歪曲其他模型的结果
该报告未能公正地评估其他模型。最明显的是,它在运行GPT-OSS时仅使用了「中等」推理强度,而非为推理基准推荐的「高」推理强度设置。
此外,K2-Think对许多竞品模型使用了过时的版本。
例如,尽管他们评估了8月份发布的GPT-OSS,但论文中评估的Qwen3模型似乎并非7月份发布的最新版本。具体来说,在Qwen3和K2-Think论文都涵盖的三个基准测试(AIME 2025、HMMT 2025、GPQA-Diamond)上,K2-Think给出的Qwen3分数似乎与旧版本相符,比7月新版本报告的结果低了15-20%之多。
下表比较Qwen3官方报告的分数与K2-Think论文中给出的分数。
可以看到,K2-Think归于Qwen3-30B的分数远低于预期,即便是对比7月发布前的旧版本也同样如此。
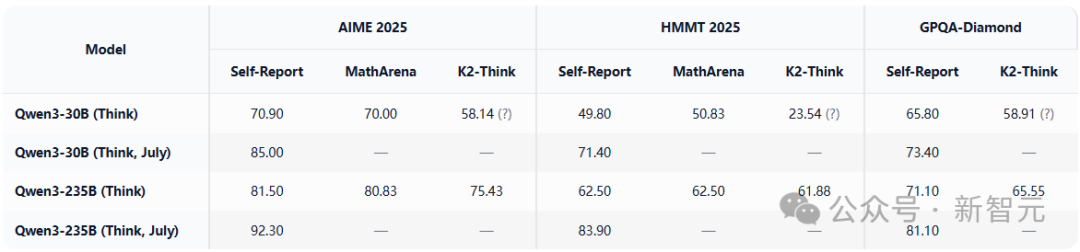
表2:在AIME 2025、HMMT 2025和GPQA-Diamond 3准上,Qwen3技术报告/模型页面、MathArena基准与K2-Think论文报告的分数对比
为得分高的数学基准赋予更高权重
最后,K2-Think使用「微观平均值」(micro average)来计算其总体数学评分。
这意味着它根据四个基准(AIME24、AIME25、HMMT、OmniMath-Hard)各自包含的任务数量来加权,而非对各基准分数进行等权重平均。

总体「微观平均值」:基本上是将所有测试集中的正确答案总数除以问题总数
虽然声称此举是为了量化模型的整体数学能力,但这种计算方式导致最终分数被OmniMath-Hard严重主导(占总分约66%)。
OmniMath-Hard不仅是K2-Think表现最好的基准,也恰恰是上文讨论的、存在数据污染问题的基准。
独立评估结果
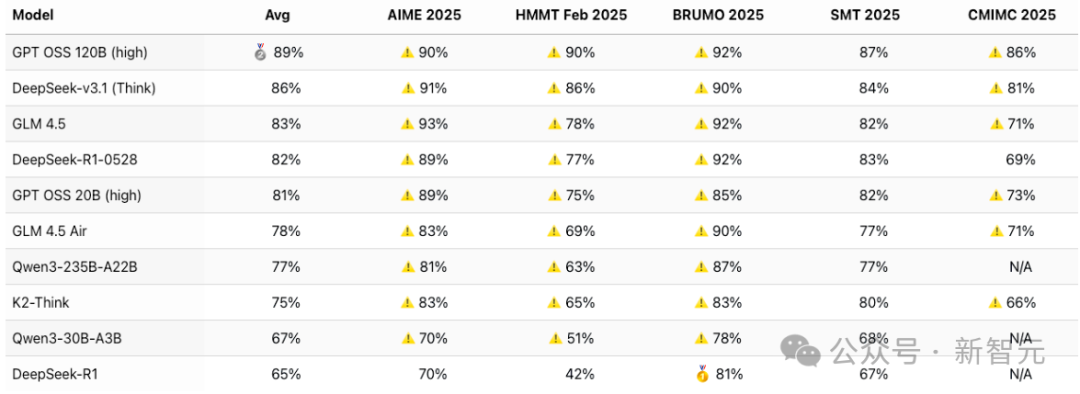
为ETH为了验证分析,在自有的MathArena基准上,对K2-Think与其他模型进行了公平比较。
他们遵循了K2-Think的推荐超参数(temperature=1, p=0.95,输出64,000个token)。
结果显示,尽管K2-Think性能不错,但其表现远未达到论文和媒体文章所声称的水平。
特别是,它未能与DeepSeek V3.1或GPT-OSS 120B相提并论——尽管其作者声称可以。
事实上,评估表明K2-Think的数学能力甚至不及规模更小的GPT-OSS 20B模型。
结论
总而言之,ETH的研究小组发现K2-Think模型在多个方面存在夸大陈述:
它在已经用于训练的数据上进行评估,依赖外部模型和额外采样来夸大性能,并人为压低竞品模型的分数,同时又通过重新加权来凸显自己的分数,以制造性能持平乃至超越的假象。
这也反映了AI圈独特的文化:针对不同的基准测试,好像只要能拿到最高分就是好模型。
这催生出一种极端的信念:好模型就是benchmaxer。
甚至为了刷新「SOTA」,出现了类似「田忌赛马」的测评策略。
开源模型要拿好成绩,本是好事。然而,存在缺陷的评估和夸大其词的宣传对行业毫无益处。


