在当前大型语言模型(LLM)快速发展的背景下,模型规模与计算资源需求之间的矛盾日益凸显。虽然大型语言模型展现出了卓越的性能,但其庞大的参数量和推理成本使其难以在资源受限的环境中部署。本文对最新发表在arXiv上的研究论文《Few-Shot Knowledge Distillation of LLMs With Counterfactual Explanations》进行深入分析,该论文提出了一种新颖的知识蒸馏方法,通过反事实解释(Counterfactual Explanations)增强少样本学习,实现了更高效的模型压缩。
研究背景与问题定义
知识蒸馏是一种将大型"教师"模型的知识转移到小型"学生"模型的技术,已成为模型压缩的主要方法之一。然而,传统的知识蒸馏方法通常需要大量数据,这在实际应用中可能难以获取或成本高昂。特别是在任务感知蒸馏(task-aware distillation)场景中,如何在极少量样本条件下有效地进行知识转移成为一个亟待解决的问题。
该研究聚焦于少样本任务感知知识蒸馏(few-shot task-aware knowledge distillation),旨在使用极少量的标记样本(通常为8-512个)从大型教师模型中提取知识到更小的学生模型中。研究的核心问题是:如何在数据极其有限的情况下,确保学生模型能够准确地模拟教师模型的决策边界?
创新方法:反事实解释注入蒸馏(CoD)
论文提出的核心方法是反事实解释注入蒸馏(Counterfactual-explanation-infused Distillation, CoD)。该方法的基本思想是通过系统地注入反事实解释来增强少样本蒸馏过程。反事实解释(CFE)是指能够以最小扰动翻转模型预测结果的输入变体。
方法流程
- 反事实解释生成对于每个原始样本,生成一个反事实变体,使其能够翻转教师模型的预测结果
- 数据增强将原始样本与其对应的反事实解释配对,形成增强的训练集
- 知识蒸馏使用增强的训练集进行知识蒸馏,学生模型同时学习原始样本和反事实样本的表示
具体实现上,作者采用了一种混合方法来生成反事实解释。他们使用GPT-4o作为生成器,根据输入和原始标签生成语义上合理的反事实样本,然后验证这些样本是否确实翻转了教师模型的预测。这种方法既保证了反事实样本的语义合理性,又确保了它们对教师模型决策边界的有效探测。
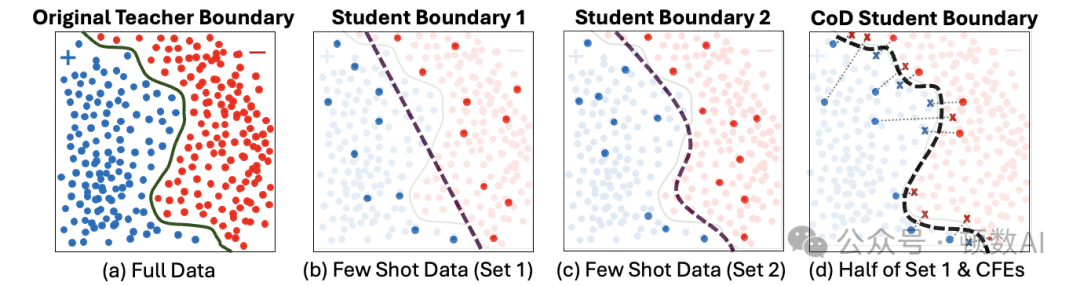 反事实解释示意图
反事实解释示意图
上图直观地展示了CoD方法的核心思想:(a)教师模型在完整数据集上训练的决策边界;(b-c)在少样本监督下,许多分类器可以拟合稀疏点,但学生边界(虚线)可能与教师边界不一致;(d)在蒸馏过程中将每个点与其反事实解释(×,链接到原始点)配对,使学生在这些点上匹配教师的软预测。反事实解释作为靠近边界的"锚点",将学生模型固定在教师的决策表面上,即使在少样本预算下也能产生更忠实的蒸馏效果。
理论基础
该研究提供了两个关键的理论视角来支持反事实解释在知识蒸馏中的作用:
1. 统计保证
在逻辑回归设置中,作者证明了反事实解释可以通过最大化Fisher信息来改进参数估计。具体来说,反事实样本通常位于决策边界附近,这些区域对模型参数估计贡献了更多信息。通过Fisher信息矩阵的分析,作者证明了使用反事实增强的数据集进行训练可以降低学生模型的预期估计误差。
2. 几何保证
从几何角度,作者引入了豪斯多夫距离(Hausdorff distance)来量化教师和学生决策边界之间的差异。他们证明,当学生模型在原始数据点和反事实点上都与教师模型匹配时,两者的决策边界将保持接近。具体来说,如果反事实样本对(x, x')的扰动幅度不超过α,且样本在决策边界上的分布满足ε-spread条件,那么教师和学生决策边界之间的豪斯多夫距离将不超过α+ε。
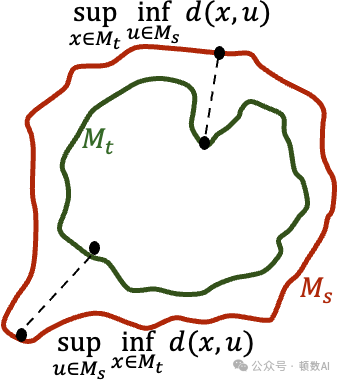 豪斯多夫距离示意图
豪斯多夫距离示意图
这一理论结果表明,反事实样本对有效地作为"锚点",将学生模型的决策边界"钉"在教师模型决策边界的附近,从而实现更准确的知识转移。
实验验证
作者在六个文本分类基准数据集上进行了广泛的实验,使用了两个主要的模型系列:DeBERTa-v3和Qwen2.5。实验设置包括不同的少样本规模(k = 8, 16, 32, 64, 128, 512)和不同的学生模型大小。
实验设置
- 教师模型:DeBERTa-v3-base(100M参数)和Qwen2.5-1.5B
- 学生模型:DeBERTa-v3-small(44M)、DeBERTa-v3-xsmall(22M)和Qwen2.5-0.5B
- 基线方法:标准知识蒸馏(KD)、层级蒸馏(LWD)和任务感知层级蒸馏(TED)
- 数据集:SST2、Sentiment140、IMDB、CoLA、Amazon Polarity和Yelp
为了公平比较,基线方法使用k个原始样本,而CoD方法使用k/2个原始样本和对应的k/2个反事实样本(总共仍为k个样本)。
主要结果
实验结果表明,CoD在少样本场景下显著优于现有的蒸馏方法,特别是在极低数据量(k ≤ 64)的情况下:
- 在Amazon Polarity数据集上,使用8个标记样本时,KD + CoD达到了75.8%的准确率,比标准KD的67.1%高出8.7个百分点。
- 在IMDB数据集上,k = 8时,LWD + CoD比标准LWD提高了10多个百分点(86.1% vs 76.0%)。
- 随着标记样本数量的增加,反事实增强的优势逐渐减小,但即使在k = 512的情况下,CoD仍能达到与标准方法相当的性能,同时只使用了一半的真实样本。
值得注意的是,CoD的有效性在不同数据集上表现不同。例如,在CoLA数据集上,CoD在所有k值下都表现出一致的改进,而在Sentiment140等数据集上,CoD在低k值时表现出更显著的优势。这表明反事实解释的有效性与任务的性质和决策边界的复杂性有关。
技术深入分析
反事实解释生成
生成高质量的反事实解释是CoD方法的关键步骤。作者采用了一种混合方法,结合了大型语言模型的生成能力和教师模型的验证机制:
复制这种方法解决了传统反事实生成方法在语言领域面临的挑战:优化或搜索方法在高维离散空间中效率低下,而纯生成方法可能产生语义不合理或偏离原始分布的样本。
蒸馏损失函数设计
CoD方法采用了多组件损失函数来指导学生模型的学习:
复制其中:
- L_hard是基于硬标签的交叉熵损失
- L_KD是基于教师软标签的KL散度损失
- L_LWD是层级对齐损失(对于使用LWD的变体)
- α和β是平衡不同损失组件的超参数
在实验中,作者发现软标签校准对于反事实样本的有效性至关重要。当移除软标签项(α=0)时,虽然CoD仍然优于基线,但性能提升显著减少。这表明教师模型提供的软标签是反事实解释数据有效性的关键贡献因素。
应用前景与局限性
应用前景
- 低资源场景:CoD方法特别适用于标记数据稀缺或获取成本高昂的场景,如医疗、法律等专业领域。
- 边缘设备部署:通过高效的知识蒸馏,可以将大型语言模型的能力压缩到更小的模型中,使其能够在资源受限的边缘设备上运行。
- 隐私敏感应用:在需要本地处理数据以保护隐私的场景中,小型但高性能的模型尤为重要。
- 扩展到生成式模型:虽然当前研究主要集中在分类任务上,但作者指出该方法可以扩展到生成式序列到序列模型,实现更广泛的应用。
局限性
- 计算开销:生成反事实解释引入了额外的计算开销,特别是当使用大型语言模型作为生成器时。
- 反事实质量:当前的反事实生成策略依赖于提示大型语言模型,无法保证生成的是最接近决策边界的反事实样本。
- 教师模型依赖:CoD方法的有效性依赖于教师模型的质量,如果教师模型存在偏差或不准确性,这些问题可能会被继承到学生模型中。
未来展望
基于该研究的创新点和局限性,未来的研究方向可以从以下几个方面展开:
1. 自适应反事实生成
开发能够根据任务特性和模型架构自动调整反事实生成策略的方法。例如,可以设计一个元学习框架,该框架能够学习为不同类型的输入生成最优反事实样本的策略,从而提高反事实样本的质量和多样性。具体实现上,可以探索基于梯度的方法与生成模型的结合,在保证语义合理性的同时最大化决策边界信息。
2. 多模态反事实蒸馏
将CoD方法扩展到多模态场景,如视觉-语言模型。在这种情况下,反事实解释可能涉及对图像和文本的联合修改,以翻转模型的预测。这需要开发新的反事实生成技术,能够在保持跨模态一致性的同时进行最小必要的修改。
3. 连续学习与增量蒸馏
研究如何在连续学习场景中应用CoD方法,使学生模型能够从不断更新的教师模型中高效地学习新知识,同时保留已学习的能力。这可能需要设计特定的反事实样本选择策略,以平衡新旧知识的转移。
4. 反事实解释的理论深化
进一步探索反事实解释在知识蒸馏中的理论基础,特别是在非线性和高维场景下。例如,可以研究反事实样本在不同类型的神经网络架构中如何影响知识转移的效率,以及如何根据这些理论见解优化反事实样本的生成和选择。
5. 可解释性与鲁棒性的统一
探索反事实解释如何同时提高模型的可解释性和鲁棒性。由于反事实样本本质上揭示了模型决策边界的特性,它们可以用于解释模型决策,同时通过在这些边界区域增强训练来提高模型的鲁棒性。这种统一的框架可以同时解决AI系统中的两个关键挑战。
结论
反事实解释注入蒸馏(CoD)为少样本知识蒸馏提供了一种新颖而有效的方法。通过系统地注入反事实解释,CoD能够在极少量数据的情况下显著提高学生模型对教师模型决策边界的模拟能力。这一方法不仅在实验上展现出了优越的性能,还提供了坚实的理论基础,解释了为什么反事实样本能够提高知识转移的效率。
随着大型语言模型在各个领域的应用不断扩展,高效的模型压缩技术变得越来越重要。CoD方法通过桥接可解释性和模型压缩,为构建更小、更高效但同样强大的语言模型开辟了新的可能性。未来的研究可以进一步探索反事实解释在更广泛的模型架构和应用场景中的潜力,推动AI系统向更高效、更可解释的方向发展。
相关资源
- 论文链接:https://arxiv.org/abs/2510.21631
- 代码实现:https://github.com/FaisalHamman/CoD


