让模型先解释,再学Embedding!
来自UIUC、ANU、港科大、UW、TAMU等多所高校的研究人员,最新推出可解释的生成式Embedding框架——GRACE。

过去几年,文本表征(Text Embedding)模型经历了从BERT到E5、GTE、LLM2Vec,Qwen-Embedding等不断演进的浪潮。这些模型将文本映射为向量空间,用于语义检索、聚类、问答匹配等任务。
然而,大多数方法有一个共同缺陷:
它们把大语言模型当成“哑巴编码器”使用——输入文本,输出向量,却无法告诉我们为什么这两个文本相似。
这种 “对比学习+池化” 的做法虽然有效,但本质上抛弃了大语言模型(LLM) 的推理与生成能力,使得Embedding(嵌入)成为一个纯粹的统计结果。
而在需要高可解释性、高鲁棒性的任务中(例如问答匹配、跨域检索、推荐系统),这种黑箱式表征往往成为瓶颈。
对此,GRACE框架正是为解决上述瓶颈而生——
核心思想:把“对比学习”变成“强化学习”
GRACE的关键创新在于,重新定义对比学习信号的意义。
在传统范式中,InfoNCE是一种“惩罚式损失”(loss),即让正样本靠近,负样本远离;而在GRACE中,研究人员把它改造成一种“奖励”(reward),让模型主动学习如何解释相似性。
简单来说,GRACE不再是“把文本压成向量”,而是“让模型先解释,再学Embedding”——
模型首先生成每个文本的“推理说明(rationale)”,然后再将这些rationale编码成Embedding。奖励信号会鼓励模型产生更有逻辑、更语义一致的推理。
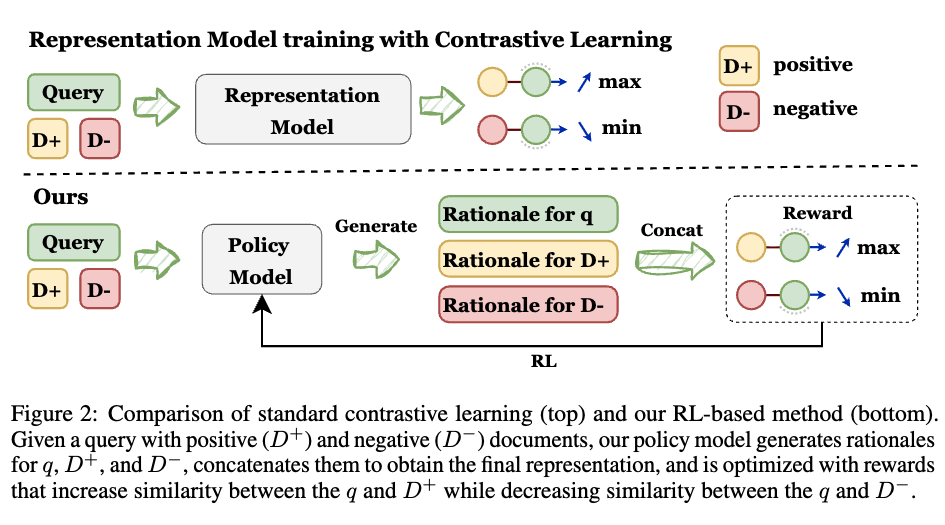
方法总览:生成、表征、优化三位一体
概括而言,GRACE包含三个关键模块:
1、Rationale-Generating Policy(生成式思维链)
模型首先对输入文本生成解释性推理链(rationale)。例如:“该段文本描述了对比学习的局限性,并提出了一种基于奖励优化的新方法。”
这些rationale是显式的自然语言输出,既增强模型理解力,又可直接审查其语义判断过程。
2、Representation Extraction(可解释表征)
在得到rationale后,模型把“输入+rationale”拼接,计算上下文隐藏状态,并进行Masked Mean Pooling得到最终Embedding。
这种Embedding既包含语义信息,又保留了reasoning trace,使得模型的表示空间更稳、更语义一致。
3、Contrastive Rewards(奖励驱动的学习目标)
研究人员把对比学习目标重新定义为奖励函数:
- R₁:Contrastive Reward:提升query与正样本相似度,惩罚负样本。
- R₂:Consistency Reward:不同生成的rationale要相似,防止不稳定。
- R₃:Hard Negative Reward:重点区分“最容易混淆”的负样本。
整体优化目标为,通过GRPO(Group Relative Policy Optimization)进行强化学习更新。同时,GRACE也可以适用于其他策略梯度的强化学习算法,效果依旧显著。
训练流程:有监督+无监督统一框架
GRACE既可以用带标签的query–document对训练(supervised),也可以无监督地自对齐(unsupervised)。
- 有监督阶段
基于公开的E5训练集(1.5M样本),模型学习query–positive–negative三元组的语义关系。
相比传统InfoNCE,GRACE通过生成式强化学习让每个pair都带有可解释reasoning。
- 无监督阶段
借鉴SimCSE思路,对每个文本生成多个rationale,互相作为正样本。奖励鼓励同一文本不同解释的表征一致,不同文本表征区分。
这种双模式统一,使GRACE可以适配任何预训练LLM,无需大规模新标注数据。
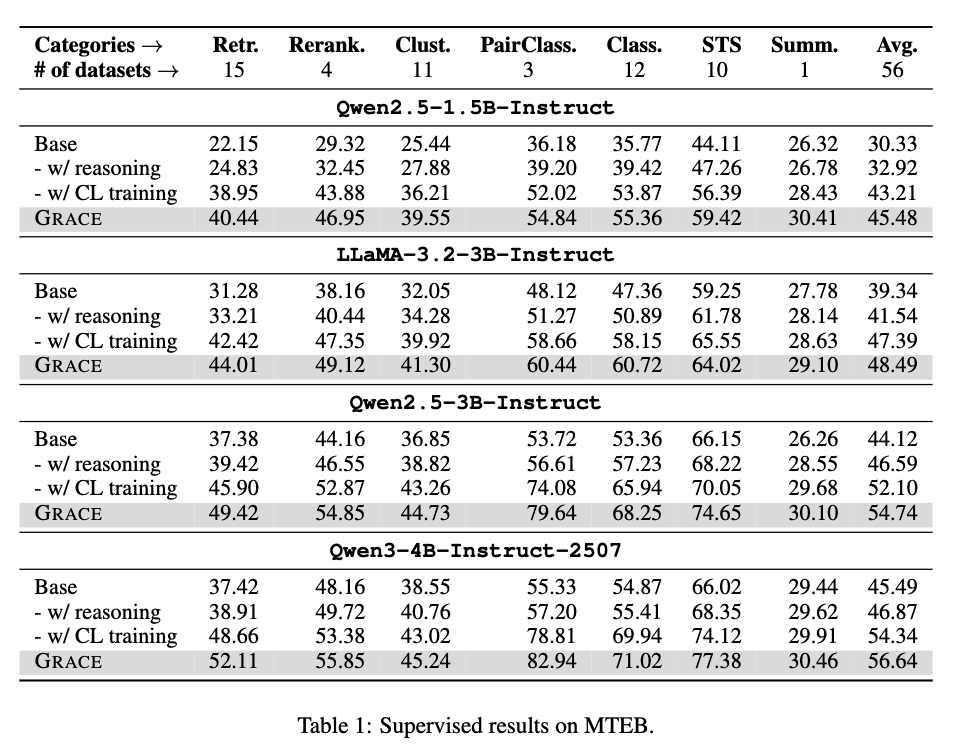
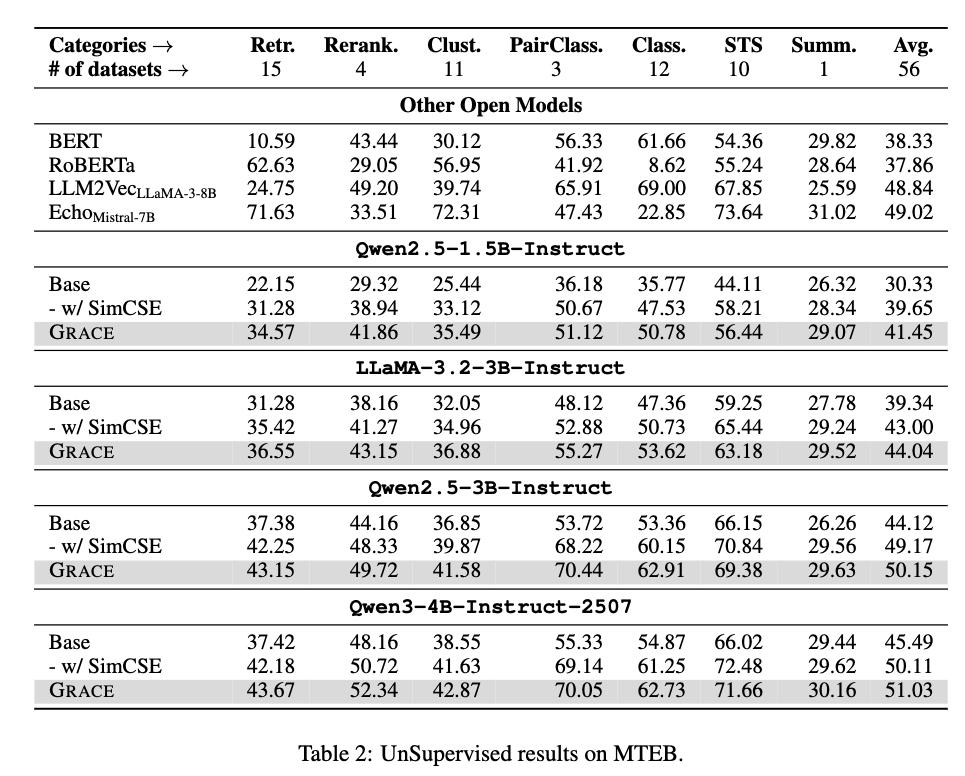
实验结果:跨任务全面提升
研究人员在MTEB全套56个数据集(含Retrieval、 Rerank、Clustering、STS、Classification、PairClass、Summarization)上全面评测。
共测试四个主流LLM骨干:
- Qwen2.5-1.5B / 3B
- LLaMA-3.2-3B
- Qwen3-4B
结果发现,GRACE不仅在平均得分上全面超越所有基线,在retrieval、pair classification、clustering等任务上更是显著领先。
此外,鉴于传统对比学习往往导致模型“过拟合语义空间”,损害生成与推理能力。
研究人员验证了GRACE在通用任务(GSM8K、MMLU、FEVER、BBH、HumanEval)上的影响,结果显示性能几乎无下降,Δ<0.5%,远好于InfoNCE基线的“灾难性遗忘”。
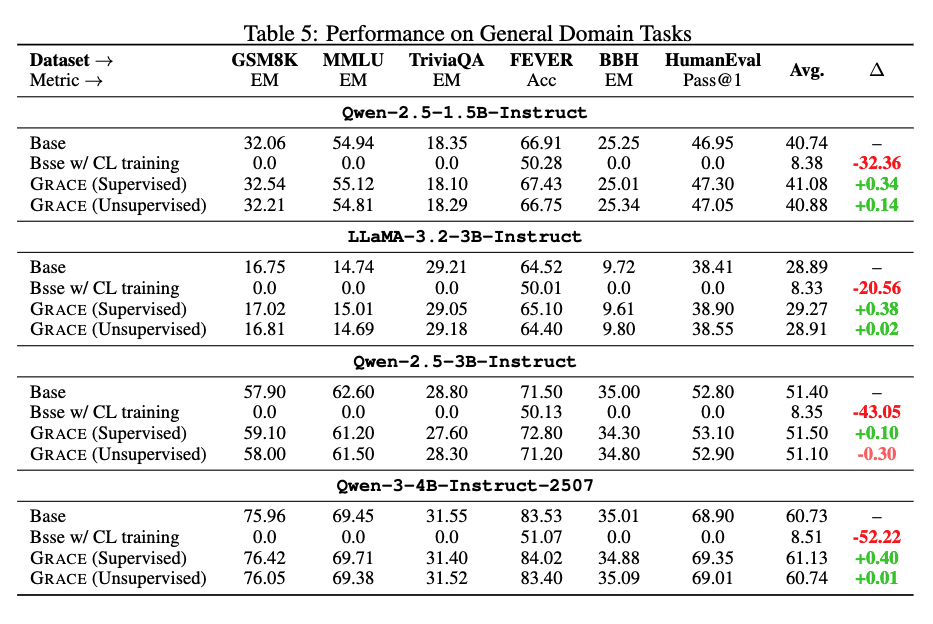
这意味着,GRACE在不损失生成能力的前提下,大幅提升嵌入能力。
同时,以往我们只能看到模型输出的Embedding,但无法理解它“认为这两个文本相似”的原因。
但GRACE改变了这一点:每个Embedding背后,都有一段生成式reasoning trace。
这让Embedding从黑箱向可审查的「透明表征」转变——用户不仅能“用”Embedding,还能“看懂”Embedding。
整体而言,GRACE提出了一种全新的生成式表征学习框架:
- 让LLM“先思考后生成”
- 用奖励而非损失驱动
- 同时获得强性能与高可解释性
团队表示,这不仅是Embedding模型的一次范式转变,更是迈向“能解释自身理解过程”的大模型的重要一步。
论文链接:https://arxiv.org/abs/2510.04506
代码与模型:https://github.com/GasolSun36/GRACE


