当下的神经机器翻译在主流语言间已接近人类水平,但在“弱语义+低资源”语言(如古文字、象形符号文字等)上仍面临巨大挑战。此类语言不仅缺乏标准的平行语料,还因符号语义模糊、语境依赖强而极难有效建模,导致传统神经模型翻译在这些场景下表现不稳定、可解释性差。
如何在语义极弱、资源极少的条件下实现高质量翻译,是跨语言智能理解中的长期难题。 为此,来自西南大学计算机与信息科学学院·软件学院的陈善雄教授研究与西南大学汉语言文学研究所李晓亮副教授合作,以中国西部地区语言培训纳西东巴文到现代机器翻译任务为先,在人工智能顶会——欧洲人工智能会议(ECAI 2025)上提出了创新的语义增强翻译框架——《SEWLT:语义》 《弱语义低资源语言翻译增强》,从语义图像对弱语义翻译问题进行了系统建模与优化。


论文标题:SEWLT: Semantic Enhancement for Weak Semantics Low-Resource Language Translation会议:ECAI 2025(The 28th European Conference on Artificial Intelligence)
背景与挑战:为什么弱语义语言如此难以翻译?
传统低资源翻译的研究多聚焦于文本数据量稀缺问题,而弱语义语言的困难在于更深层的语义结构缺失。以纳西东巴文为例,其符号常以图形表示概念,一个符号可代表事件、物体或情境,语义高度依赖上下文。主要挑战包括:语义稀疏、噪声干扰以及跨语言迁移困难,使得普通Transformer或预训练模型在此类翻译中性能显著下降。
方法:语义增强翻译框架SEWLT
弱语义低资源语言翻译普遍存在三重难题:
1.符号的语义分布离散、跨语言语义对齐困难,导致翻译模型难以学习稳定的语义映射。
2.平行数据稀缺且伪数据噪声高,容易引入错误对齐和语义漂移,削弱模型学习效果。
3.模型在持续学习过程中易遗忘旧知识,导致语义空间不稳定、跨轮次表现下降。
为应对上述挑战,SEWLT提出了三项创新机制:跨语言语义自适应(CLSA)、词替换的迭代反向翻译(IBT-WR)、增量学习与语义一致性约束模块(ILB)。三者形成“语义增强—数据扩充—知识保持”的协同结构,使模型能够在极低资源条件下实现稳定且高质量的语义翻译。
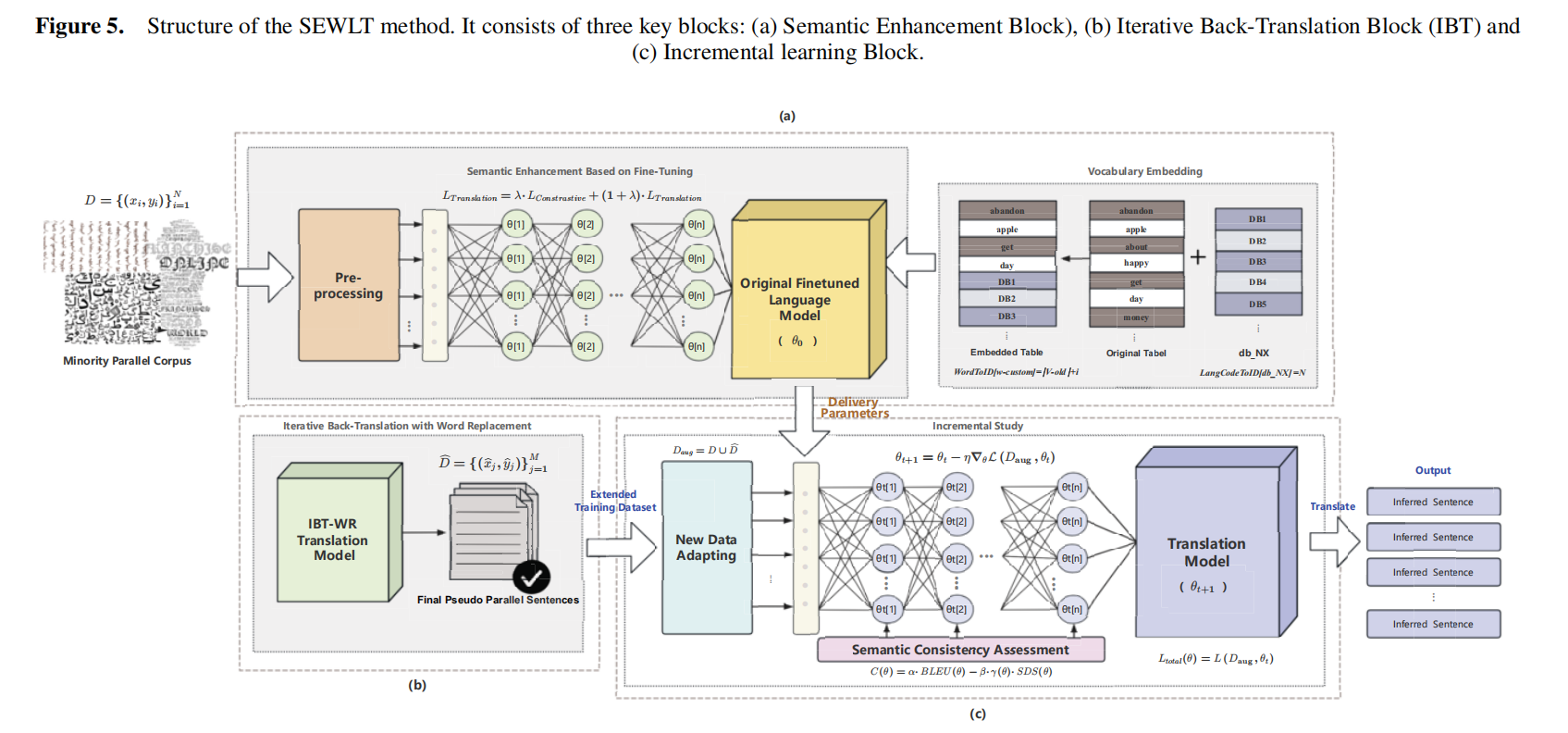
1、跨语言方法(CLSA)
在弱语义低资源场景下,符号语言与目标语言之间的语义空间存在显著差距。为此,SEWLT 引入 CLSA 模块,通过跨语言语义映射与对比学习机制,建立符号与文本之间的共享语义空间。
具体而言,CLSA 利用源语言和目标语言的语义嵌入,通过对齐损失函数最小化两种语言在特征空间的分布差异,使语义相关的符号和单词在高维空间中聚合。该模块不仅强化了符号与文本的语义对应关系,也减轻了语义漂移带来的翻译不稳定性。
2、基于词替换的迭代反向翻译方法(IBT-WR)
由于弱语义低资源语言语料极少,伪平行数据成为关键补充。IBT-WR 模块在此基础上进行自适应增强:通过词替换和语义约束的迭代反向翻译机制,逐步修正伪平行数据的语义偏差。
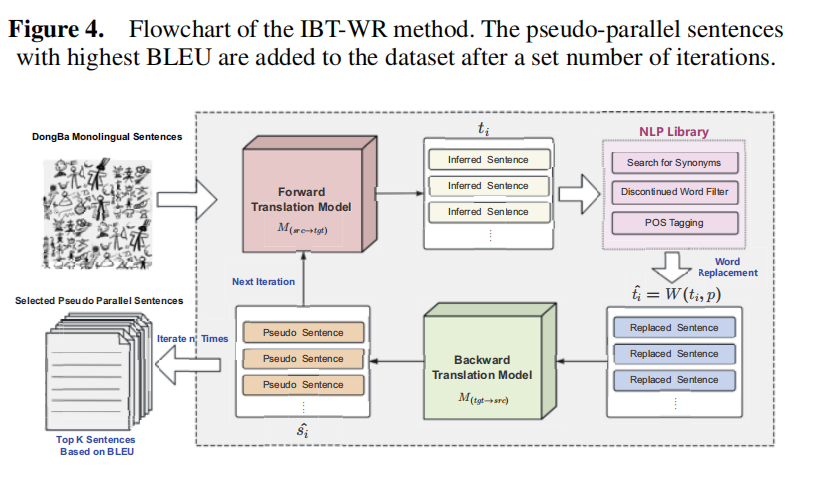
在每一轮迭代中,模型利用先前生成的译文执行反向翻译,并通过词义替换策略引入语义干扰,从而提升模型对模糊符号的语音能力。方法实现了语义一致性与数据多样性的动态平衡,显着提高了数据质量与模型泛化性。
3、增量学习与采购一致性合同
为防止模型在新语料注入时遗忘已有语义知识,SEWLT 结合了增量学习方法和语义一致性评估机制,使用 BLEU 分数来综合评估翻译质量。BLEU 分数持续上升表明泛化效果稳定,从而促使注入新的伪并行数据,以进一步丰富训练内容。相反,BLEU 分数停滞或下降则表明过度拟合或性能饱和,从而导致学习速度降低或提前停止。同时,模型计算语义偏差分(SDS),使得模型在增量训练过程中保持参数稳定性,实现可持续的语义学习。
实验与结果
在纳西东巴文—汉语翻译任务中,研究团队基于现有的东巴文资源,构建了一个弱语义平行语料集,包含真实采集的东巴文符号与人工对齐的汉语释义句对,并通过伪平行数据生成策略扩充至多层次训练集。
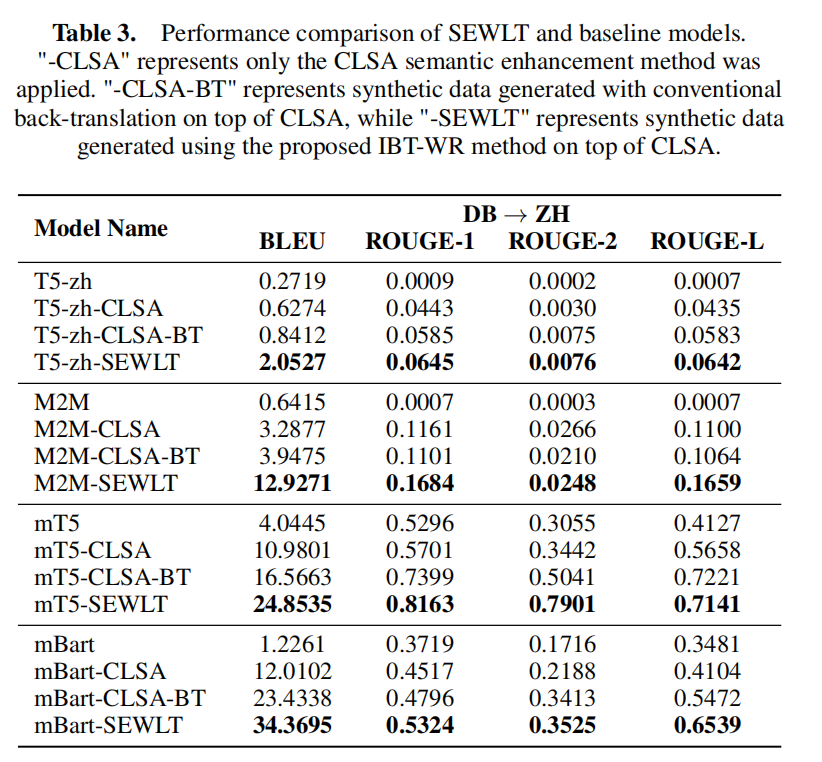
实验中,研究团队以 T5、M2M、mBART、mT5等多语言预训练模型作为对比基线,并在相同数据与参数规模下进行训练。模型性能通过 BLEU和ROUGE1-L等指标进行自动化评价,同时辅以专家评估与众包主观评测,包含专家与非专家对译文流畅性、语义完整性及文化可读性的双盲打分。
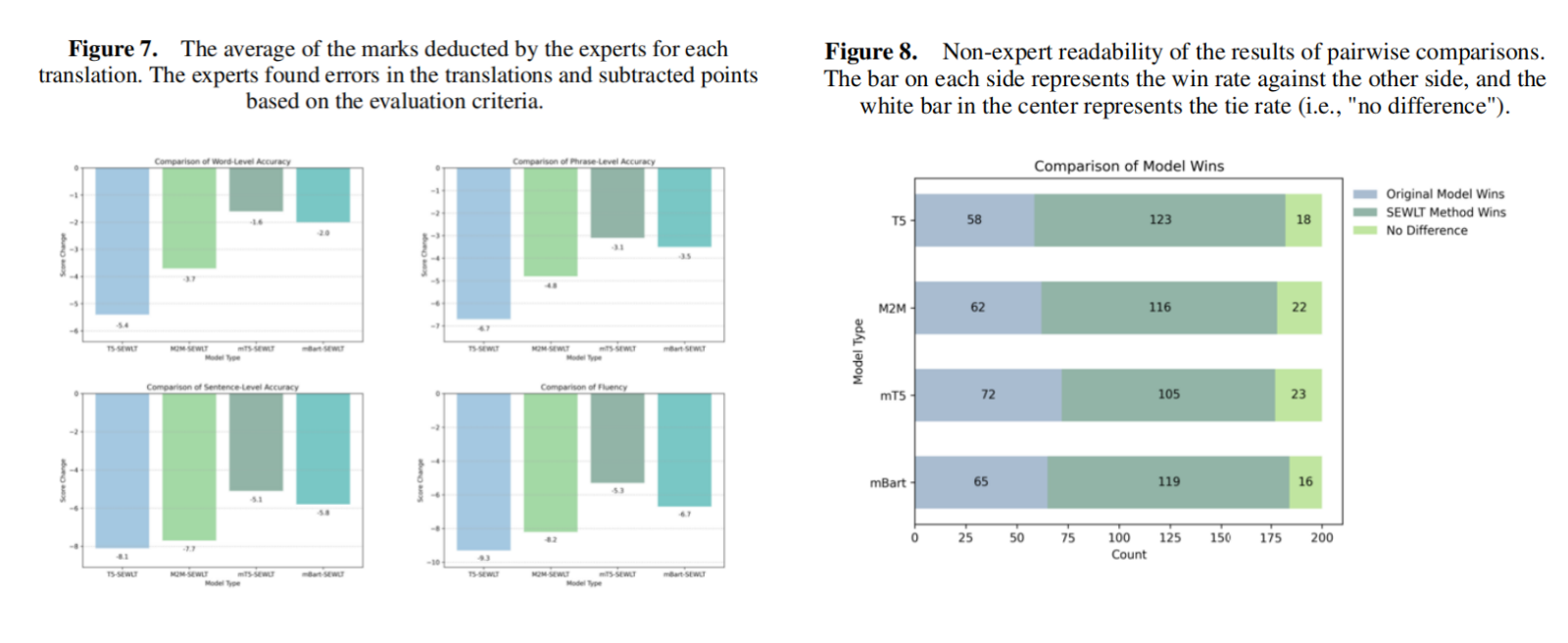
实验结果表明,SEWLT 在自动评估指标上均显著优于对比模型,分别平均提升 3.8–5.2 BLEU 与 4.6 ROUGE。专家在多个维度上的扣分评测指出,SEWLT 译文在语义完整性、流畅性及可读性方面明显优于传统模型。在众包评测中,约 62% 的受试者认为 SEWLT 的译文在语义连贯、上下文逻辑及句子可读性方面优于基线模型。
意义与展望
SEWLT 是首个针对弱语义低资源语言的系统性语义增强翻译框架,其设计理念兼具技术创新与文化价值。通过引入语义增强、语料扩充与持续增量学习机制,该框架为东巴文等古文字的数字化保护与智能理解提供了新方法。未来,研究团队计划将 SEWLT 扩展至更多类型的符号系统与跨模态任务,包括结合图像模态的符号翻译、跨文化语义生成与低资源知识迁移等方向。随着模型能力的提升,这一框架有望进一步推动濒危文字的数字化传承,为人类语言与文化多样性的保护提供技术支撑。


