论文作者团队简介:本文第一作者周鑫,共同第一作者梁定康,均为华中科技大学博士生,导师为白翔教授。合作者包括华中科技大学陈楷锦、冯天瑞、林鸿凯,旷视科技陈习武、丁宜康、谭飞杨和香港大学赵恒爽助理教授。

在HunyuanVideo上,EasyCache在复杂场景下保持与原视频的一致外观,同时显著加速
1. 研究背景与动机
近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。
但与此同时,推理慢、算力消耗高的问题也日益突出。以 HunyuanVideo 为例,生成一个 5 秒、720P 分辨率的视频,单次推理在单张 H20 上需要 2 小时。这种高昂的资源代价,极大限制了扩散视频生成技术在实时互动、移动端和大规模生产场景的应用落地。
造成这一瓶颈的核心原因,是扩散模型在生成过程中需要多次迭代去噪,每一步都要进行完整的神经网络前向推理,导致大量冗余计算。如何在不影响视频质量的前提下,大幅提升推理效率,成为亟需突破的难点。

- 论文标题:Less is Enough: Training-Free Video Diffusion Acceleration via Runtime-Adaptive Caching
- 论文地址:https://arxiv.org/abs/2507.02860
- 代码地址(已开源): https://github.com/H-EmbodVis/EasyCache
- 项目主页:https://h-embodvis.github.io/EasyCache/
2. 方法创新:EasyCache 的设计与原理
本论文提出的 EasyCache,是一种无需训练、无需模型结构改动、无需离线统计的推理加速新框架。它的核心思想非常直接:在推理过程中,动态检测模型输出的 「稳定期」,复用历史计算结果以减少冗余推理步骤。
2.1 扩散过程的 「变换速率」 规律
扩散模型的生成过程可以理解为 「逐步去噪」:每一步都从当前潜变量出发,预测噪声并更新状态,逐渐还原出清晰的视频内容。将一个 step 内的全部 DiT blocks 看做一个函数,可以考虑某个 step 的 「方向导数」 的一阶近似:
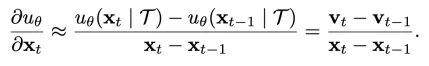
为了便于分析,将其求均值和范数以简化为数值(变换速率,Transformation rate):
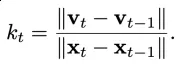
通过对扩散 Transformer 的内部特征分析,发现:
- 在去噪初期,模型输出变化剧烈,可能需要完整推理以捕捉全局结构;
- 但在中后期,模型的 「变换速率」 趋于稳定,行为近似线性,细节微调为主。
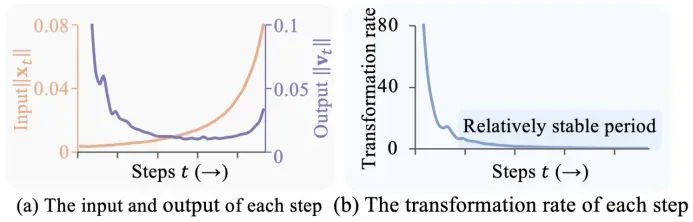
这种 「稳定性」 意味着,许多步骤的输出可以用之前某一步的结果做近似,大量冗余计算可以被跳过。
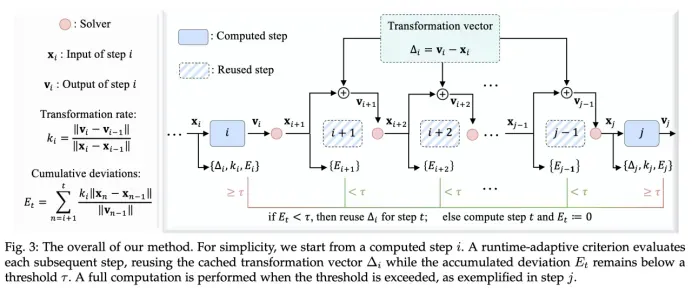
2.2 EasyCache 的自适应缓存机制
EasyCache 的具体实现流程如下:
(1)变换速率度量
定义每一步的 「变换速率」
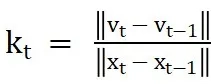
,用于衡量当前输出对输入的敏感度。我们惊讶地发现,尽管整个模型的输入输出在时间步层面变化剧烈且呈现不同的变化模式,Kt在去噪后期却能保持相对稳定。
(2)自适应判据与缓存复用
- 设定累计误差阈值,动态累计每步的输出变化率(误差指标Et)。具体而言,假定Kt在局部为常数,可以通过下一个 step 的输入变化与Kt一起协同判断输出的变化率(局部稳定性判断),将预估的输出变化率累加可以作为累计误差估计。
- 只要Et低于τ,就直接复用上一次完整推理的变换向量,否则重新计算并刷新缓存。
- 前 R 步为 warm-up,全部完整推理,确保初期结构信息不丢失。
(3)无需训练与模型改动
EasyCache 完全在推理阶段生效,不需要模型重训练,也不需修改原有网络结构,可以做到 「即插即用」。
3. 实验结果与可视化分析
论文在 OpenSora、Wan2.1、HunyuanVideo 等多个主流视频生成模型上进行了系统实验,考察了推理速度与生成质量的平衡。
3.1 定量实验结果
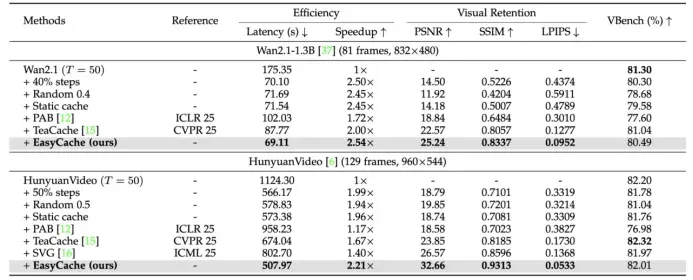
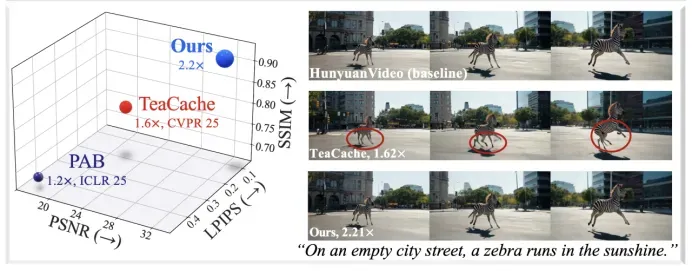
- EasyCache 在 HunyuanVideo 上实现 2.2 倍加速,PSNR 提升 36%,SSIM 提升 14%,LPIPS 大幅下降,视频质量几乎无损。在 Wan2.1 上也取得了超过 2 倍的加速比。
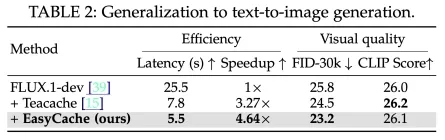
- 在图像生成任务(如 FLUX.1-dev)同样可带来 4.6 倍加速,并提升 FID 等指标。
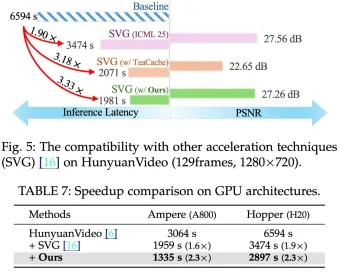
- EasyCache 与 SVG 等稀疏注意力技术可叠加,平均可达 3.3 倍加速,总体推理时长从 2 小时缩短到 33 分钟。
3.2 可视化对比
论文展示了不同方法生成的视频帧对比:
- 静态缓存和 TeaCache 等方法在细节、结构和清晰度上均有不同程度损失;
- EasyCache 生成的视频在视觉效果上与原始模型几乎一致,细节保留优秀,且无明显模糊或结构错乱。更多可视化请见:https://h-embodvis.github.io/EasyCache/

在Wan2.1-14B上,EasyCache成功地保留了文字

EasyCache能够在SVG的基础上进一步将加速倍数提高到三倍以上
4. 总结与未来展望
EasyCache 为视频扩散模型的推理加速提供了一种极简、高效、训练无关的新范式。它通过深入挖掘扩散过程的内在规律,实现了大幅提速且几乎无损的高质量视频生成,为扩散模型在实际应用中的落地提供了坚实基础。未来,随着模型和有关加速技术的持续提升,我们期望能进一步逼近 「实时视频生成」 的目标。


