中科院院士鄂维南、字节AI实验室总监李航领衔,推出高级论文搜索Agent。
名为PaSa,两个Agent分别执行多轮搜索和判断论文是否满足查询要求的任务,模仿人类复杂学术搜索行为。
现在就有Demo可玩。
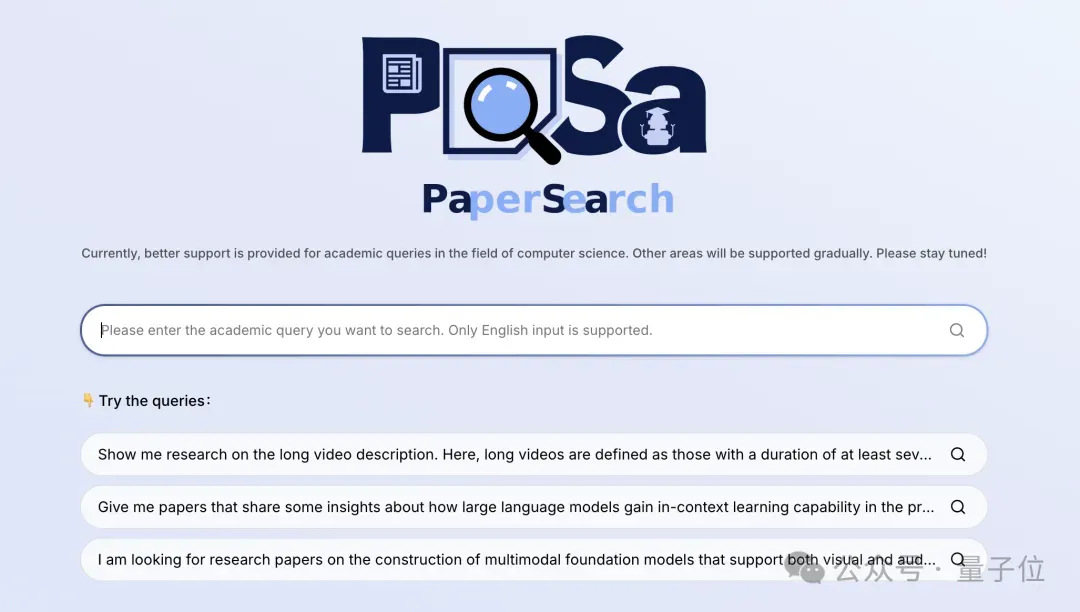
只需提供研究主题或描述想法,它就会迅速展开搜索并按相关度自动排列组织顺序。
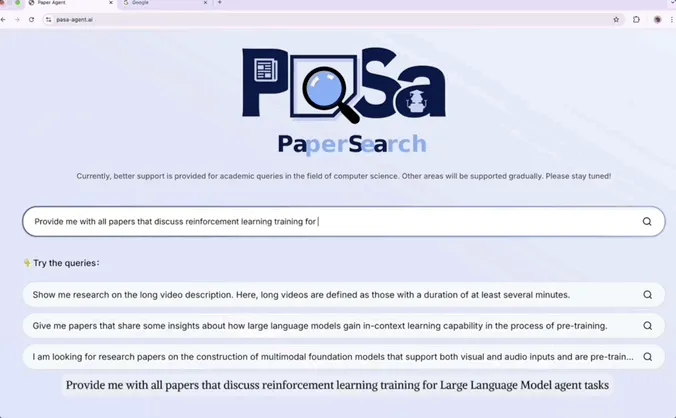
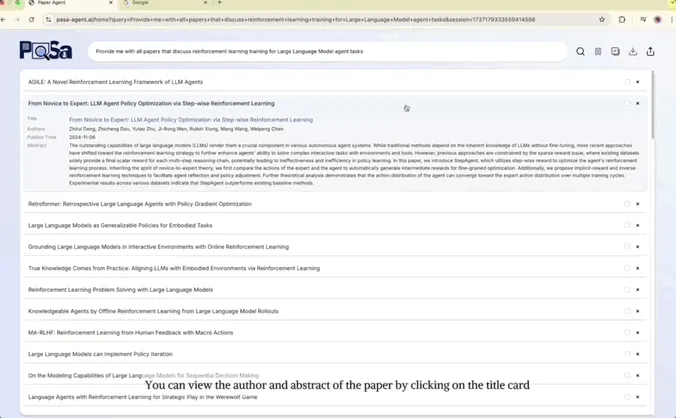
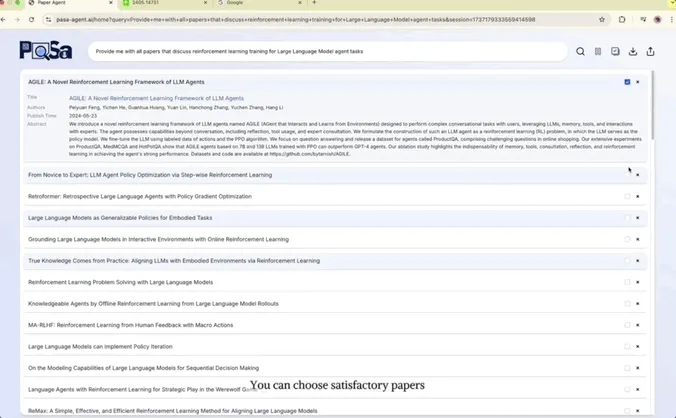
点击标题卡,不用跳转页面,就能显示论文作者和摘要,再点击带有跳转链接的标题就能查看完整论文:
还可以点击每个标题卡后面的小方框,打包下载JSON、BIB格式文件:
更重要的是其召回率和精准性。
实验中,PaSa在召回率和精确率等指标上显著优于谷歌、谷歌学术、Google with GPT-4o、ChatGPT等基线模型。
在AutoScholarQuery测试集,与最强基线PaSa-GPT-4o相比,PaSa-7b的召回率提高了9.64%;在团队创建的数据集RealScholarQuery上,与最佳基于Google的基线Google with GPT-4o相比,PaSa-7b在召回率@20、召回率@50和召回率@100上分别提升37.78%、39.90%和39.83%。
磕盐党狂喜~
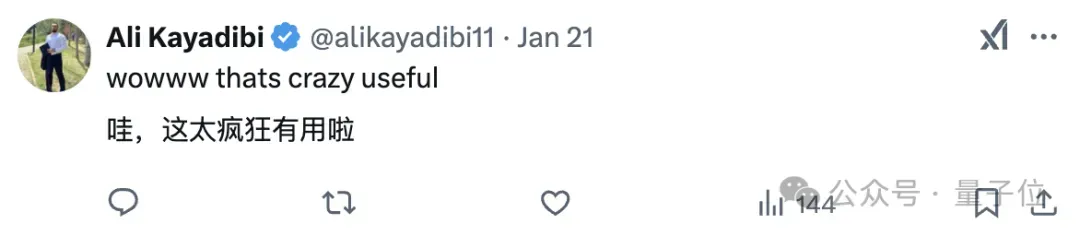
两个Agent组成
目前学术搜索系统,如谷歌学术搜索,常难以有效处理复杂的查询,导致研究人员需花费大量时间手动文献搜索。
比如询问”Which studies have focused on non-stationary reinforcement learning using value-based methods, specifically UCB-based algorithms?”。
(哪些研究聚焦于非平稳强化学习中基于值的方法,特别是基于UCB算法的研究)
虽然利用LLM来增强信息检索的研究越来越多,但学术搜索不仅需要检索,还需要深入阅读论文和检查引用,完成全面的文献调查。
为此,研究团队开发了PaSa系统,主要包含两个大模型Agent:Crawler(爬虫)、Selector(选择器)。
Crawler负责处理用户查询,生成多个搜索命令,并检索相关论文。
具体来说,它执行一个基于token的马尔可夫决策过程(MDP)。动作空间A对应于LLM的词汇表,其中每个token代表一个动作。LLM充当策略模型,Agent的状态由当前的LLM上下文和论文队列定义。
Crawler使用三个注册函数进行操作:
- [Search]用于生成搜索查询并调用搜索工具
- [Expand]用于展开论文的特定章节并提取其中的引用
- [Stop]用于重置上下文到用户查询和队列中的下一篇论文。
当动作与函数名称匹配时,将执行相应的函数,进一步修改Agent的状态。

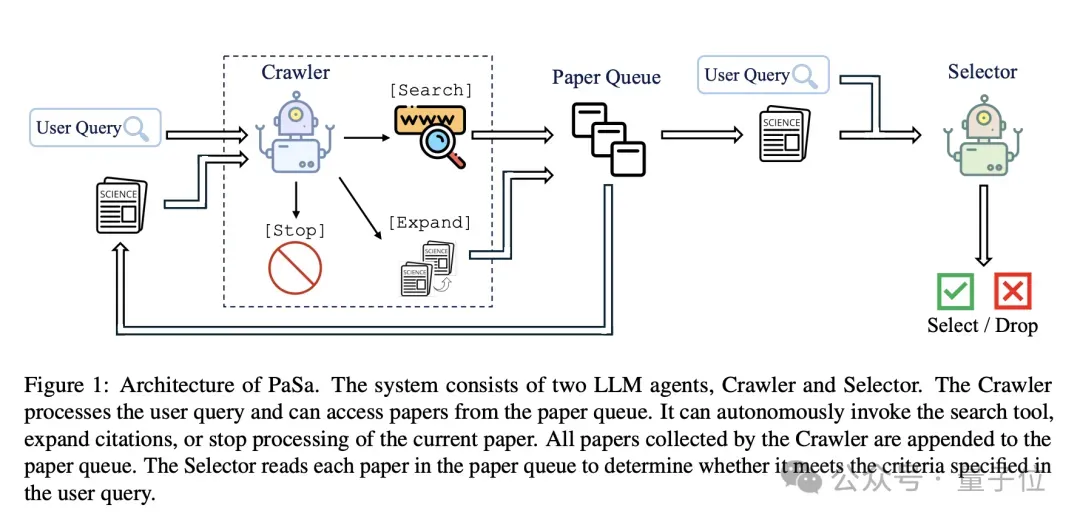
例如,如下图所示,Agent首先接收用户查询,将其纳入其上下文并开始执行动作。如果生成的token是[Search],则LLM继续生成搜索查询,Agent调用搜索工具来检索论文,然后将这些论文添加到论文列表中。
如果token是[Expand],则LLM继续从其上下文中的当前论文中提取子节名称。Agent随后使用解析工具提取该子节中引用的所有论文,并将它们添加到论文列表中。
如果token是[Stop],则Agent将其上下文重置为用户查询以及论文队列中下一篇论文的信息,这些信息包括标题、摘要以及所有部分的概述。
Selector则负责仔细阅读每篇论文,评估是否满足用户查询要求。
它接收两个输入:一个学术查询和一篇研究论文(包括其标题和摘要),
生成两个输出:
一个单一的决策token,可以是“True”或“False”,表示论文是否满足查询,以及一个理由,包含m个支持该决策的token。理由有两个目的:通过联合训练模型生成决策和解释来提高决策准确性,并通过在PaSa应用中提供推理来提高用户信任。
实验中优于所有基线
团队使用包含来自AI顶会收录论文的35k个细粒度学术查询及其对应论文的合成数据集AutoScholarQuery,通过强化学习优化PaSa。
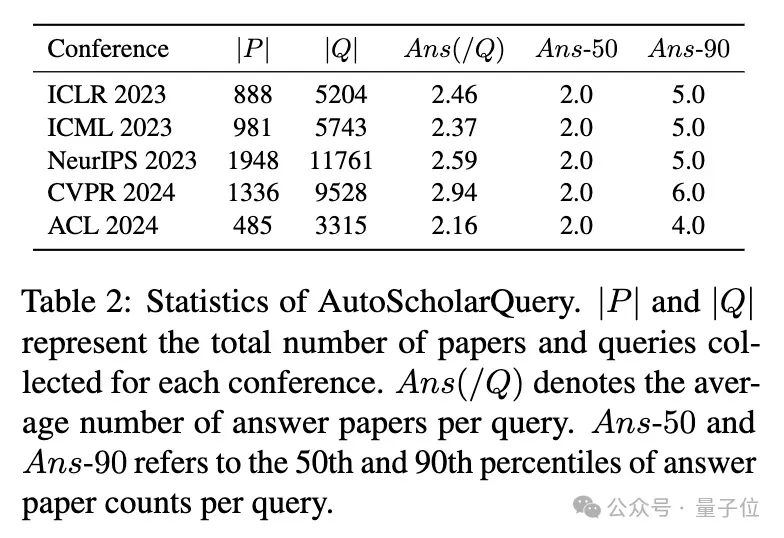

此外,还开发了一个收集真实世界学术查询的基准数据集——RealScholarQuery,用于在更现实的场景中评估PaSa 的性能。
实验中,Crawler和Selector均基于Qwen2.5-7b,最终的Agent称为PaSa-7b。
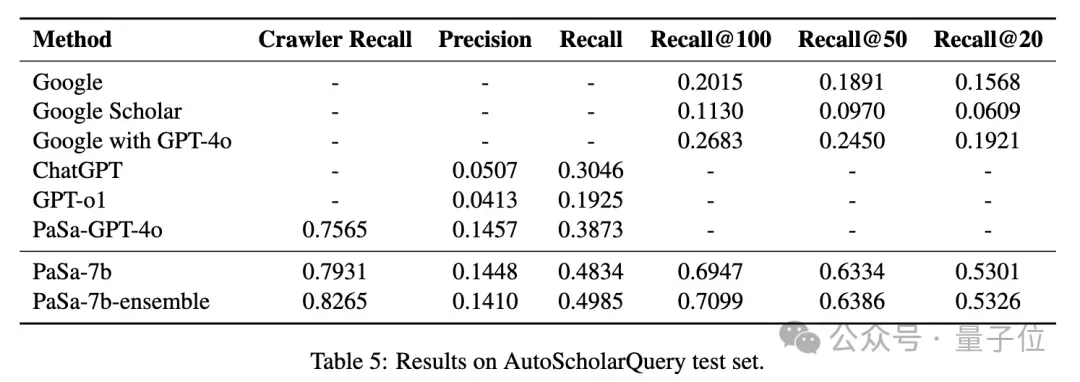
如下表5所示,PaSa-7b在AutoScholarQuery测试集上优于所有基线。
与最强的基线PaSa-GPT-4o相比,PaSa-7b的召回率提高了9.64%,精度相当。此外,PaSa-7b中Crawler的召回率比PaSa-GPT-4o高3.66%。
与最佳的基于Google的基线Google with GPT-4o相比,PaSa-7b在召回率@20、召回率@50和召回率@100上分别实现了33.80%、38.83%和42.64%的提升。
团队还观察到,在推理过程中使用多个Crawler集成可以提升性能。具体来说,在推理过程中运行两次Crawler,使 AutoScholarQuery上的Crawler召回率提高了3.34%,最终使整个PaSa系统的召回率提高了1.51%,同时保持精度相似。
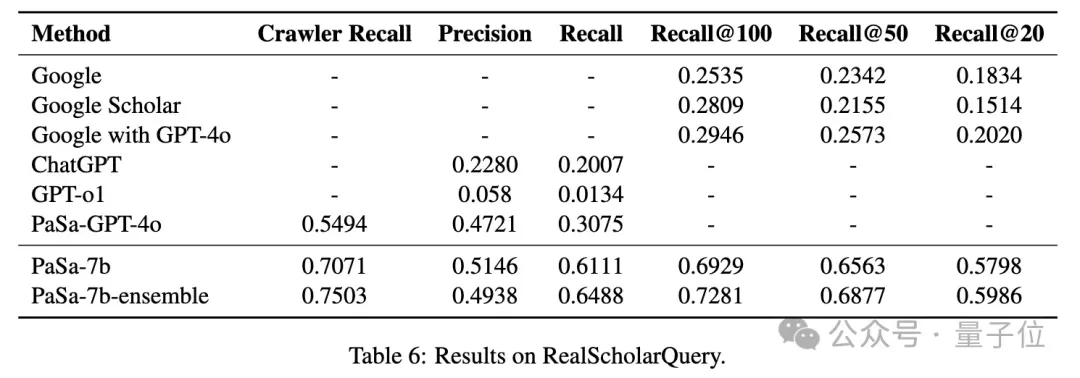
为了在更现实的场景中评估PaSa,团队在RealScholarQuery上评估了其有效性。如表6所示,PaSa-7b在真实世界的学术搜索场景中表现出更大的优势。与PaSa-GPT-4o相比,PaSa-7b的召回率提高了30.36%,精度提高4.25%。
与RealScholarQuery上最佳的基于Google的基线Google with GPT-4o相比,PaSa-7b在召回率@20、召回率@50和召回率@100上分别超过Google 37.78%、39.90%和39.83%。
此外,PaSa-7b-ensemble进一步将Crawler召回率提高了4.32%,使整个系统的召回率提高了3.52%。
鄂维南、李航领衔
PaSa由中科院院士、北大教授鄂维南,字节跳动AI实验室总监*李航领衔提出。

鄂维南,中科院院士、“AI for Science”概念的提出者。
15岁就被中科大录取,可以进“少年班”的他还是选择了进数学系学习纯数学。
而在大四之时,由于希望“自己学的东西真正有用,而不是只有高深”,他突然改变方向,决定改读应用数学。
我的内心深处是属于入世的,想跟社会跟技术产生一点联系,我不是那种能一辈子待在象牙塔里的人。
最终,他一路从中国科学院、UCLA完成硕博士学位(博士期间的导师为著名应用数学家Bjorn Engquist教授)。
博士毕业之后几年,鄂维南进入普林斯顿高等研究院和纽约大学的库朗研究所,分别担任研究员和教授。并在1999年即36岁之时成为普林斯顿大学数学系和应用数学及计算数学研究所教授,转年加入北大。
2011年,48岁的鄂维南当选中国科学院院士。
其贡献包括:
- 与合作者一起把偏微分方程、随机分析及动力系统的理论进行巧妙结合,用于研究随机Burgers方程、随机passive scalar方程、随机Navier-Stokes方程和Ginzburg-Landau方程等,证明不变测度的存在性和唯一性,分析稳定解的特性,并在此基础上解决了Burgers湍流模型中一些存有争议的问题。
- 与合作者一起构建一种十分有效的数值方法——弦方法,使之成为研究物理、生物和化学领域中稀有事件的一个重要手段。
- 提出设计与分析多物理模型的多尺度方法的一般框架等等。
从2014年开始,鄂院士的职业生涯迎来又一个转折,他开始正式进入机器学习领域,并在2018年提出“AI for Science”的概念。

李航,字节跳动AI实验室总监之一,同时当选三大国际顶级学会(ACL,IEEE,ACM) Fellow。
他的主要研究方向包括信息检索、NLP、统计机器学习和数据挖掘。
他在日本京都大学电气工程系获得硕士学位,并于东京大学计算机科学博士毕业,曾担任日本NEC公司中央研究所研究员、微软亚洲研究院高级研究员与主任研究员、华为技术有限公司诺亚方舟实验室首席科学家。

论文链接:https://arxiv.org/abs/2501.10120demo:https://pasa-agent.ai/


