你是不是也遇到这种情况:代码写完了、跑起来也没报错,但模型就是“不看图”?别急,这事儿很常见——多模态开发不难,难在模型是否真支持多模态。本文用最简单的方式,带你把“文字+图片”的多模态对话跑起来,并告诉你常见坑怎么避。
先把小坑填上:Lombok 报错这样一键解决
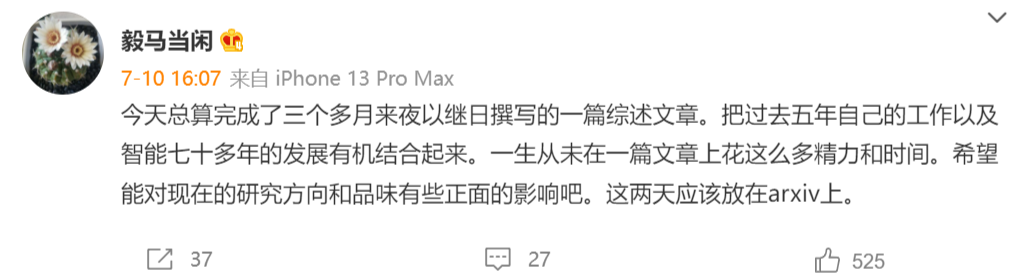
如果你在跑 LangChain4j 的对话 Demo 时,控制台提示“找不到符号”的 Lombok 错误,通常是 IDEA 注解处理器没配好。
 图片
图片
上图:典型的 Lombok 报错提示
解决方法:
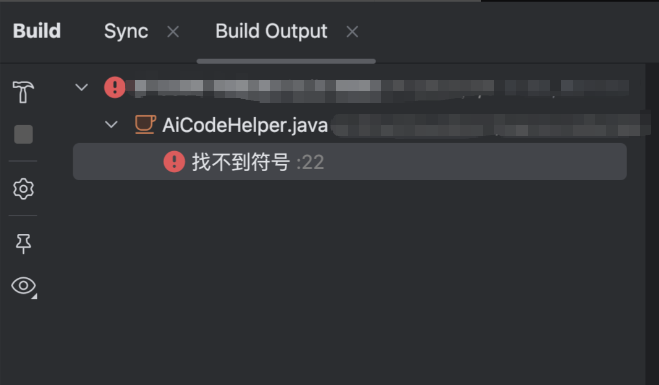
• 打开 IDEA 设置 → Annotation Processors
• 勾选 Enable annotation processing
• 改为“使用项目中的 Lombok”
 图片
图片
上图:IDEA 注解处理器正确姿势
多模态到底是啥?为什么重要
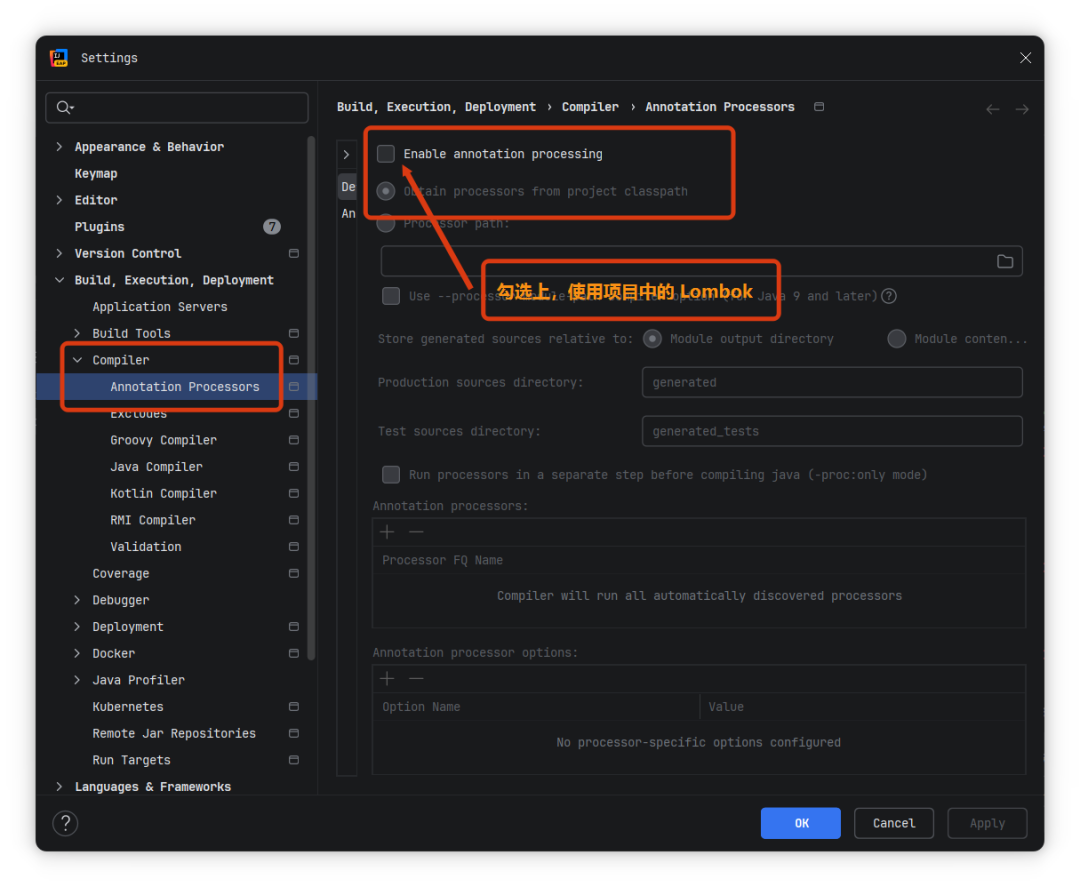
• 多模态=同时处理文字、图片、音频、视频、PDF 等多种数据。
• 典型场景:看图回答、读简历提要、解析表格截图、对 PDF 提问、听音频写总结等。
 图片
图片
上图:多模态能理解多种输入并输出文本/图片等
LangChain4j 支持哪些多模态类型
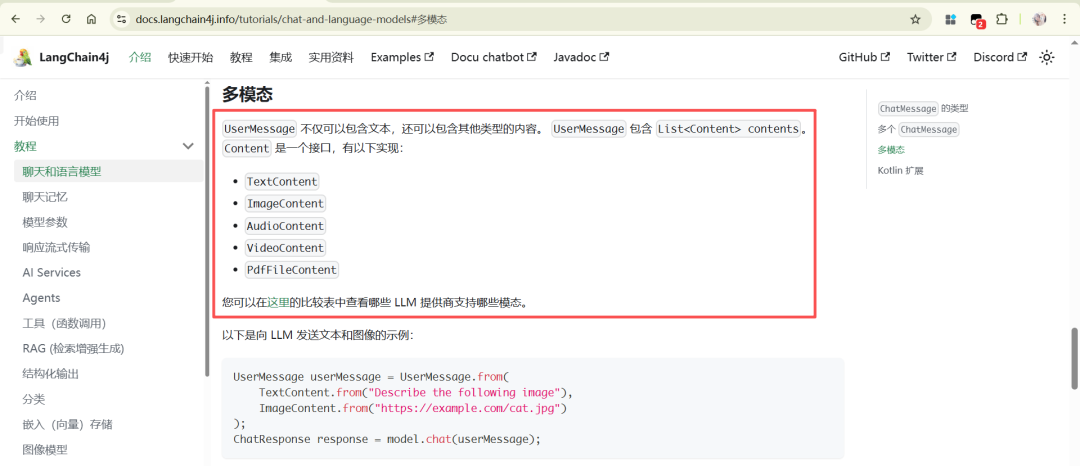
在官方文档的多模态章节可以看到支持情况:
• 用户消息可携带文本、图片、音视频、PDF 等多种内容
• 能不能用,关键看“底层模型是否支持”
• 文档地址(以实测为准):https://docs.langchain4j.info/tutorials/chat-and-language-models#%E5%A4%9A%E6%A8%A1%E6%80%81
 图片
图片
上图:LangChain4j 多模态类型示意
实战:给对话加一张图,让模型“看图说话”
我们先写一个能接收自定义 UserMessage 的方法:
复制然后写个单测,发一张图片进去:
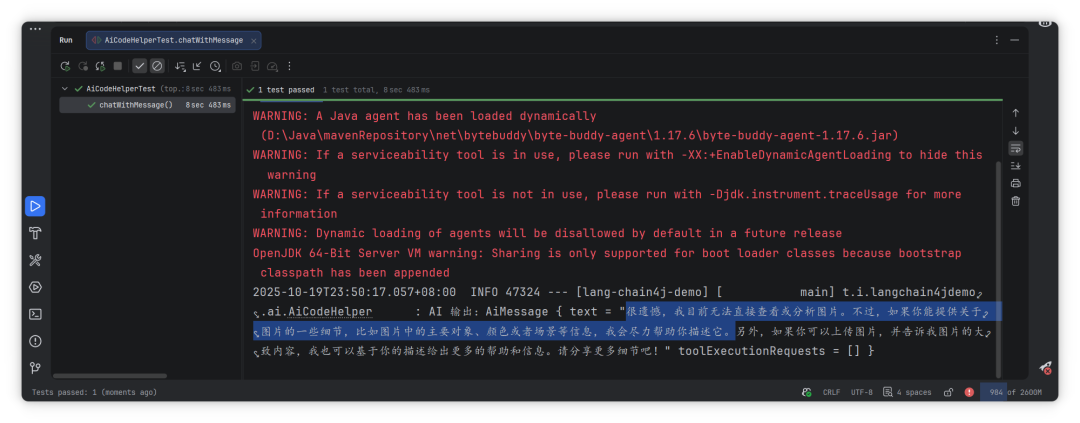
复制运行效果如下:
 图片
图片
上图:用图片做输入的单测结果
为什么没生效?关键原因在“模型不支持”
如果你用的是 qwen-max,可能会发现:它并不能直接看图。这不是代码问题,而是“模型能力没开多模态”。
这点非常关键:
- • 框架会帮你把文本+图片打包发出去
- • 但如果模型不支持图片输入,它就看不到图,回答只能按文本来
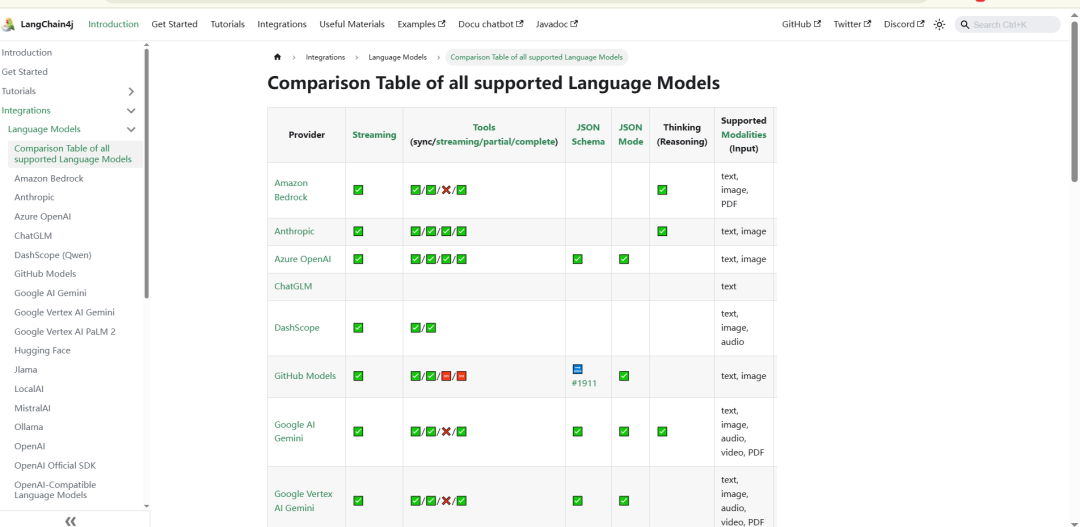
可以参考 LangChain4j 的能力支持表(但务必以实际测试为准):https://docs.langchain4j.dev/integrations/language-models/
 图片
图片
上图:不同模型的能力差异很大,需实测
选型建议:想要“看图”,优先选这些模型
实测优先考虑(不同厂商地域/版本差异较大,需自己验证):
- • OpenAI 家族:gpt-4o / gpt-4o-mini(图像理解较稳定)
- • Azure OpenAI:对应的 4o 系列
- • Qwen:Qwen-VL 系列(区分是否开放接口)
- • Google:Gemini 1.5 Flash / Pro(区域与配额限制较多)
注意点:
- • 先查清楚“是否支持图像输入”和“最大图片尺寸/大小”
- • URL 必须可公网访问,或使用字节流上传
- • SDK/依赖版本需匹配,LangChain4j 要跟后端模型 SDK 对齐
常见坑与避坑清单(强烈建议收藏)
- • 模型能力不一致:同一品牌不同型号能力差别大,别想当然。先跑最小可用 Demo。
- • 图片不可访问:本地路径/私网地址不行,换公网 URL 或上传字节流。
- • 图片太大:超限会被静默压缩或拒绝,提前做压缩或限制尺寸。
- • 超时/重试:图片+文本耗时更长,调大超时并添加重试策略。
- • 版本兼容:LangChain4j 版本与底层 SDK/依赖要匹配,升级要看 Release Note。
- • 日志与可观测:把请求/响应元数据打印出来(别打全量敏感内容),方便排错。
小结
- • 多模态不难,难在“模型要真支持”。先跑通最小闭环,再谈业务场景。
- • LangChain4j 已能优雅地传递多模态输入,但要结合“支持图像的模型”一起用。
- • 建议你把本文的 Demo 跑起来,再换成具备图像理解能力的模型做实测。