
作者团队介绍:本文来自罗格斯大学和 Adobe 团队的合作,一作徐武将罗格斯二年级博士,研究兴趣在 LLM Agent Memory 以及 Agent RL 方向上。师从 Dimitris N. Metaxas 老师,曾任 cvpr general chair。
在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。
研究者发现这是一种独特的「探索 - 利用级联失效」(exploration-exploitation cascade failure)现象。具体表现为在早期阶段,过度探索导致策略熵值失控上升,但奖励信号几乎没有提升,探索没有转化为有效学习;在后期阶段,早期的不稳定性传播到后续步骤,熵值持续高位震荡,无法形成连贯的决策策略。
为此,研究者提出了 Entropy-regularized Policy Optimization (EPO) 框架,包含三个核心机制: 多轮熵正则化、熵平滑正则器和自适应权重。实验结果上,在 ScienceWorld 环境,PPO+EPO 相比 PPO 最大提升 152%;在 ALFWorld 环境,GRPO+EPO 相比 GRPO 最大提升 19.8%。同时,观测训练的曲线,发现训练稳定性显著提高,方差明显降低。

论文标题: EPO: Entropy-Regularized Policy Optimization for LLM Agents Reinforcement Learning
论文链接: https://arxiv.org/pdf/2509.22576
代码仓库: https://github.com/WujiangXu/EPO
引言
最近在训练多轮 LLM Agent 时,研究者遇到了一个令人困扰的现象。在 ScienceWorld 和 ALFWorld 这两个需要 30 + 步交互的环境中,标准的 PPO 和 GRPO 算法表现出极度不稳定的训练动态:
熵值疯狂震荡:策略熵在训练过程中剧烈波动,从低熵状态突然跳到高熵状态,再突然跌落。
奖励曲线不动:尽管进行了 100 + 轮训练,平均奖励几乎没有提升。
训练无法收敛:不同随机种子之间的性能差异极大,模型行为不可预测。
更令人困惑的是,这个问题在单轮或短 horizon 任务中并不明显。同样的 PPO/GRPO 算法在数学推理、代码生成等单轮任务上工作良好。这说明多轮稀疏奖励环境存在某种独特的失效模式。研究者系统地检索了相关文献,发现现有工作主要关注两个方向:
单轮 LLM 的熵控制(Cui et al. 2025; Dong et al. 2025; Wang et al. 2025a):这些方法通过修改 advantage 函数或使用 KL 惩罚来防止熵崩溃,但它们假设的是即时反馈场景。
多轮 Agent 的其他挑战(Zhou et al. 2024; Bai et al. 2024):已有工作关注分层 RL、信用分配、密集奖励设计等问题,但没有系统研究多轮环境下的探索 - 利用动态。
现有的熵控制方法都是为单轮或短 horizon 场景设计的,它们无法解决多轮环境中独特的「级联失效」问题。通过详细的训练轨迹分析,研究者识别出一种在多轮稀疏奖励环境中特有的失效模式,研究者称之为探索 - 利用级联失效(exploration-exploitation cascade failure)。这个失效过程分为两个明显的阶段:
阶段 1:过度早期探索
由于稀疏和延迟的奖励信号,标准的熵正则化反而导致失控的熵增长。Agent 在早期步骤进行盲目探索,而不是有目的的探索。这创造了不稳定的行为基础,系统性地锁定到次优的行为模式。
从图 1 可以看到,PPO 的早期轨迹步骤(粉色虚线)表现出快速、不受控的熵增长,而奖励保持停滞,说明探索没有有效转化为奖励提升。
阶段 2:不确定性传播
早期步骤的不稳定性会复合传播到后续步骤。由于多轮环境的时序依赖性,早期的错误决策会影响后续所有步骤的状态分布。累积的不确定性在后期步骤复合,维持危险的高熵水平,阻止连贯策略的形成,进一步降低性能。
同样从图 1 可以看到,PPO 的后期轨迹步骤(红色虚线)维持了高熵震荡,奖励曲线 plateau,尽管持续探索。标准的熵正则化缺乏时序意识。它们只关注瞬时熵值,而忽略了多轮环境中的关键事实: 早期步骤的决策从根本上塑造了后续步骤的结果 。传统方法无法打破这个级联循环。
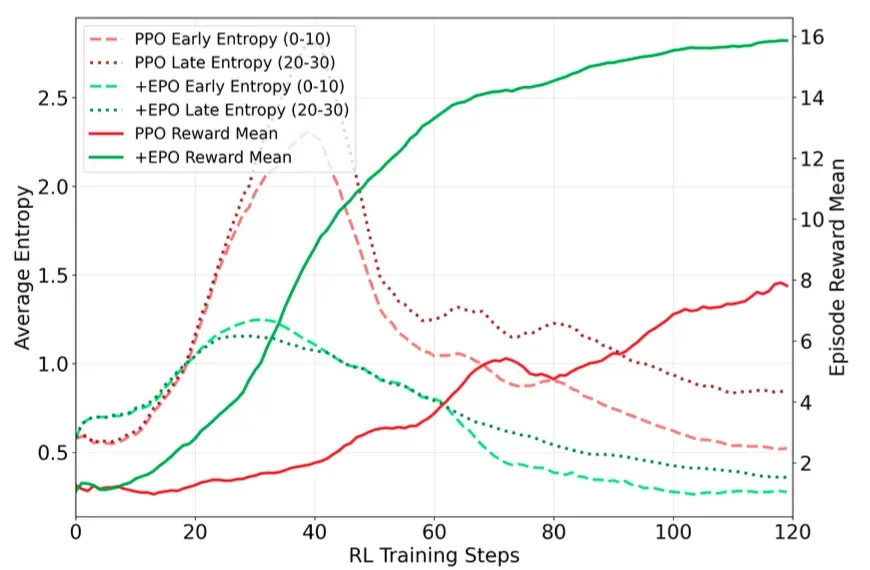
图 1
方法
研究者提出 Entropy-regularized Policy Optimization (EPO),一个专门为打破级联失效而设计的框架。核心洞察是:将策略熵锚定到动态调整的历史边界上,提供了必要的稳定性来阻止级联失效,同时不牺牲必要的探索。
EPO 包含三个协同机制:
1、多轮熵正则化
研究者改进了熵计算方式,在轨迹内的所有 turns 上计算熵,并在轨迹批次上平均,捕捉 agent 交互的独特时序结构:
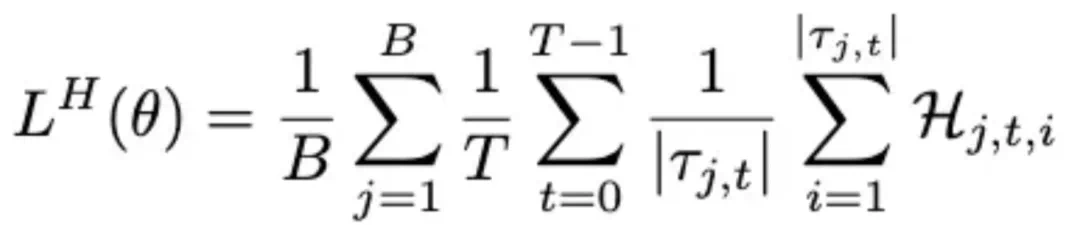
其中 token 级熵为:
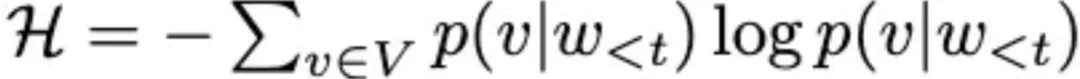
2、熵平滑正则器(核心创新)
为了打破级联失效的两阶段模式(过度早期探索 → 后期不确定性传播),研究者引入了一个熵平滑机制,防止稀疏奖励设置中观察到的危险振荡。
研究者维护一个熵历史窗口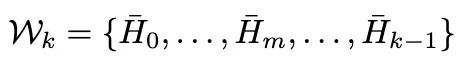 ,计算历史熵参考:
,计算历史熵参考:
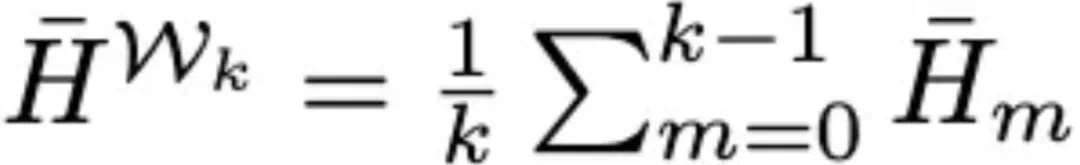
对每个 token 应用基于可接受熵范围的惩罚:
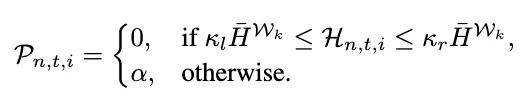
其中边界系数 k_l 和 k_r 定义可接受范围,α 提供超出期望范围的 token 的惩罚权重。通过将熵约束在历史平均值内,研究者既防止了早期阶段的盲目探索,也防止了后期阶段的混乱不确定性传播。
聚合所有 tokens、turns 和 trajectories 的惩罚得到平滑损失:
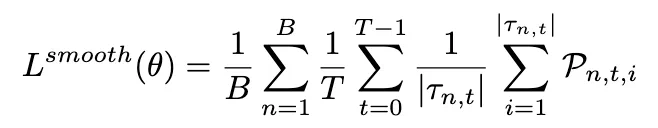
3、自适应平滑权重
研究者开发了一个自适应权重方案,在训练阶段动态平衡探索和利用,直接对抗级联失效的进展:
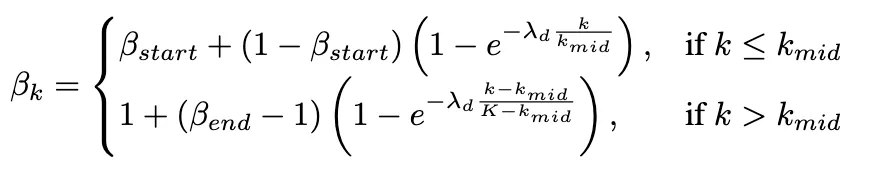
其中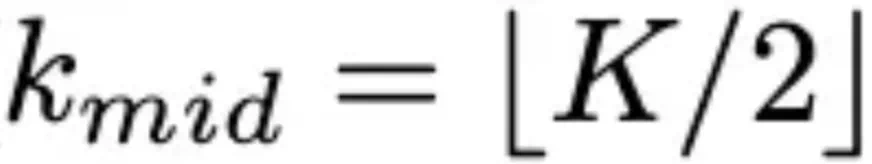 。
。
完整 EPO 目标函数
完整的熵平滑策略优化损失定义为:
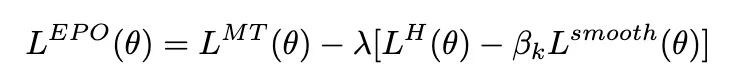
实验结果
实验设置
研究者在ScienceWorld 和 ALFWorld 上分别使用Qwen2.5-7B-Instruct 和 Qwen2.5-3B-Instruct 进行实验。
Evaluation setting 包含 IID 和 OOD 两个 setting,指标上包含两个 success rate:
Succ.*:最大成功率的平均值
Succ.:收敛后的平均性能(更 robust)
对比实验
EPO 的有效性体现在两个关键维度:量化性能的大幅提升和训练动态的根本改善。表 1 展示了 EPO 在两个环境上的突破性表现,特别是在 ScienceWorld IID 任务上,PPO+EPO 相比基线 PPO 实现了 152.1% 的成功率提升,显著超越了 agent 专用方法 GiGPO 和 RLVMR。这个巨大提升直接源于 EPO 的熵平滑正则化机制 —— 它成功阻止了 PPO 在多轮交互中因 aggressive 策略更新导致的严重熵崩溃。在 ScienceWorld 的稀疏奖励环境中,维持探索至关重要,EPO 的 stabilization 作用在这里显得尤为关键。
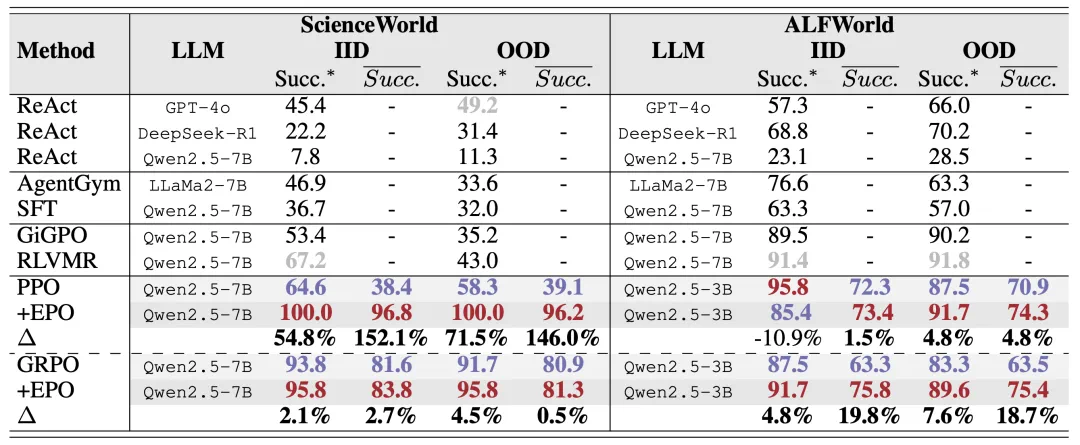
表 1
图 2 则揭示了 EPO 性能提升背后的深层机制。训练曲线对比清晰地展示:PPO+EPO 在 ScienceWorld 上达到了约 2x 的训练奖励 (15 vs. 8),同时保持 smooth 的单调上升轨迹;而 baseline 方法则表现出严重的震荡和不稳定性。更关键的是验证曲线 ——EPO 变体在仅 40 步内就快速收敛到高成功率 (>0.8),baseline 即使训练 100 步也难以突破 0.4。在 ALFWorld 的 OOD 评估中,baseline 频繁跌破 0.2,而 EPO 变体始终维持在 0.4 以上。这种消除了 premature 收敛和 over-exploration 之间的特征性震荡的模式,直接验证了本文熵正则化框架在解决多轮 LLM agent 训练中探索 - 利用困境的有效性。
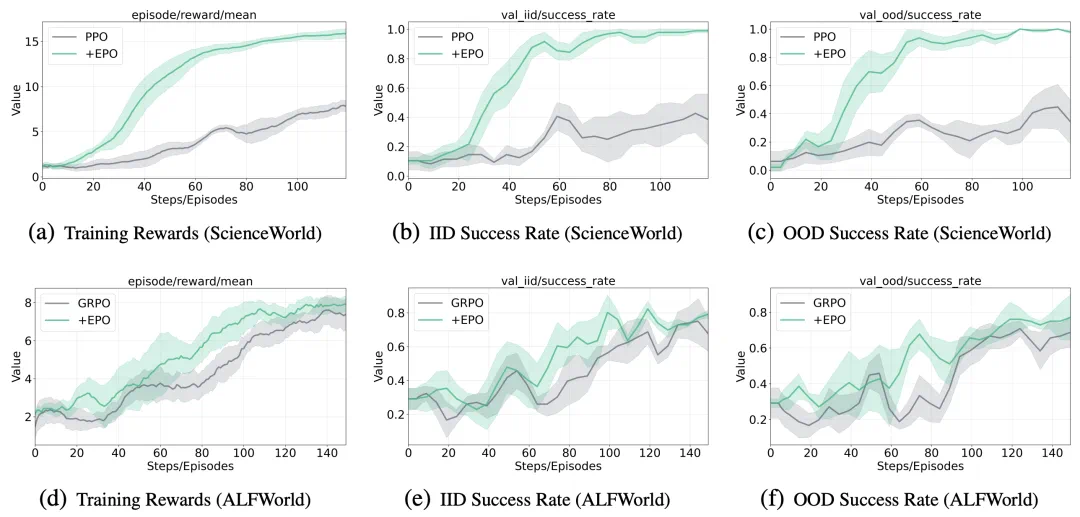
图 2
模型研究
熵正则化的研究
研究者比较了标准方法 PPO+EPO-Base(在整个训练过程中应用一致的熵正则化)与 PPO+EPO-Decay(采用动态 schedule,在初始训练阶段分配更高的熵权重以促进探索,在后期阶段系统性地减少它以鼓励利用)。
违反直觉的结果(图 3):
decay 策略在所有指标上持续表现不佳:
虽然 decay schedule 成功降低了训练后期阶段的策略熵
但它过早地抑制了每个 episode 的关键初始 turns 中的探索
从图 3 (c) 可以看到,比较前 10 个 tokens(「Early Steps」)与最后 10 个 tokens(「Late Steps」)的平均熵,显示不足的早期探索将 agents 锁定到次优策略,即使策略变得更确定性也无法恢复
关键 insight:
直接改变损失权重在 LLM agent 场景中失败,是由于多轮设置中的探索 - 利用级联失效。与单轮任务不同,多轮环境表现出强时序依赖性,其中早期步骤从根本上塑造后期步骤结果。
decay schedule 触发:
过度早期阶段探索:创建不稳定基础,系统性地锁定到次优行为模式。
后期不确定性传播:累积的不确定性复合,阻止连贯策略形成。
因此,对于复杂的多轮稀疏奖励任务,在所有轨迹步骤中维持 robust 和一致的探索压力是避免级联失效的关键,而不是遵循传统的探索到利用调度。
熵形状 Advantage 的研究
研究者还比较了 Entropy-smoothed Policy Optimization (EPO) 与 Cheng et al. (2025b) 的 Entropy-based Advantage (EA) 塑形方法。
结果如图 3 (b)所示:
虽然 PPO+EA 相比基线有改进,但 PPO+EPO 在最终性能和收敛速度上都显著优越:
PPO+EPO:达到近乎完美的成功率(~1.0)
PPO+EA:plateau 在 0.5-0.6
关键差异在于梯度信号和它如何影响底层 LLM 的能力:
EA:使用 detached 熵项作为间接内在奖励,不提供梯度信号来显式增加熵。
EPO:将熵直接整合到策略损失中,启用直接梯度信号
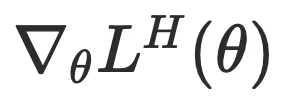 来引导策略走向更探索性的行为
来引导策略走向更探索性的行为
此外,EA 的 hard clipping 在 advantage bonus 上可能诱导训练不稳定性,其近视性质只考虑瞬时熵。
关键 insight:
对于 LLM agent RL,直接修改策略损失可能严重损害模型的推理能力 —— 这些能力在预训练期间未针对 agent 特定任务开发。由于 LLMs 不是在 agent 特定任务上预训练的,aggressive 熵正则化直接注入到策略损失中会破坏模型的学习表征和推理路径。
本文的 EPO 方法通过使用具有历史熵窗口的时间平滑来解决这个问题,它保留 LLM 固有推理能力的同时提供探索指导。这种解耦正则化维持了值信号和预训练知识的完整性,导致更 robust 和有效的学习而不降低模型的基础能力。
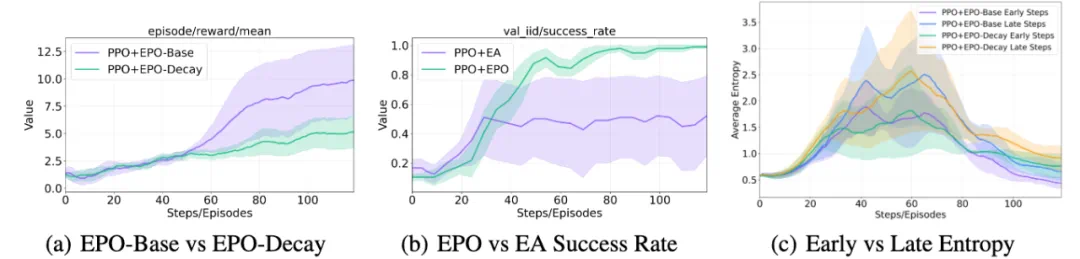
图 3
结论
在这项工作中,研究者识别并解决了训练多轮 LLM agents 在稀疏奖励环境中的探索 - 利用级联失效这一基本挑战。
核心贡献包括如下 :
问题形式化:首次系统性地刻画了多轮稀疏奖励环境中独特的级联失效现象。
EPO 框架:提出了通过轨迹感知熵计算、熵平滑正则化和自适应相位权重来防止危险熵振荡的机制。
理论保证:证明了 EPO 保证熵方差单调递减,并提供严格优于标准最大熵 RL 的性能界。
实证验证:在 ScienceWorld 上实现高达 152% 的性能提升,在 ALFWorld 上实现 19.8% 的提升,将之前不可训练的场景转变为平滑收敛的优化问题。
这项工作确立了多轮 LLM agent 训练需要与传统 RL 根本不同的熵控制,为开发 effective 的 LLM Agents 训练方法开辟了新方向。EPO 是一个通用框架,可以与任何 on-policy 优化方法无缝集成,为未来研究提供了坚实基础。


