
大家好,我是肆〇柒。我看到了一个很有趣的研究,它涉及经验共享,群体RL进化。今天我们要探讨的,不是来自谷歌或OpenAI的最新成果,而是一家名为Gensyn AI的前沿研究团队提出的革命性想法。他们最近发表的论文《Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing》,提出了一种名为SAPO的算法,试图用“蜂群”的智慧,改变我们训练AI模型的方式。
在AI前沿,一个反直觉的发现正在颠覆我们的认知:当一个语言模型经历"顿悟时刻"(Aha moment),它的发现可以像病毒一样在模型群体中快速传播,显著抬升整个群体的智能基线。这不是科幻小说的情节,而是Gensyn AI团队最新提出的Swarm sAmpling Policy Optimization(SAPO)算法所展示的真实能力。
在强化学习(Reinforcement Learning, RL)后训练语言模型的语境中,"顿悟时刻"特指模型偶然发现高质量解法的关键突破。当一个智能体获得"顿悟时刻"后,这一发现能够通过群体传播,从而提升整体性能。在ReasoningGYM测试环境中,这些"顿悟"表现为模型突然掌握特定任务(如base_conversion或propositional_logic)的正确解法,而SAPO的魔力在于,它让这些突破性进展不再局限于单个模型,而是成为整个群体的共同财富。
传统强化学习后训练语言模型的方法面临着严峻挑战。当前主流方法主要依赖于集中式GPU集群,需要在训练过程中保持策略权重同步。虽然有效,但这些方法成本高昂,引入通信瓶颈,并且通常需要精心设计的基础设施来保持稳定和高效。这类方法需要进行显著的并行化以扩展推理能力,这不仅带来了非同小可的技术挑战(例如延迟、内存和可靠性问题),还伴随着不断增长的财务成本。
SAPO的突破性在于它重构了分布式RL的架构理念,让模型从"孤军奋战"转变为"蜂群智能"。通过将经验共享转化为核心优势,SAPO为语言模型后训练提供了一条可扩展且实用的途径。在控制实验中,平衡的经验共享(4 local/4 external)几乎使性能翻倍,实现了高达94%的累积奖励提升。这不仅是一种技术革新,更代表着一种全新的训练范式——"Sharing is Caring"成为了AI训练的信条。在本文中,我们将探讨SAPO如何通过集体经验共享,为小规模语言模型的后训练开辟了一条高效、去中心化的新路径。
从"孤军奋战"到"蜂群智能"
传统RL后训练语言模型的方法面临着三大瓶颈——权重同步带来的通信开销、硬件同质化要求导致的资源浪费、以及系统脆弱性。这类方法需要进行显著的并行化以扩展推理能力,这不仅带来了非同小可的技术挑战(例如延迟、内存和可靠性问题),还伴随着不断增长的财务成本。
SAPO的突破性在于它彻底重构了分布式RL的架构理念:
去中心化是灵魂:SAPO不需要中央协调器,每个计算节点都是自治的"智能体",可以随时加入或退出网络。研究明确指出,该算法专为异构计算节点的去中心化网络设计,其中每个节点管理自己的策略模型,同时与网络中的其他节点"共享"rollouts;对延迟、模型同质性或硬件没有明确假设,如果需要,节点也可以独立运行。这种设计使得系统能够适应现实世界中节点频繁上线/下线的动态环境,为大规模分布式训练提供了前所未有的弹性。
SAPO的核心算法流程清晰地展示了其去中心化协作机制。根据素材中的Algorithm 1,每个节点的训练过程包含以下关键步骤:首先从问题集中采样一批问题;为每个问题生成8个回答,形成rollout ;节点选择子集的问题及其元数据、真实答案和rollouts进行广播:。随后,节点构建自己的训练集,其中包含个本地rollouts和个外部rollouts,然后使用本地奖励模型计算奖励并更新策略。

SAPO 算法伪代码
异步与包容是基石:SAPO不对节点的硬件配置、模型版本或在线时间提出要求。这种包容性使得普通消费级设备(如MacBook)也能参与高级AI训练。研究特别强调,节点在swarm中不一定需要参与训练,可以使用任何兼容策略;因此,原则上,人类和其他非传统策略可以作为swarm中的生成器。
"经验"是唯一货币:SAPO的核心机制是交换"做了什么"(decoded rollouts),而非"怎么想的"(权重/梯度)。每个节点接收共享rollouts后,能够用自己的模型重新编码这段文本,并计算出适用于自身策略的训练信号。研究特别强调,rollouts以解码格式共享,使得swarm中的个体能够模拟这些rollouts,就像由它们自己的策略生成的一样;例如,个体可以重新编码并计算token-level值,就像rollout是由它们的策略生成的一样,无论其可能性如何。这一"重放兼容性"机制是SAPO去中心化架构得以成立的基石,它巧妙地绕过了传统分布式RL中必须同步模型权重的硬性要求。
在实验中,这一机制的具体实现是:所有节点首先丢弃优势值(advantage)为零的rollouts,然后从swarm中剩余的rollouts中均匀采样。这一预处理步骤相当于一个简单的质量过滤器,确保了共享池中的rollouts至少包含了一些"正向信号"。在实验中,所有节点首先丢弃优势值为零的rollouts,然后从swarm中剩余的rollouts中均匀采样。这一机制对SAPO的成功至关重要。
让我们用一个具体例子来理解SAPO的工作流程:假设节点A在"base_conversion"任务中突然学会了二进制转十进制的正确方法,生成了一个高质量的解答。这个解答以纯文本形式(decoded rollout)广播到swarm中。节点B接收到这个文本后,不是简单地复制粘贴,而是用自己的模型重新编码这段文本,计算出适用于自身策略的训练信号。即使节点B的模型架构与节点A不同,甚至版本更新,它也能通过这种方式学习到节点A的"顿悟"。这就是SAPO的核心——它让不同模型能够互相"翻译"经验,实现真正的跨模型协作。
轻量级协作的革命性:rollouts以纯文本形式共享,节点可以按需筛选和利用。这种设计将通信开销降至最低,同时保留了协作学习的核心价值。SAPO通过采样网络中"共享"的rollouts,使"Aha moments"得以传播,从而引导学习过程。
从多智能体框架的视角看,SAPO自然表现出协作行为而无需额外计算。与结构化多智能体框架不同,它不产生专业化的节点或协调协作。然而,通过共享经验,节点间接从彼此的探索和推理中受益,产生更丰富的训练信号。这使SAPO成为在单智能体RL微调和结构化多智能体框架之间插值的桥梁。SAPO通过经验共享加速训练,捕获多智能体方法的诸多优势;通过RL微调,它鼓励个体在将这些优势传递给swarm中的其他成员之前先从中受益。
虽然与swarm通信和重新编码采样rollouts引入了通信和计算开销,但使用swarm训练的模型通过更少的训练轮次获得更好的性能。换句话说,每个个体的额外成本被集体收益所抵消。这一开销-收益平衡是SAPO实用性的关键——它证明了"去中心化协作"不仅在理论上可行,在经济上也是高效的。
数据揭示的协作红利与陷阱
SAPO的理论优势在控制实验中得到了有力验证。研究团队使用由八个Qwen2.5-0.5B模型组成的swarm,基于ReasoningGYM数据集进行测试,该数据集包含代数、逻辑和图推理等多种可验证任务。
ReasoningGYM是一个能够按需生成问题的动态数据集,每个领域生成器都配有一个程序化验证器,能够可靠地进行"现成"的正确性检查。研究团队从ReasoningGYM的任务目录中精心选择了9种专业任务,确保评估覆盖符号、数值和抽象领域的多样化推理任务:
- base_conversion:在不同进制间转换数字
- basic_arithmetic:执行基本算术运算
- arc_1d:在一维序列上进行抽象推理(ARC基准的简化版)
- bf:涉及Brainf*ck程序或类似算法推理的任务
- propositional_logic:解决命题逻辑问题
- fraction_simplification:尽可能简化分数
- decimal_arithmetic:在十进制约束下执行算术并遵守运算优先级
- calendar_arithmetic:解决涉及日历日期的字谜问题
- binary_matrix:对二进制方阵进行抽象推理
在训练过程中,每个智能体随机从上述列表中抽样专业领域(可重复),每个领域接收一个问题。对于每个问题,每个智能体生成8个完成结果,形成每个问题的8个条目rollout(即,对所有)。实验中,智能体是通用型的,即它们以相等的概率接收所有专业领域的问题。
在策略更新方面,研究团队使用GRPO(Group Relative Policy Optimization)来更新每个节点的策略。在初始实验中,他们发现不使用KL散度惩罚的训练更高效,因此将其权重设为零。对于裁剪,使用了非对称阈值,(下限比率)和(上限比率)。训练运行了2000轮,使用Adam优化器和默认超参数(例如,学习率0.001)。
在奖励模型方面,研究使用了ReasoningGYM提供的灵活、基于规则的验证器。如果任务特定验证器能够从完成结果中解析出正确答案,则分配奖励1,否则为0。值得注意的是,研究团队最初添加了格式奖励,但很快移除了它。SAPO中的经验共享使其变得不必要,因为关于正确格式的知识(ReasoningGYM验证器所期望的)几乎立即在整个swarm中传播,无需显式的格式奖励信号。
不同配置下的奖励轨迹
上图展示了四种配置的训练结果:8 local/0 external(基线)、6 local/2 external、4 local/4 external和2 local/6 external。最引人注目的是,4 local/4 external配置实现了高达94%的累积奖励提升(1093.31 vs 基线的561.79)。这里需要明确区分"峰值奖励"和"累积奖励"——虽然4 local/4 external和2 local/6 external配置都达到了较高的峰值奖励,但4/4配置在累积奖励方面表现最佳,这意味着它在整个训练过程中保持了更稳定的性能提升。
深入分析下图所示的平均奖励曲线,可以发现SAPO带来的三大关键洞见:
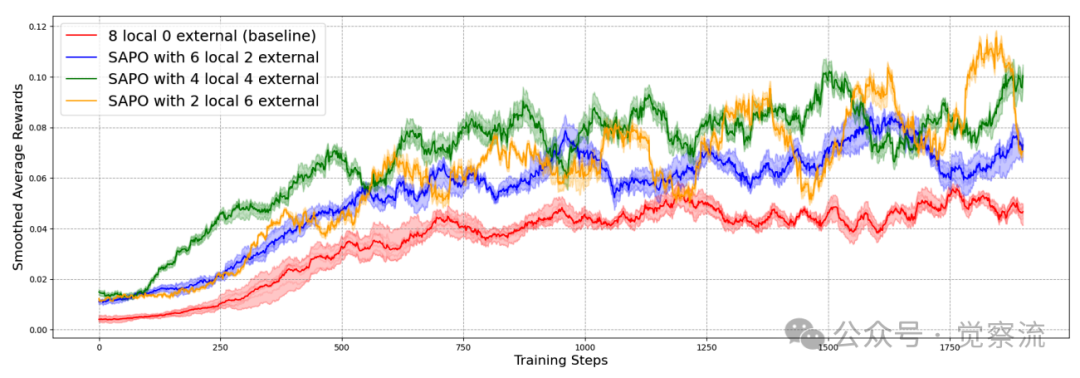
各配置的平均代理奖励(移动平均平滑)
"顿悟"的涟漪效应:一旦一个模型找到正确解法,该经验会迅速在Swarm中传播,抬升所有模型的性能基线。研究观察到通过采样网络中"共享"的rollouts,它使"Aha moments"得以传播,从而引导学习过程。这种正向反馈循环加速了整体学习效率。
值得注意的是,4 local/4 external配置不仅达到了更高的峰值奖励,还保持了更稳定的训练过程。这表明自主探索与集体借鉴之间存在一个"甜蜜点"——过多依赖外部rollouts会导致模型"忘记"已学知识,而完全依靠自我探索则进步缓慢。4/4的平衡点恰好最大化了"Aha moments"的传播效益,同时保留了足够的自主探索空间。
研究特别解释了为什么需要移动平均平滑:由于策略参数的变化比单个训练步骤慢,移动平均有效地平均了奖励,就像策略被冻结一样。因此,平滑曲线可以合理估计跨任务的预期平均奖励。上图中使用了窗口大小为100的移动平均平滑,这使得曲线能更好地反映策略的实际性能,而非单次训练步骤的随机波动。
规范表达的自发涌现:实验中研究人员最初为确保输出格式正确设置了专门的奖励,但很快发现这完全是多余的。在早期实验中,研究人员添加了格式奖励,但很快移除了它。SAPO中的经验共享使其变得不必要,因为关于正确格式的知识(ReasoningGYM验证器所期望的)几乎立即在整个swarm中传播,无需显式的格式奖励信号。这一现象表明,SAPO不仅能加速知识获取,还能促进行为标准化的自组织演化。
协作的阴暗面:分析2/6配置的震荡现象,揭示了两种关键机制:(1)当高性能节点过度依赖外部rollouts时,它们可能被低质量回答反向污染;(2)当多数节点只索取不贡献时,共享池的整体质量就会持续下滑。
这两种效应叠加,形成了"学得快、忘得更快"的剧烈震荡——提醒我们,健康的Swarm需要合理的采样策略与贡献激励并存。
研究明确指出,注意到基线显示出更低的变异性,随着外部rollouts比例的增加,振荡水平也增加。特别是2 local/6 external设置,随着训练的进行显示出强烈的振荡。将此解释为由于两种有趣的网络效应:(i)当高性能智能体过度依赖外部rollouts时,它们的进展可能会受到表现较差的智能体答案的负面影响;(ii)当智能体从swarm中抽取许多rollouts但集体贡献太少时,共享池的质量就会下降。综合起来,这些效应导致陡峭的学习和遗忘行为,解释了振荡模式。
这一现象在实际应用中至关重要。以2/6配置为例,当一个高性能节点(如在base_conversion任务上已掌握正确方法的模型)过度依赖外部rollouts时,它可能会采样到其他节点生成的错误解答(如将二进制"101"错误地转换为十进制"3"而非"5")。这些错误解答被重新编码后,会误导高性能节点的训练方向,导致其性能下降。同时,如果大多数节点只采样不贡献,共享池中的高质量rollouts比例会不断降低,形成恶性循环。
现实世界的回响:来自数千节点的开源启示
为了验证SAPO在真实环境中的有效性,Gensyn团队组织了一场开源演示,吸引了数千名社区成员参与,使用各种硬件和模型配置贡献训练资源。
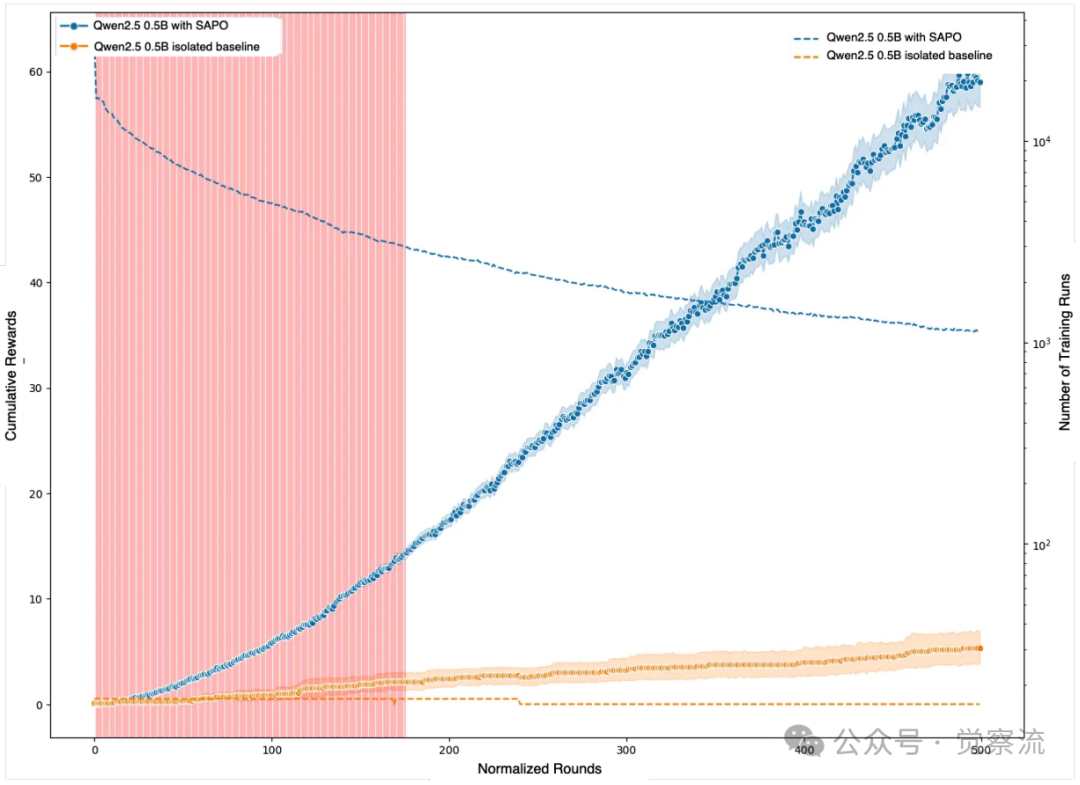
Swarm训练与孤立训练的性能对比(经p值调整)
上图清晰展示了Swarm训练与孤立训练的性能对比。红色区域表示经调整后的p值大于0.05,即性能差异不具有统计显著性;当轮次超过约175时,Swarm训练的性能显著超越孤立训练,这一统计显著性持续至训练结束。
上图通过统计检验清晰地展示了SAPO在真实环境中的有效性边界。图中红色区域表示经调整后的p值大于0.05,即Swarm训练与孤立训练的性能差异不具有统计显著性。然而,在约175个标准化训练轮次之后,红色区域消失,表明Swarm训练的性能显著超越了孤立训练。这一发现至关重要,它用数据证明了SAPO的协作效应不是偶然的,而是随着训练的深入,集体智慧的红利会稳定地显现出来。
去中心化AI的实践:这项实验证明,SAPO能够有效利用全球分散的消费级硬件资源,将数千台异构设备(包括普通MacBook)转化为强大的训练网络。开源演示中,每个参与节点有唯一的对等标识符,关联元数据如正在训练的模型类型,经过每轮后,节点与"judge"进行以下交互:(i)节点请求评估,(ii)judge从ReasoningGYM任务中随机抽样一个问题并发送给节点,(iii)节点生成答案(即pass@1)并提交给judge,(iv)judge使用适当的ReasoningGYM验证器对答案进行评分。
值得注意的是,此次演示中的swarm是一个短暂的环境(ephemeral environment),节点来来去去或偶尔停止然后重新启动。因此,研究团队根据个人参与的总轮次来标准化轮次,确保了比较的公平性。这种短暂环境的处理方式,为SAPO在真实世界分布式系统中的应用提供了宝贵经验。
模型能力的"甜蜜点":分析显示,并非所有模型都同等受益于SAPO。中等规模模型(如0.5B参数的Qwen2.5)是SAPO的最佳拍档,它们有足够的学习能力去吸收和传播经验,又不会因自身过强而"看不上"外部经验。研究发现,对于Qwen2.5模型(0.5B参数),swarm参与始终导致随时间推移的累积性能提升。相比之下,更强的模型(如0.6B参数的Qwen3)在Swarm中提升有限,暗示了SAPO的适用边界。
这一现象表明,中等容量模型是SAPO的最佳受益者——它们有足够的学习能力去吸收和传播经验,又不会因自身过强而"看不上"外部经验。更强的模型可能已经具备足够的推理能力,减少了从群体中学习的边际收益。
"无过滤"采样的教训:在开源Demo中,模型采用简单的均匀随机采样从swarm中选择rollouts,没有进行任何过滤。这导致"没有有用奖励信号的rollouts在swarm中被过度代表"。研究团队推测,通过更好的采样策略,更强大的模型也可以从参与swarm中受益。这一发现指明了未来改进方向——开发更智能的采样机制,如基于优势值过滤,以释放SAPO的全部潜力。
在控制实验中,所有节点首先丢弃优势值为零的rollouts,然后从swarm中剩余的rollouts中均匀采样。这一机制在开源Demo中未能有效实施,导致了低质量rollouts的泛滥。这表明,有效的rollout过滤机制是SAPO成功的关键要素之一。
具体来看,"无过滤"采样问题在开源Demo中尤为明显。当所有模型都采用简单的均匀随机采样时,那些生成大量低质量rollouts的节点(如性能较差或配置不当的节点)会过度影响共享池的质量。这导致即使是一个高性能节点,也可能频繁采样到无用的rollouts,降低了整体学习效率。研究团队观察到,通过引入优势值过滤(即只采样那些至少包含一些"正向信号"的rollouts),可以显著提高共享经验的质量和有效性。
超越语言,构建自组织的AI生态系统
SAPO不仅是一项技术突破,更为未来AI训练开辟了广阔想象空间:
稳定性进阶:研究指出,稳定性仍然是一个重要的开放问题:过度依赖外部rollouts经常导致振荡和遗忘。未来工作可能探索自适应平衡机制——根据模型当前能力动态调整本地与外部样本比例,或引入元策略智能过滤共享经验。论文建议,将SAPO与基于奖励的共享、RLHF或生成式验证器相结合的混合方法可能有助于解决这个问题。
特别是在无法假设信任的大规模swarm设置中,一个有希望的方向是开发元策略,用于自适应平衡本地与共享rollouts,或战略性过滤swarm样本。这些元策略可以基于模型当前性能、共享经验的质量评估等因素,动态调整经验采样策略,避免陷入"学得快、忘得更快"的陷阱。
异构性的终极想象:
- 专业化分工:不同节点可自然演化出不同角色(如生成者、验证者、优化者),形成类似MALT的多角色协作生态。研究提到,增加更多异质性可以使swarm效应更强,并为SAPO指明了一个有希望的未来工作方向。
- 人类融入:在合适的激励机制下,人类可以成为Swarm中的"智慧节点",提供高质量初始经验或关键反馈。论文指出,群体中的节点无需参与训练,且可采用任意兼容策略;因此,人类或其他非传统策略原则上均可充当群体中的生成器。
多模态的星辰大海:SAPO的框架不局限于语言模型。研究展望,虽然本研究重点放在语言模型上,但SAPO对数据模态是无感的,可以相当普遍地应用。在GenRL平台中,已经存在一个文本到图像的Swarm:一些节点仅基于美学分配奖励,而其他节点仅基于CLIPScore分配奖励。最终生成的策略能够产出同时满足这两种类型奖励的图像。这个案例生动地展示了SAPO如何在一个去中心化的网络中,自发地融合多元甚至主观的价值标准,催生出更符合复杂人类需求的AI产物。这为未来构建"审美共识"或"价值观对齐"的AI系统提供了全新的技术路径。
值得注意的是,SAPO对任务有特定要求:任务必须是可验证的(即答案可以高效且算法化地检查正确性),并且rollouts必须具有相同或兼容的模态。在实践中,由于节点会本地过滤swarm中的样本,关于模态的假设可以省略,这些不同模态的rollouts在不兼容时会被简单忽略。
混合方法的创新潜力:SAPO与传统方法的结合可能产生更强大的训练框架。研究指出,基于人类偏好数据的RLHF训练使用奖励模型,而RLVR则利用基于规则的、可程序化验证的奖励函数。SAPO建立在这些RL微调方法之上,但不需要单个策略生成所有rollouts,也不需要多个策略之间的同步。这种混合方法可能解决SAPO当前面临的稳定性挑战,同时保留其去中心化协作的优势。
总结:Sharing is Caring, for AI too
SAPO代表的不仅是一种算法创新,更是一种哲学转变:在AI的世界里,开放、共享、协作是通往更高智能的高效路径。通过将经验共享转化为核心优势,SAPO为语言模型后训练提供了一条可扩展且实用的途径。
这项研究有力证明,在一个由全球志愿者运行的、跨越数千台消费设备的网络上进行大规模AI训练不仅是可能的,而且是高效的。SAPO的魔力在于,它让每一次"顿悟"都不再是孤立的火花,而是能够点燃整个群体的火炬。当一个模型在代数题中找到窍门,或在逻辑谜题中灵光一现,这个发现会通过纯文本的rollout,在Swarm中悄然传播,最终让所有参与者共同受益。这不仅是算法的胜利,更是协作精神的体现。
SAPO的实验证明,平衡的经验共享(4 local/4 external)几乎使性能翻倍,实现了94%的累积奖励提升。这一数字具体意味着:在相同训练轮次下,SAPO训练的模型能够正确解答近两倍数量的问题。然而,研究也警示我们,过度依赖外部rollouts会破坏学习稳定性,导致陡峭的学习和遗忘行为。这提醒我们,真正的协作智慧在于找到自主探索与集体借鉴的平衡。
SAPO的独特价值在于它并不为了产生专业化的节点或协调协作,但通过经验共享,节点间接从彼此的探索和推理中受益,产生更丰富的训练信号。这种自组织特性使得swarm能够自然演化出高效的协作模式,而无需中央协调。正如研究指出,SAPO通过经验共享加速训练,捕获多智能体方法的诸多优势,通过RL微调鼓励个体在将这些优势传递给swarm中的其他成员之前先从中受益。
需要明确指出的是,SAPO并非万能解决方案,它主要适用于"verifiable tasks"(答案可高效算法化验证的任务)。对于没有明确验证标准的任务,SAPO的效果可能会受到限制。同时,稳定性仍然是一个重要的开放问题,过度依赖外部rollouts导致的振荡和遗忘问题仍需进一步研究。
在这个AI技术飞速发展的时代,SAPO提醒我们:真正的智能进化不仅来自于单个模型的规模扩张,更源于群体智慧的有机连接。当每个模型都能从他者的"顿悟"中受益,整个AI生态系统的进化速度将远超我们的想象。因为在这个时代,Sharing is Caring, for AI too——分享即关怀,这不仅是人类社会的美德,也是人工智能进化的关键法则。想进一步了解这个研究的朋友,可以参见文末的参考资料,里面有这个研究的开源仓库。
最后,这个研究让我想起 ANP (Agent Network Protocol,#ANP开源技术Community),想想在未来的智能体互联网中,每个智能体如果除了工作协同,还行借助 SAPO 实现协同进化,这将是怎样的未来?


