近日,豆包语音对话功能迎来更新,可以说4种地道方言,包括粤语、四川话、东北话及陕西话。用户打开豆包App对话框,发送简单的文字或语音指令,要求豆包使用上述方言对话,通过默认的“温柔桃子”升级版音色,即可开启对话体验。
据悉,该功能借助豆包语音模型方言迁移技术,实现单音色说多方言,且具备思考能力,可根据用户意图,灵活切换方言。记者实测发现,豆包可以精准识别相关方言语音和词汇,并用地道自然的方言回应。对于不熟悉普通话的用户,尤其是习惯说方言的老年群体来说,该功能有助于辅助沟通,提高效率。
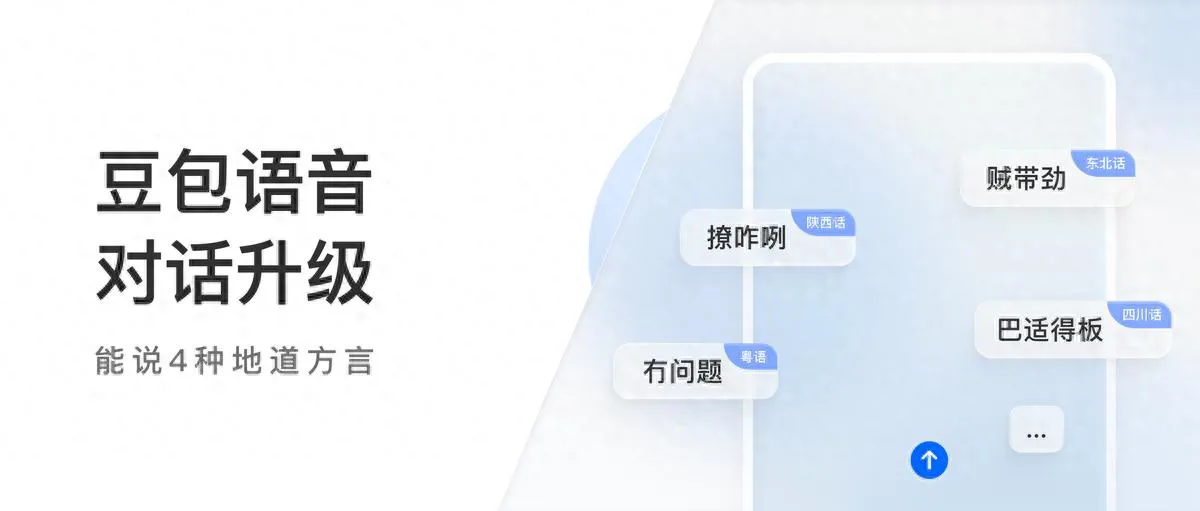
除了能说4种地道方言外,豆包在对话过程中能听懂上海话、南京话等18种方言。上述能力借助了将口语转录为文本的ASR技术 (Automatic Speech Recognition),准确性和效率提升明显。
豆包相关负责人表示,豆包致力于提升不同人群的使用体验,希望不同地域的用户能够更轻松、自然地与豆包进行语音交互,享受技术带来的便捷。
除此之外,近日2025年字节跳动奖学金颁奖典礼也在北京举行,共20位博士获奖。相比往届,此次奖学金不仅增加了获奖名额,也将奖学金从10万元升级为20万元(含10万元现金、10万元专项学术资源补贴)。此外,字节跳动还为每位获奖同学的导师提供10万元奖励,感谢导师在学子成长与科研道路上的付出。

图:20位获奖同学合影
字节跳动奖学金计划始于2021年,希望寻找并激励最优秀的技术在校生,助力其学术及科研,用技术回馈社会。过去五年,该计划已经为67位优秀学子提供了科研支持。
据统计,2025年字节跳动奖学金计划收到了中国、新加坡66所高校500余名同学的申请。经过严格评审,来自清华、北大、人大、复旦、华中科技大学、香港大学、新加坡国立大学、南洋理工大学的20位学子获奖,覆盖大模型、机器学习、多模态、AI Infra、机器人、AI for Science、硬件等多个研究领域。
本届字节跳动奖学金获奖名单中,清华和北大入选的人数最多,各入选6人。人大和香港大学也各有2位同学获奖。获奖同学表示,字节奖学金是对他们研究成果的认可,也通过该项目,接触到工业界的技术实践、认识到不同研究领域的优秀人才。一些获奖导师表示,此前已经和字节在相关研究领域开展了深入合作,字节为高校学术研究和人才培养提供了资源支持。
颁奖典礼上,字节跳动技术副总裁杨震原对获奖师生表示祝贺,并分享了字节跳动在大规模推荐系统、AI for Science、XR、大模型等领域长期探索的经验,鼓励同学们保持耐心和热爱,挑战真正有高度的技术难题,为社会创造更大价值。


