据悉,豆包编程已于近日升级,上线创作、问答双模式,用户可结合实际场景选择对应模式。创作模式新增参考图和画板功能,零基础用户上传参考图或者使用画板后,模型能够直接还原设计,达成预期的产品效果。升级后,豆包编程可根据用户需求,基于内置的Agent自动规划并智能调用多种工具。问答模式则聚焦专业编程场景,可针对性解答技术问题、修复代码并一键运行。
针对创作模式,该模式致力于打造零门槛的编程体验。本次升级后,用户只需通过自然语言、图片参考或画板草图描述需求,交给豆包编程Agent进行自动规划与调用工具,即可生成内容充实的网页。
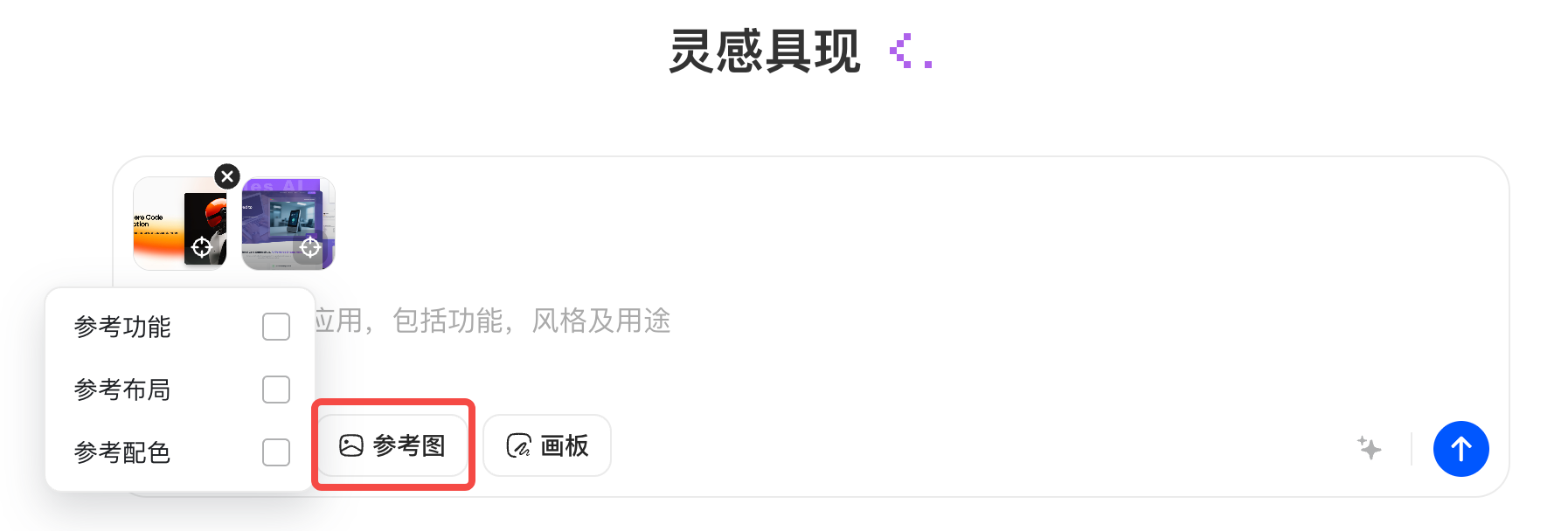
上传参考图,模型帮你还原设计
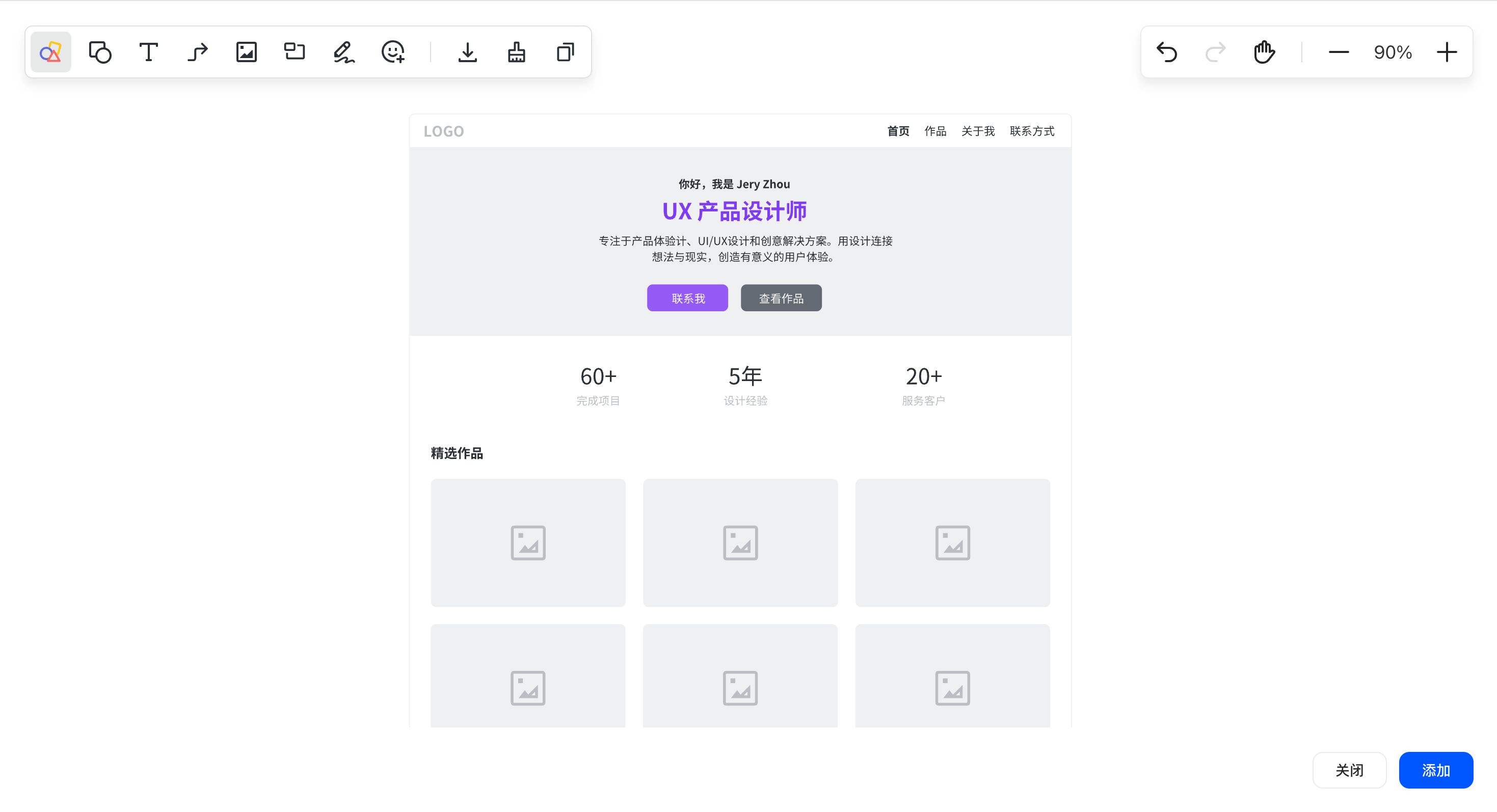
打开画板,绘制流程图,线框图表达需求
豆包编程提供适配多场景的灵感模板,支持实时预览与可视化编辑,升级后的豆包编程能够实现局部代码的快速更新,优化过程更少等待。同时,系统能够自动记录修改历史,用户可随时切换版本。

可选择场景化的设计模板
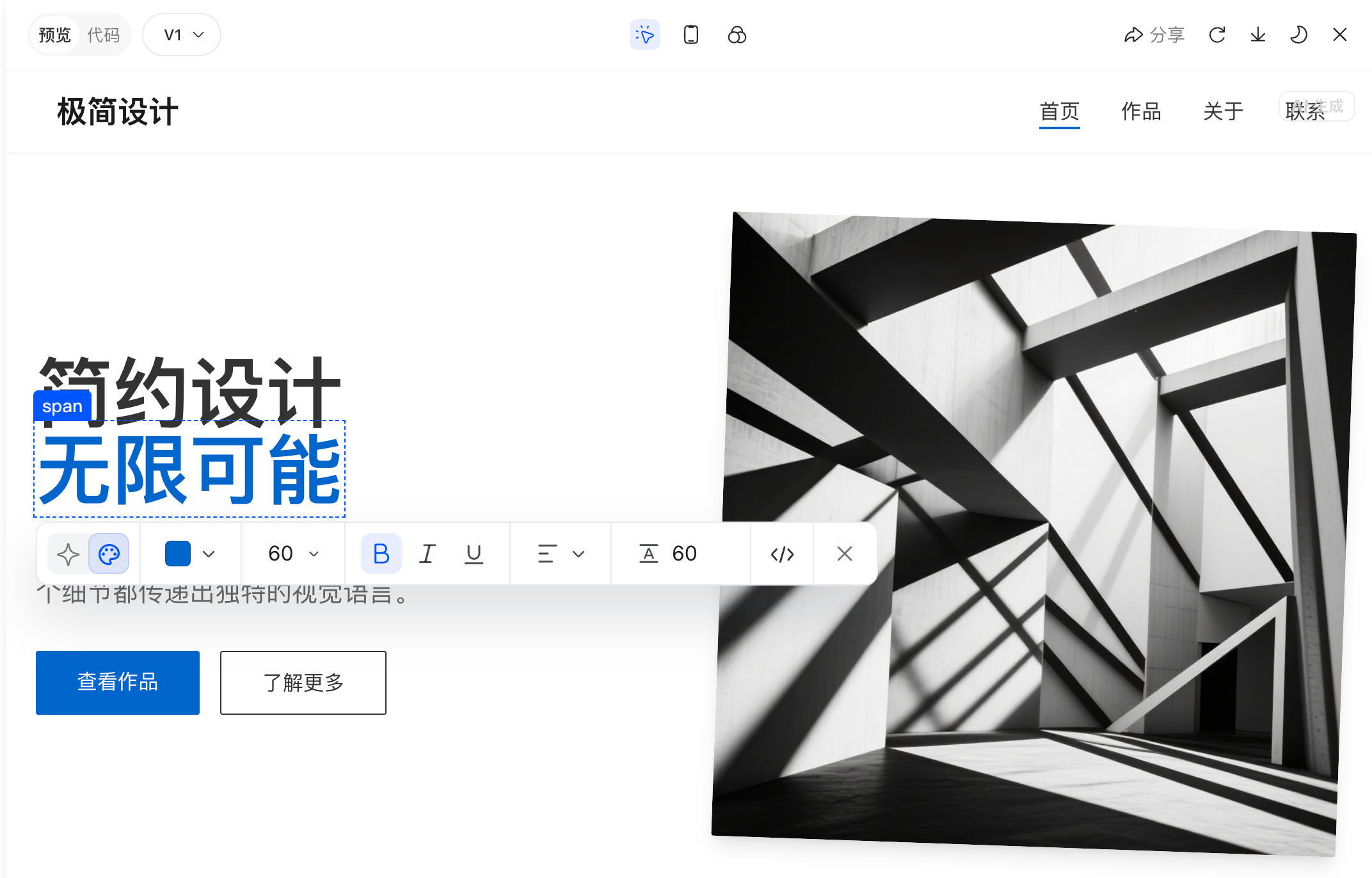
灵活编辑
平台支持一键分享作品或下载代码。如需查看往期作品,用户可在“我的应用”功能中对历史作品进行可视化管理,提高项目查找效率。
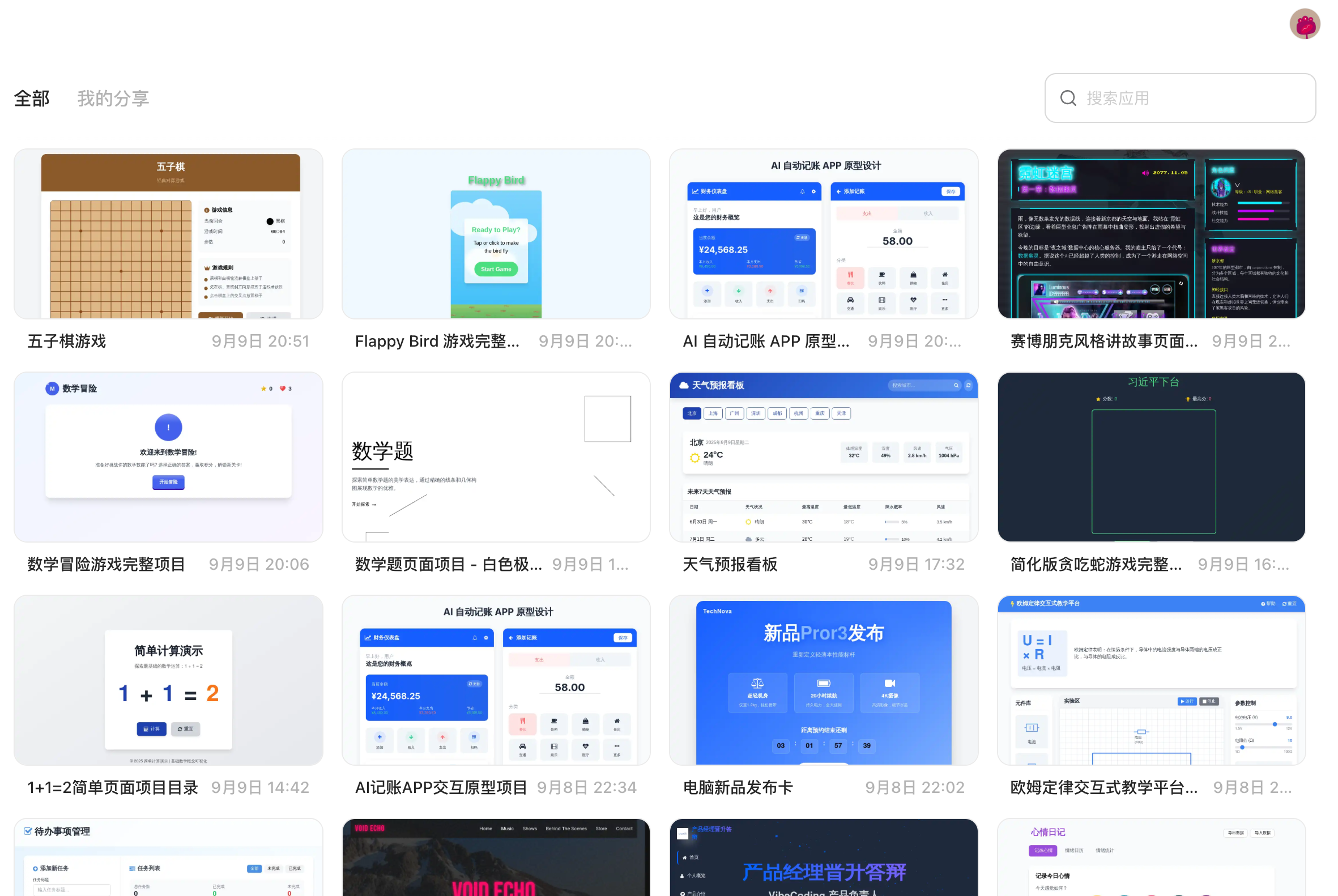
轻松查找我的应用
问答模式则专注于知识、代码、文件与仓库的解答,是用户的智能编程伙伴。它支持多附件提问,能准确理解复杂的上下文,还配有沉浸式代码阅读器与划词问答功能。当代码运行出错时,它可以自动分析错误信息,提供修复建议或直接修复。
代码精准划词问答
值得关注的是,基于本次更新,豆包编程已经可以覆盖多种使用场景,包括:制作效率工具(个人待办清单、图片压缩工具)、数据可视化(把 Excel 数据转成动态折线图、热力图等)、制作汇报演示材料(交互网页报告及自动配图)、开发响应式网站等,就算没有代码基础,也能完成专业级的创作。
相关负责人表示,豆包编程希望让用户每次提问和灵感都能更快转化为可运行、可分享的成果。此次升级后,豆包编程配备了互补的创作、问答双模式,还拥有满足用户多元化输入需求等能力,将持续提升作品完成度与美观度。
据悉,豆包编程的创作模式背后搭载自研的编程模型,具备更优的多模态识别、更好的应用生成美观度,并具备复杂任务规划与工具调用能力,能确保生成结果更稳、更美、更贴合用户意图。
目前,用户可以通过豆包电脑版或网页版,体验最新的编程能力。


