几千人盲投,Kimi K2超越DeepSeek拿下全球开源第一!
歪果网友们直接炸了,评论区秒变夸夸打卡现场:
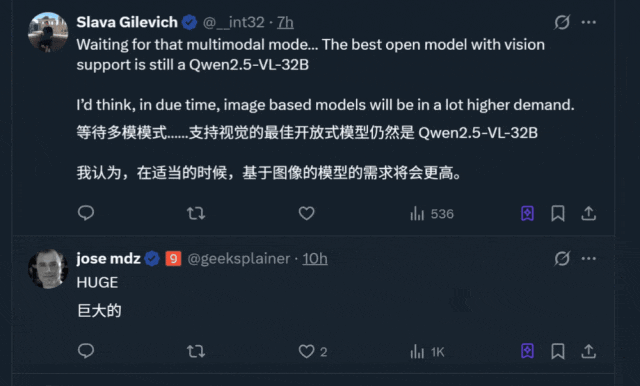
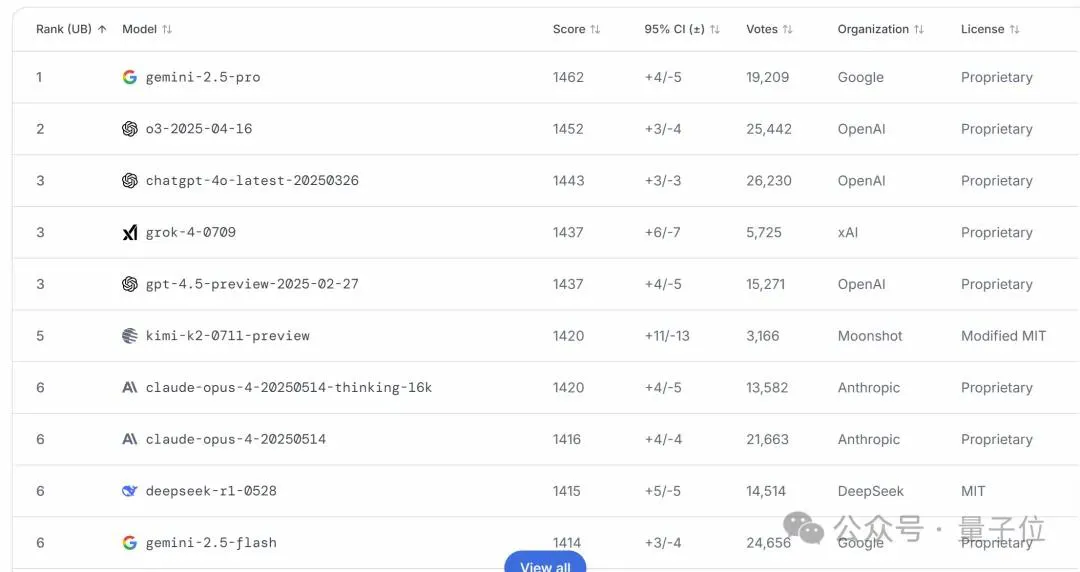
今天,竞技场终于更新了Kimi K2的排名情况——
开源第一,总榜第五,而且紧追马斯克Grok 4这样的顶尖闭源模型。
并且各类单项能力也不差,能和一水儿闭源模型打得有来有回:
- 连续多轮对话并列第一,o3和Grok 4均为第四;
- 编程能力第二,和GPT 4.5、Grok 4持平;
- 应对复杂提示词能力第二,和o3、4o位于同一梯队;
- ……
甚至眼尖的朋友也发现了,唯二闯入总榜TOP 10的开源模型都来自中国。(DeepSeek R1总榜第8)

当然了,即使抛开榜单不谈,Kimi这款新模型过去一周也确实火热——
公开可查战绩包括但不限于下面这些:
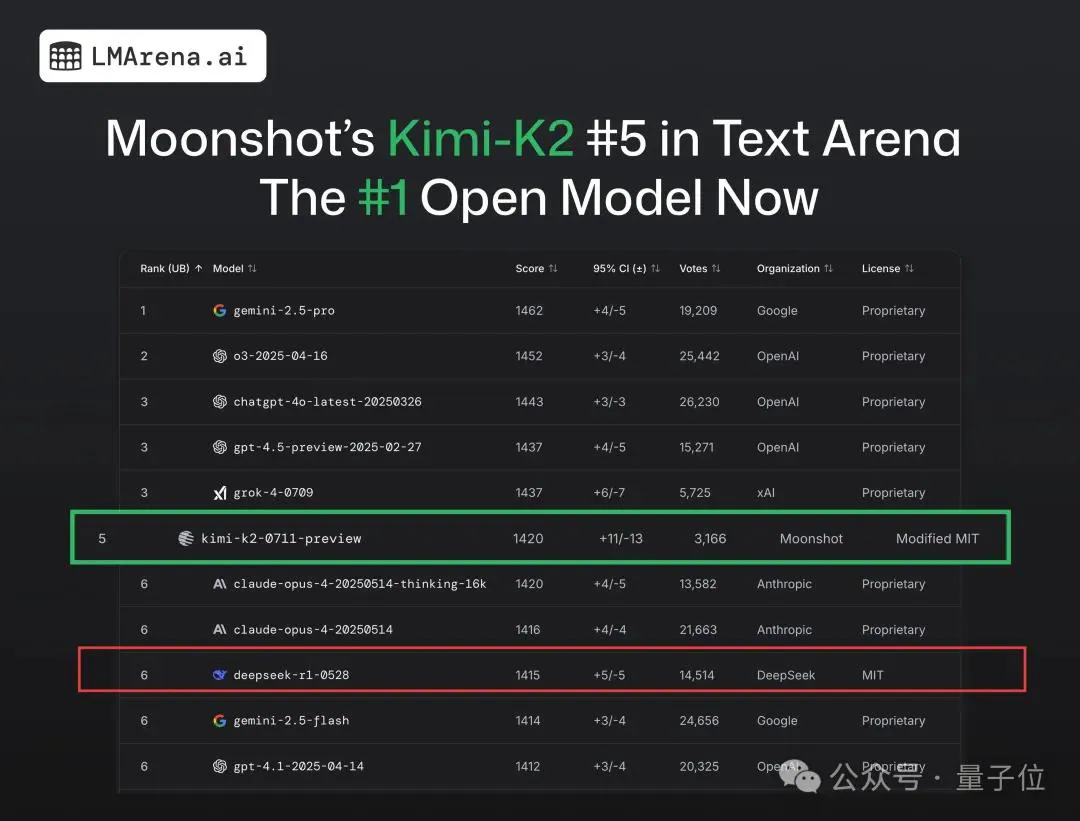
从实打实的数据来看,发布这一周里,Kimi K2在开源社区就获得了相当关注度和下载量。
GitHub标星5.6K,Hugging Face下载量近10万,这还不算它在中国社区的应用。

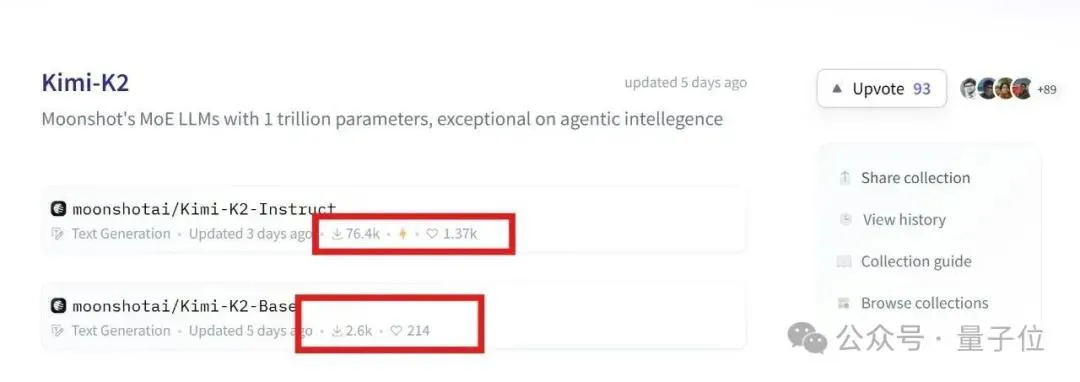
连AI搜索引擎明星创企Perplexity CEO也亲自为它站台,并透露:
Kimi K2在内部评估中表现出色,Perplexity计划接下来基于K2模型进行后训练。
甚至由于访问的用户太多了,逼得Kimi官方也出来发公告:
访问量大+模型体积大,导致API过慢。

……
不过就在一片向好之时,人们关于“Kimi K2采用了DeepSeek V3架构”的质疑声再度升温。
对此,我们也找到了Kimi团队成员关于K2架构的相关回应。
总结下来就是,确实继承了DeepSeek V3的架构,不过后续还有一系列参数调整。
p.s. 以下分享均来自知乎@刘少伟,内容经概括总结如下~
一开始,他们尝试了各种架构方案,结果发现V3架构是最能打的(其他顶多旗鼓相当)。
所以问题就变成了,要不要为了不同而不同?
经过深思熟虑,团队给出了否定答案。理由有两点:
一是V3架构珠玉在前且已经经过大规模验证,没必要强行“标新立异”;二是自己和DeepSeek一样,训练和推理资源非常有限,而经过评估V3架构符合相关成本预算。
所以他们选择了完全继承V3架构,并引入适合自己的模型结构参数。
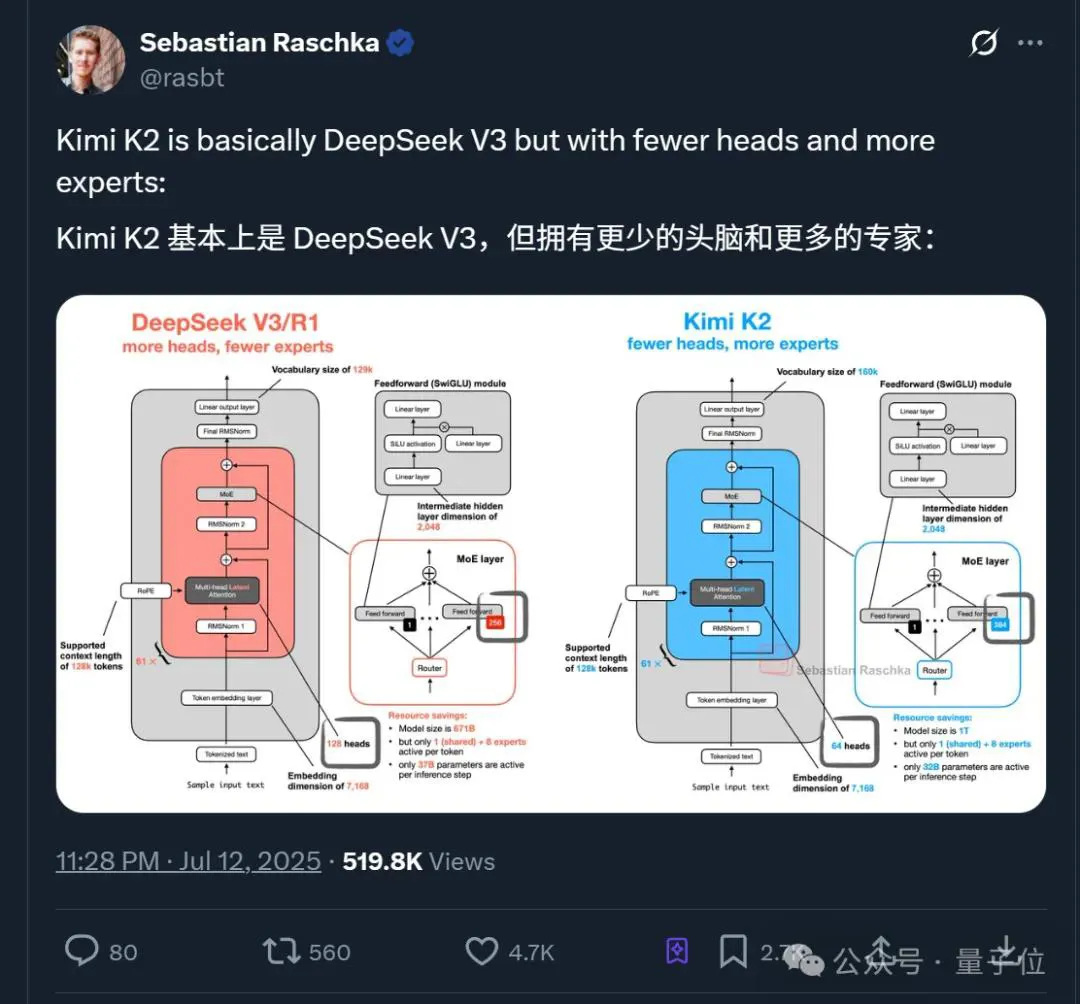
具体而言,K2的结构参数改动有四点:
- 增加专家数量:团队验证了在激活参数量不变的情况下,MoE总参数增加仍有益于loss下降。
- 注意力头head数减半:减少head数节省的成本,刚好抵消MoE参数变大带来的开销,且效果影响很小。
- 只保留第一层Dense:只保留第一层为dense,其余都用MoE,结果对推理几乎无影响。
- 专家无分组:通过自由路由+动态重排(EPLB)可以应对负载不均衡,同时让专家组合更灵活,模型能力更强。
最终得到的推理方案就是,在相同专家数量下:
虽然总参数增大到1.5倍,但除去通信部分,理论的prefill和decode耗时都更小。即使考虑与通信overlap等复杂因素,这个方案也不会比V3有显著的成本增加。
就是说,这是一种更“精打细算”的结构调优。
而且这种放弃自己的模型架构路线,彻底走DeepSeek路线的做法,也被国内网友评价为“相当大胆”。
OK,以上关于Kimi和DeepSeek架构之争的问题落定后,我们再把目光拉回到这次最新排名。
一个很明显的趋势是:「开源=性能弱」的刻板印象正在被打破,开源模型已经越来越厉害了。
不仅榜单上的整体排名在上升,而且分数差距也越来越小。
仔细看,模型TOP 10总分均为1400+,开源和闭源几乎可以看成位于同一起跑线。
而且这次拿下开源第一的Kimi K2,总分已经非常接近Grok 4、GPT 4.5等顶尖闭源模型了。
换句话说,以前我们可能还要在模型能力和成本之间作取舍,但随着开源力量的崛起,多思考一秒钟都是对开源的不尊重(doge)。
与此同时,越来越多的行业人士也表达了对开源崛起的判断。
艾伦人工智能研究所研究科学家Tim Dettmers表示:
开源击败闭源将变得越来越普遍。

Perplexity CEO也多次在公开场合表示:
开源模型将在塑造AI能力的全球扩散路径中扮演重要角色。它们对于因地制宜地定制和本地化AI体验至关重要。
而在已经逐渐崛起的开源模型领域,TOP 10中唯二开源、且都是国产模型的含金量还在上升。


