
大家好,我是肆〇柒。今天我们一起阅读一篇来自中国科学院大学(UCAS)、阿里巴巴高德地图(AMAP)与中科院智能系统与工程研究中心(CRISE) 联合团队的最新工作——《ImagerySearch: Adaptive Test-Time Search for Video Generation Beyond Semantic Dependency Constraints》。这项研究直面当前视频生成模型在“想象力任务”中的系统性失效,提出了一种无需额外训练、仅靠测试时自适应策略即可显著提升长距离语义生成能力的新范式。
当提示为“骆驼在沙漠行走”时,Wan2.1能生成合理视频;但当提示仅改变一个动词,变为“骆驼打包行李”时,模型便彻底失效——生成的仍是骆驼行走的普通场景,完全忽略了“打包”这一关键动作。

长距离语义提示挑战
上图直观揭示了这一困境:左侧短距离语义提示(语义距离0.3)下,模型表现稳健;右侧长距离语义提示(语义距离0.86)下,Wan2.1及现有测试时扩展方法(VideoT1、EvoSearch)均无法正确生成“打包”动作,而ImagerySearch则能生成骆驼用鼻子和前蹄整理行李的连贯动作(上图右下角橙色框)。这种“最小语义改动引发最大生成差异”的现象,暴露了当前文本到视频(T2V)生成模型的核心瓶颈:它们擅长复现现实,却难以理解人类的想象力。
长距离语义为何成为T2V模型的致命短板?
长距离语义提示具有明确的定义特征:对象与动作间语义距离大(如“交通灯跳舞”)、实体在训练数据中极少共现(ImageNet+Kinetics组合)、平均语义距离达0.86,远超现实场景基准(0.3-0.4)。这种提示代表了人类想象力的核心——将通常不会共现的概念进行创造性组合,而正是这种能力使人类能够超越现实经验进行思考和表达。
生成模型在处理这类提示时面临两大核心挑战。首先是模型语义依赖约束:生成模型对长距离语义提示表现出强语义依赖约束,难以泛化到训练分布之外的想象力场景。也就是,当提示中对象与动作之间存在长距离语义关系时,模型往往无法建立正确的关联,导致“语义漂移”现象。例如,“骆驼打包行李”这一提示中,“骆驼”与“打包”的语义距离较大,模型倾向于忽略“打包”动作,转而生成“骆驼在沙漠行走”等更常见的场景。这一现象源于扩散模型在训练过程中主要学习现实世界中常见的语义组合,对于罕见的、创造性的语义关系缺乏建模能力。
其次是想象力训练数据稀缺:
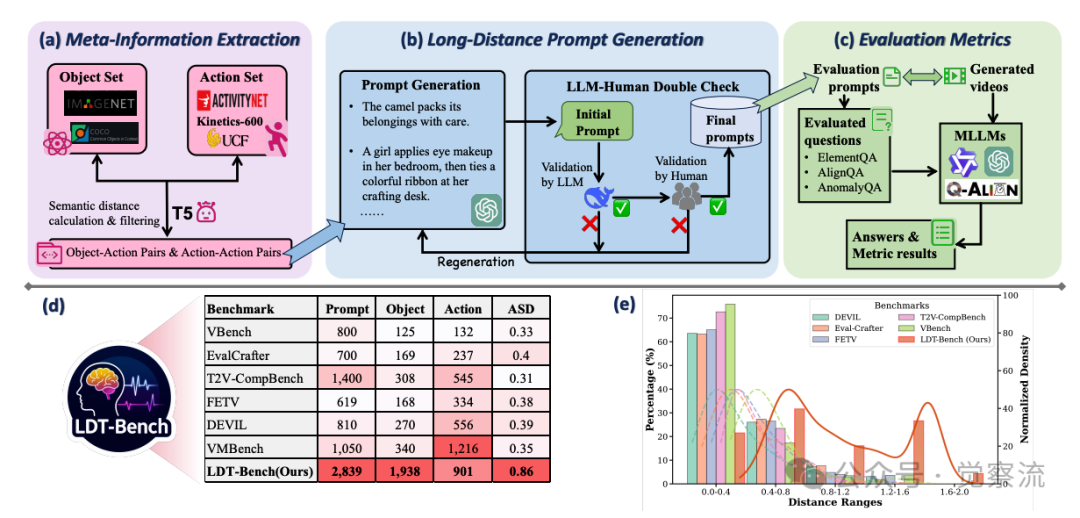
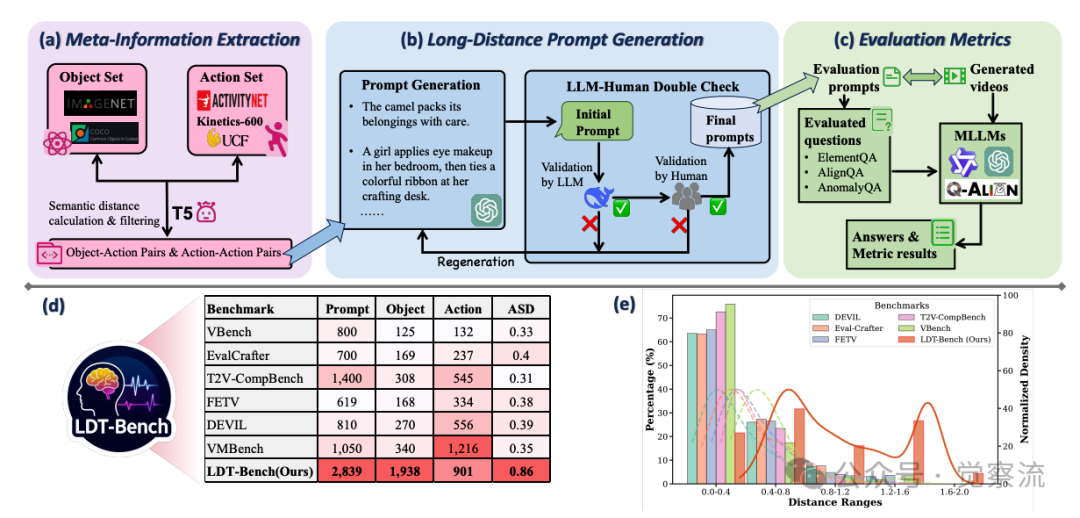
如(d)所示-不同基准数据集分布对比
如上图(d)所示,清晰展示了这一问题。主流视频数据集(如ImageNet-1K、Kinetics-600、ActivityNet等)主要包含现实场景,提供有限的想象力组合,这些组合通常具有长距离语义关系。数据显示,现有训练数据中长距离语义关系的覆盖率极低,导致模型缺乏处理此类提示的训练经验。在ImageNet-1K和Kinetics-600的组合中,对象-动作对的平均语义距离仅为0.3-0.4,而LDT-Bench中的平均语义距离高达0.86,表明现实数据集与想象力场景之间存在巨大差距。
现有方法的局限性进一步加剧了这一问题。传统测试时搜索(TTS)方法(如VideoT1、EvoSearch)使用固定搜索空间和静态奖励函数,无法适应开放式的创意生成需求。这些方法假设所有提示具有相似的复杂度,采用统一的搜索策略和评估标准,忽视了长距离语义提示所需的额外认知资源。例如,VideoT1在所有提示上使用相同的采样数量(N=10)和固定的奖励函数,而EvoSearch虽然引入了进化算法,但其搜索空间和奖励机制仍然是静态的,无法针对不同语义复杂度的提示进行自适应调整。
与之形成鲜明对比的是,人类心智意象构建理论指出:对语义距离大的概念(这也许标志了想象力🤔),人类需投入更多认知资源构建心理意象。这一认知原理为解决长距离语义生成问题提供了关键启示:模型需要根据提示的语义复杂度动态调整搜索策略,为复杂提示分配更多计算资源,同时保持简单提示的效率。
基于这一认知科学发现,研究者提出了ImagerySearch方法,将人类构建心理意象的过程转化为可计算的工程实现:当面对语义距离较大的提示时,系统自动扩大搜索空间并调整评估标准,模拟人类投入更多认知资源的过程。
ImagerySearch核心机制
ImagerySearch的核心思想是将人类心智意象构建的认知原理转化为可计算的工程实现。
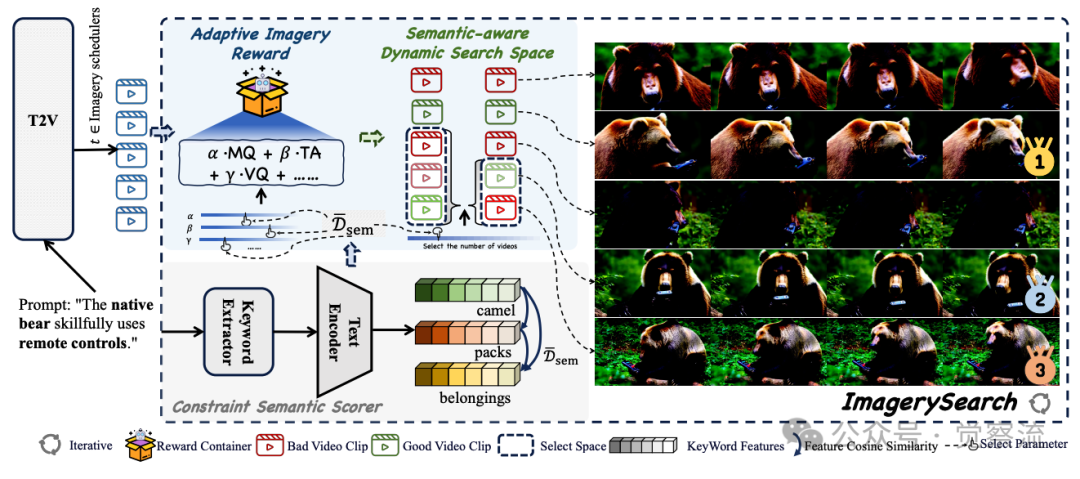
ImagerySearch系统架构
上图展示了其整体工作流程:提示通过约束语义评分器计算语义距离D̄_sem,同时输入到T2V骨干网络(Wan2.1);在Imagery scheduler指定的每个时间步t,系统采样一组候选片段,根据与D̄_sem条件相关的奖励函数进行排序,并仅保留由D̄_sem控制的子集;该循环重复直到生成完成。这一设计使模型能够根据提示的语义复杂度动态调整搜索策略,显著提升长距离语义提示的生成质量。
语义距离 D̄_sem(p) 是 ImagerySearch 的核心调控变量,它像一个“认知难度计”,实时测量提示的想象力挑战程度。当 D̄_sem(p) 接近 0.3(短距离语义)时,系统保持高效精简的搜索;当 D̄_sem(p) 超过 0.8(长距离语义)时,系统自动激活全面的探索模式,为模型提供足够的“认知资源”来构建复杂的心理意象。
SaDSS(Semantic-distance-aware Dynamic Search Space)
为克服固定搜索空间在高语义距离下探索不足的问题(见下图),SaDSS动态扩大采样数量,其核心创新在于根据提示的语义跨度自适应调节采样粒度,使模型在需要时探索更多样化的视觉假设,提高复杂条件下的视觉合理性,同时避免对简单提示产生不必要的计算开销。
如上图b-运动质量指标变化
语义距离的精准计算是SaDSS的基础。如下是这一计算过程:
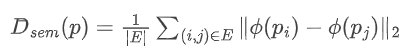
其中,ϕ(·)表示T5编码器嵌入函数,E是提示中关键实体对集合(如对象-动作对、动作-动作对)。在实现中,研究者将高维嵌入通过PCA投影到2D共享语义空间,这一选择基于对不同维度投影效果的实验验证。PCA不仅保留了语义关系的主要特征,还提供了直观的可视化能力,便于筛选高质量的长距离语义提示。在2D空间中,语义相似的概念会自然聚集,而语义距离远的概念则相距较远,这种可视化特性对构建LDT-Bench至关重要。然后计算欧氏距离作为语义距离度量。
关键实体对的提取过程经过精心设计:系统首先通过关键词提取器从提示中识别出对象和动作实体,例如在“骆驼打包行李”中,识别出“骆驼”(对象)和“打包”(动作)作为关键实体。然后,计算这些实体在T5编码器嵌入空间中的距离。为了确保距离计算的准确性,系统排除了介词、冠词等语法词,只关注具有实际语义的词汇。
基于这一度量,SaDSS动态调整候选视频数量:
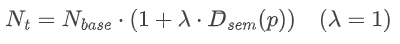
语义距离越大,候选视频数量越多。例如,当D̄_sem(p)=0.86(长距离语义)时,Nt=1.86×Nbase;而当D̄_sem(p)=0.3(短距离语义)时,Nt=1.3×Nbase。这种设计实现了智能平衡:简单提示保持高效,复杂提示扩大探索范围。
关键实现细节表明,ImagerySearch在关键噪声级别{5, 10, 20, 45}处激活搜索,这些特定点的选择基于对扩散过程的系统分析:在去噪早期阶段(如t=45),模型主要确定视频的整体结构和内容;中期(t=20-10)影响动作的连贯性和时序关系;晚期(t=5)则细化视觉细节。通过在这些关键阶段引入搜索机制,ImagerySearch能在最能影响语义对齐的环节进行自适应调整,同时保持计算效率。在每个关键噪声级别,系统根据当前D̄_sem(p)动态确定采样数量,然后对候选视频进行评估和筛选。
也就是,在扩散模型的去噪过程中,早期噪声级别(如t=45)主要影响视频的整体结构和内容,而后期噪声级别(如t=5)则影响细节和视觉质量。ImagerySearch在这些关键点引入搜索机制,确保在最能影响语义对齐的阶段进行自适应调整。例如,对于“交通灯跳舞”这样的长距离语义提示,系统在t=45时可能采样30个候选(Nbase=16, D̄_sem=0.86),而在t=5时可能采样18个候选,以确保在关键阶段有足够的探索空间。
AIR(Adaptive Imagery Reward)
为解决静态奖励无法保障关键元素生成的语义漂移问题,AIR将语义距离融入奖励加权,通过根据提示语义难度调制评估反馈,增强生成视频与长距离语义提示的对齐,是解决“语义漂移”问题的关键。论文中详细阐述了这一创新组件:
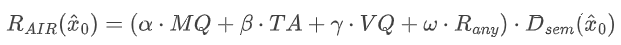
其中,MQ、TA和VQ分别代表Motion Quality(运动质量)、Temporal Alignment(时序对齐)和Visual Quality(视觉质量),这些指标源自VideoAlign;Rany表示可扩展奖励(如VideoScore、VMBench等)。
关键创新在于动态权重机制:α、β、γ和ω根据语义距离D̄_sem动态调整。对于长距离语义提示,系统会强化语义对齐奖励(如TA),降低对视觉质量的过度关注,从而解决“语义漂移”问题。具体而言,当D̄_sem较高时,系统会增加β的权重,使模型更注重时序对齐,确保生成的视频准确反映提示中的语义关系。
AIR的实现包含一个自适应权重调度器,根据D̄_sem(p)动态调整各奖励成分的贡献。例如,当D̄_sem(p)>0.7时,系统将β(TA的权重)提升至0.6,而将γ(VQ的权重)降低至0.2;当D̄_sem(p)<0.4时,系统则将β降低至0.3,γ提升至0.4。这种动态调整确保了奖励函数能够根据提示的语义复杂度进行自适应变化。
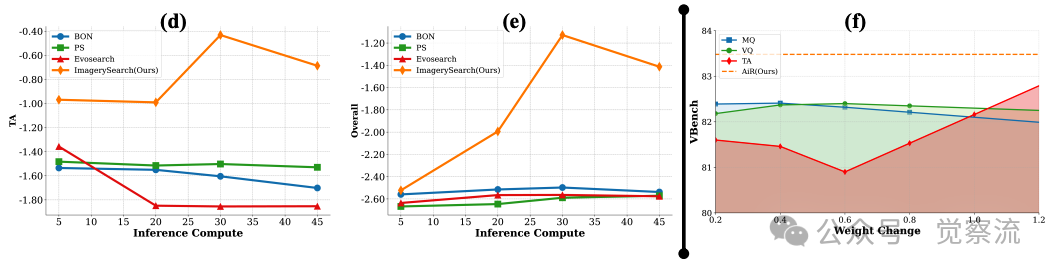
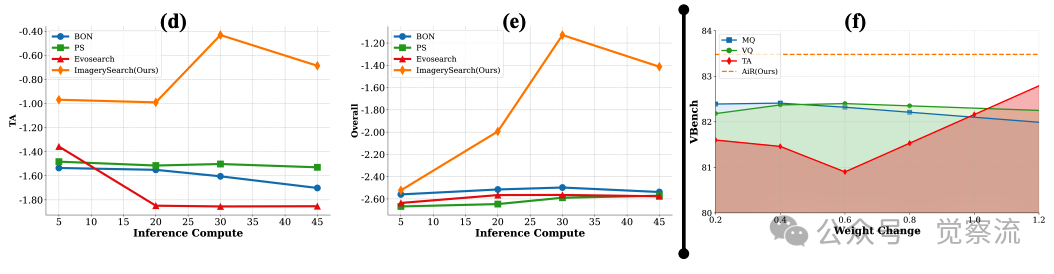
如上图f-奖励权重变化影响分析
上图(f)展示了这一机制的有效性:当奖励权重在0.2-1.2范围内变化时,ImagerySearch的TA(时序对齐)指标显著提升,而MQ和VQ保持稳定。这一结果证明,ImagerySearch对奖励参数变化具有鲁棒性,能够根据提示的语义难度自适应调整评估标准。
AIR的另一个关键特性是其与SaDSS的协同作用。SaDSS负责扩大搜索空间以探索更多可能性,而AIR则负责从这些可能性中选择最符合语义要求的结果。这种协同机制使ImagerySearch能够在保持计算效率的同时,显著提升长距离语义提示的生成质量。
例如,在生成“本地熊熟练使用遥控器”这一提示时,SaDSS会根据高语义距离(D̄_sem≈0.88)扩大搜索空间,生成多个候选视频片段,其中可能包括熊拿着遥控器但未操作、熊操作其他设备、或正确操作遥控器等不同场景。然后,AIR会根据高β权重(强调时序对齐),优先选择那些熊与遥控器互动关系正确的候选,确保最终生成的视频准确呈现“熊使用遥控器”的语义关系。
LDT-Bench:首个面向长距离语义的视频生成评测基准
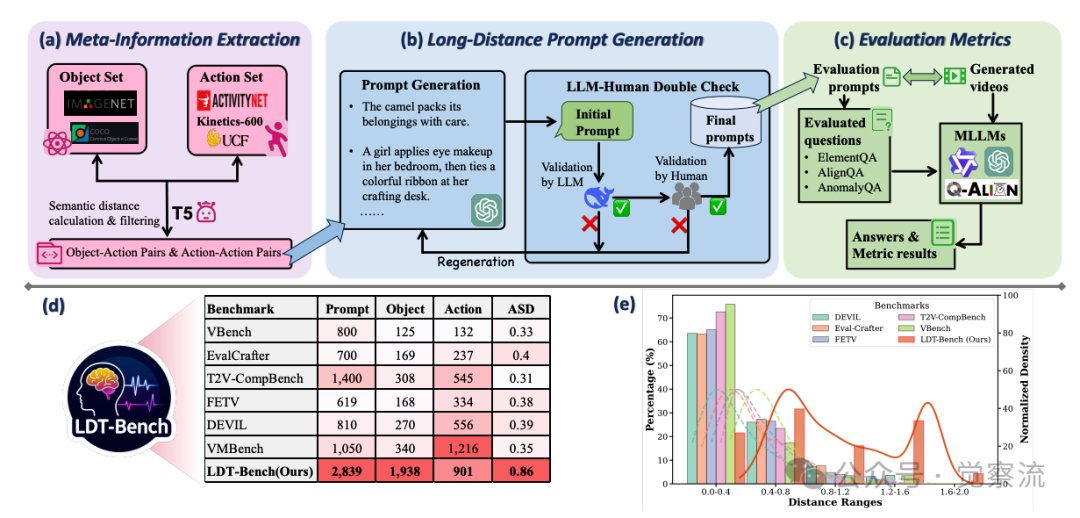
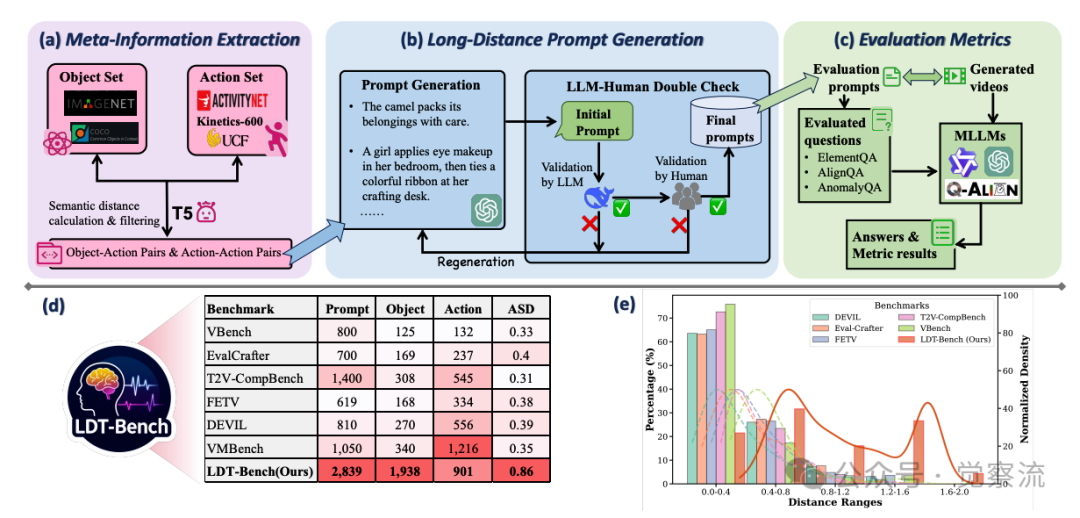
为系统评估模型在长距离语义提示下的表现,研究者构建了LDT-Bench,这是首个专门针对此类任务的评测基准。LDT-Bench的构建流程包含三个关键阶段,每个阶段都经过精心设计以确保提示的质量和多样性。
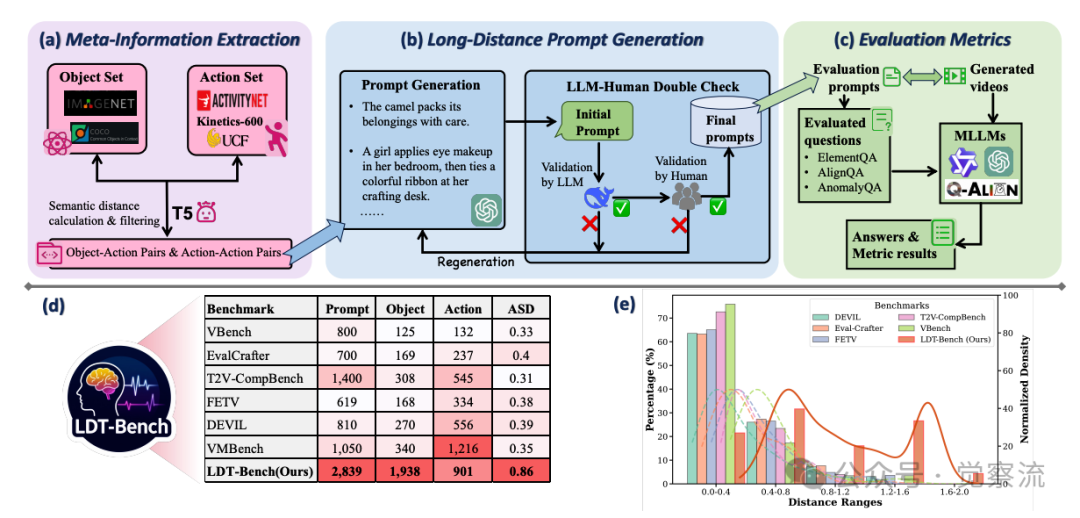 上图(a)-LDT-Bench元信息提取流程
上图(a)-LDT-Bench元信息提取流程
上图(a)展示了第一个阶段:元信息提取。研究者从ImageNet-1K和COCO中提取1,938个对象,从ActivityNet、UCF101和Kinetics-600中收集901个动作。这些集合为后续提示生成奠定了基础。具体来说,对象集覆盖了广泛的类别,从常见的“骆驼”、“交通灯”到较少见的“水母”、“风车”;动作集则包括了“行走”、“跳舞”等基本动作,以及“打包”、“使用遥控器”等复杂动作。
在语义距离计算阶段,每个对象和动作元素通过预训练T5文本编码器编码,获取高维文本特征,然后通过PCA投影到2D共享语义空间。语义距离通过计算元素对之间的欧氏距离来度量。这种投影方法不仅保留了语义关系,还提供了直观的可视化能力,有助于筛选高质量的长距离语义提示。
投影过程的具体实现是:首先将每个对象和动作文本通过T5编码器转换为768维向量,然后使用PCA将这些向量降维到2D空间。选择2D空间是因为它在保持语义距离区分度的同时,提供了直观的可视化能力,便于人工筛选和验证。在2D空间中,语义相似的概念会聚集在一起,而语义距离远的概念则相距较远。
 上图(b)-LDT-Bench长距离提示生成流程
上图(b)-LDT-Bench长距离提示生成流程
上图(b)详细展示了第二个阶段:长距离提示生成。研究者构建了两个候选集:一个通过将每个对象与语义距离最远的动作配对(1,938个对象-动作对),另一个通过匹配语义距离最远的动作对(901个动作-动作对)。从每个集合中选择160个距离最远的对,形成320个高距离提示。随后,GPT-4o用于生成流畅完整的文本提示,每个提示经过DeepSeekR1和人工双重校验确保质量。
提示生成过程经过严格的质量控制:首先,GPT-4o根据对象-动作对生成初始提示;然后,DeepSeekR1对提示进行语法和语义校验,过滤掉不符合语言习惯或逻辑矛盾的提示;最后,人工标注者进行最终验证,确保提示既具有长距离语义特性,又保持语言流畅性。这一双重校验机制确保了LDT-Bench中2,839个提示的高质量和多样性。
 上图(e)-LDT-Bench语义距离分布对比
上图(e)-LDT-Bench语义距离分布对比
上图(e)清晰展示了LDT-Bench与其他基准的语义距离分布对比:LDT-Bench的语义距离分布明显右移,峰值出现在0.8-0.9区间,而VBench、EvalCrafter等其他基准多集中在0.3-0.5区间。这一可视化证据有力支持了LDT-Bench专注于长距离语义任务的定位。具体数据对比显示:
复制其中ASD(Average Semantic Distance)表示平均语义距离,LDT-Bench的0.86远高于其他基准,证明其专注于最具挑战性的长距离语义提示。
为全面评估模型表现,研究者开发了ImageryQA评测体系,包含三个维度:
- ElementQA:使用Qwen2.5-VL-72B-Instruct检查元素覆盖(如“交通灯是否出现?是否在跳舞?”)
- AlignQA:采用Q-Align评估视觉质量和美学
- AnomalyQA:利用GPT-4o识别异常内容(如“熊使用遥控器”的合理性)
 上图(c)-ImageryQA评估框架工作流程
上图(c)-ImageryQA评估框架工作流程
上图(c)详细展示了这一自动化评估系统:首先基于文本提示生成针对性问题,然后多模态大语言模型分析生成视频并回答问题,最后系统将回答转化为量化评估结果。例如,对于“交通灯跳舞”这一提示,ElementQA会生成两个问题:“视频中是否出现交通灯?”和“交通灯是否在跳舞?”,然后由Qwen2.5-VL-72B-Instruct分析生成视频并给出是/否答案。
每个维度的评估都有其特定的技术实现:ElementQA侧重于基础语义内容的覆盖情况,使用Qwen2.5-VL-72B-Instruct作为评估模型,该模型在视觉-语言理解任务上表现出色;AlignQA关注视频的视觉质量和美学,采用专门优化的Q-Align模型,该模型经过大量人类偏好数据训练;AnomalyQA则利用GPT-4o的强大推理能力,识别视频中不符合逻辑或物理规律的异常内容。
实验结果与深度分析
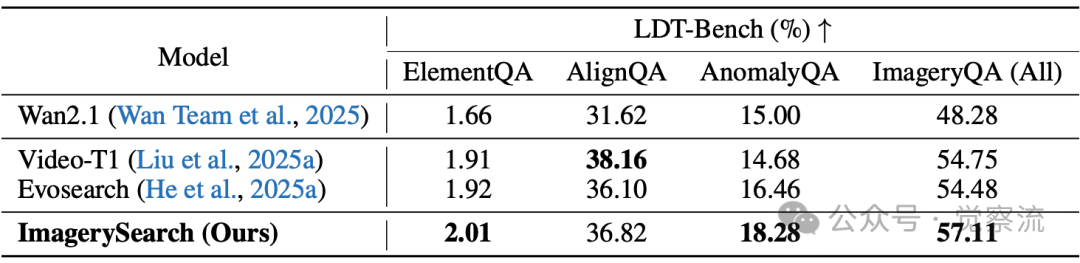
在LDT-Bench上的量化对比显示,ImagerySearch实现了最佳的平均性能表现
如下图所示,ImagerySearch在“熊使用遥控器”提示下,准确生成了前爪操作动作,而基线模型仅呈现静态持握。这一差异直接反映在LDT-Bench的ElementQA指标上——ImagerySearch以2.01%领先基线1.66%,证明其对关键动作元素的捕捉能力。LDT-Bench上的性能对比(上表)提供了ImagerySearch有效性的直接证据。数据显示,ImagerySearch得分为57.11%(ElementQA 2.01% | AlignQA 36.82% | AnomalyQA 18.28%),比基线Wan2.1(48.28%)提升8.83%,也优于VideoT1(54.75%)和EvoSearch(54.48%)。特别值得注意的是,ImagerySearch在元素覆盖(ElementQA)上的提升尤为显著,证明其语义对齐能力明显增强。这一结果与核心机制设计直接相关:SaDSS扩大了搜索空间,使模型能够探索更多可能的语义组合;而AIR则确保了这些组合的语义正确性。

长距离语义提示生成案例
ElementQA的提升最为关键,因为这一指标直接衡量模型是否生成了提示中指定的元素。ImagerySearch在ElementQA上达到2.01%,虽然绝对值不高,但相对于基线1.66%的提升表明,模型在生成长距离语义提示的关键元素方面取得了实质性进步。例如,在“骆驼打包行李”这一提示中,基线模型完全忽略了“打包”动作,而ImagerySearch能够生成骆驼用鼻子和前蹄整理行李的合理动作。
在VBench上的全面评估进一步验证了ImagerySearch的有效性。数据显示,ImagerySearch得分为83.48%(动态程度84.05% | 主体一致性95.90%),优于EvoSearch(82.08%)等方法。尤其在动态程度、主体一致性等维度表现最优,证明其能准确呈现指定主体及其动作。这一结果表明,ImagerySearch不仅在长距离语义提示上表现优异,在常规提示上也具有竞争力。
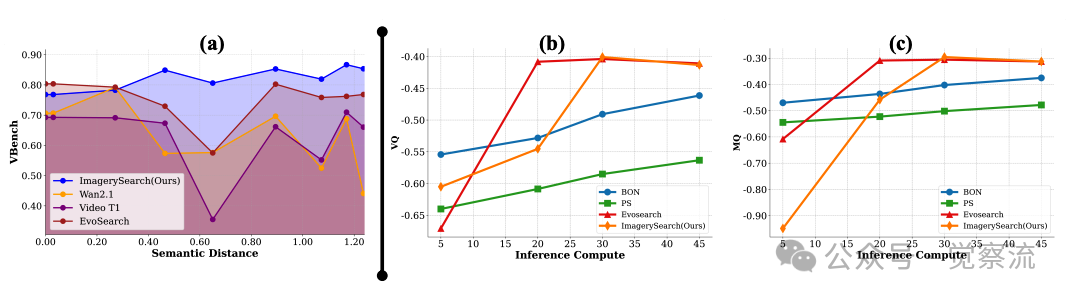
下图(a)展示了语义距离鲁棒性测试结果:随着语义距离增加,ImagerySearch保持稳定性能,而其他方法性能波动剧烈。这一发现具有重要实践意义——在实际应用中,用户无论输入简单还是复杂提示,都能获得一致体验,而其他方法在复杂提示下可能完全失效。例如,当语义距离从0.3增加到0.9时,Wan2.1的性能下降了约25%,而ImagerySearch仅下降了约5%,证明其对长距离语义的鲁棒性。
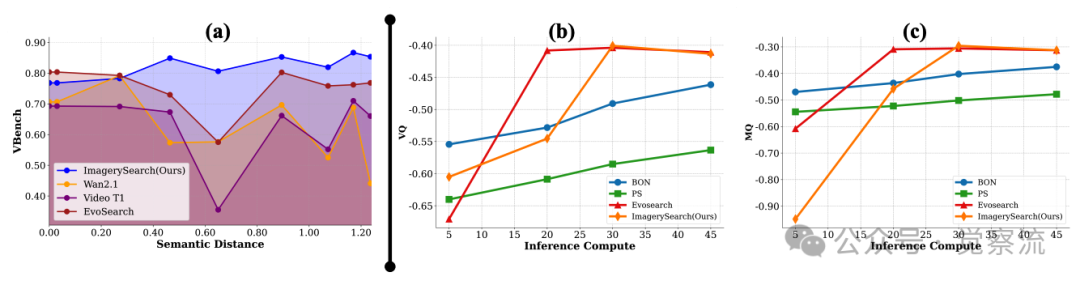
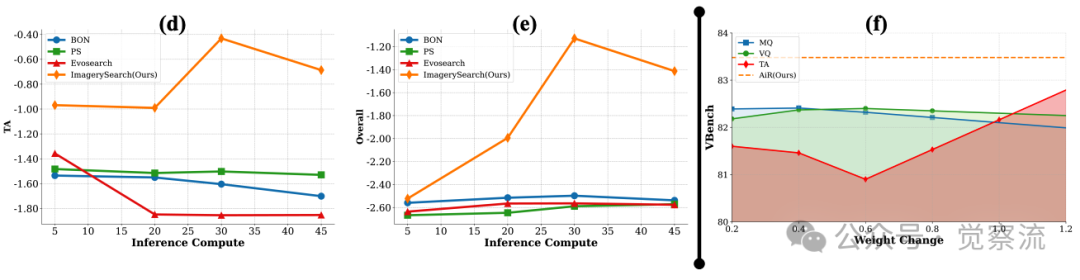
(a)不同模型在语义距离变化下的表现。随着语义距离的增加,论文方法保持了最稳定的性能。(b-e)自适应意象奖励(AIR)始终展现出卓越的性能。ImagerySearch和基线方法在推理计算量增加时的性能变化。从左到右,y轴分别表示运动质量(MQ)、时序对齐(TA)、视觉质量(VQ)和综合评分(VideoAlign(Liu et al., 2025b))的变化。(f)奖励权重的影响
上图共同揭示了ImagerySearch的测试时扩展特性:随着推理时计算量(以函数评估次数NFEs衡量)的增加,ImagerySearch在运动质量(MQ)、时序对齐(TA)和视觉质量(VQ)等指标上均表现出单调的性能提升。而在Wan2.1上,ImagerySearch随着NFEs的增长持续获得改进,而基线方法在约1×10³ NFEs(对应第30个时间步)后达到平台期。
这一“无平台期”特性对实际部署具有重要指导意义——在计算资源充足的场景(如专业视频创作),可以显著增加采样数量以获得更高质量的输出;而在资源受限的场景(如移动端应用),则可以适当减少采样以保持效率,系统会自动根据语义距离调整资源分配策略。
消融实验(下表)提供了机制有效性的直接证据。动态搜索空间(83.48%)明显优于固定大小(81.22%),这一差距(约2.26%)比与基线模型的差距(4.95%)更能说明动态调整机制的价值。具体而言,当处理“骆驼打包行李”这类高语义距离提示时(D̄_sem=0.86),SaDSS会将候选视频数量增加至1.86倍,使模型能够探索更多可能的“打包”动作变体;而AIR则确保筛选出那些骆驼与行李互动关系正确的候选。这种协同机制使模型在关键语义环节获得更充分的探索空间,同时保持对语义对齐的严格要求。
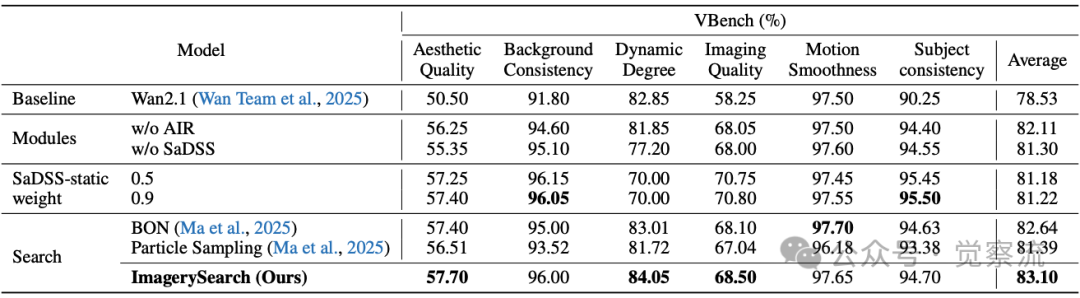
消融实验
此外,上表中的“Search”部分比较了Best-of-N、Particle Sampling等替代搜索策略,数据显示ImagerySearch在这些对比中均表现最佳,表明针对长距离语义任务需要专门设计的搜索策略,而非简单应用现有方法。
下图可视化案例深度剖析揭示了ImagerySearch的实际效果。以“The native bear skillfully uses remote controls.”(本地熊熟练使用遥控器)为例,Wan2.1无法正确呈现“熊”与“遥控器”的互动关系,VideoT1和EvoSearch仍存在语义漂移问题,而ImagerySearch准确生成了熊操作遥控器的连贯动作。
在“The camel packs its belongings with care.”案例中,ImagerySearch的生成过程展现了其对语义结构的精细理解。

长距离语义提示生成案例
上图显示,Wan2.1完全忽略了“打包”动作,仅生成骆驼行走的普通场景;而ImagerySearch准确捕捉到了“打包”这一复杂动作的多个关键环节:在t=45时,系统识别出高语义距离(D̄_sem=0.86),将候选数量增至30个;在t=20时,AIR通过高β权重(强调时序对齐)筛选出那些包含骆驼与行李互动的候选;在t=10时,系统进一步细化动作细节,确保骆驼使用鼻子和前蹄整理行李的动作连贯合理;最终在t=5时,完成细节优化。这一过程完美体现了SaDSS和AIR的协同作用如何逐步构建出符合长距离语义提示的视频内容。
总结:对生成式AI研究的启示
ImagerySearch的价值不仅在于提升8.83%的分数,更在于证明:即使训练数据局限于现实世界,通过模拟人类构建心理意象的认知过程,AI也能在测试时“想象”出训练分布之外的合理场景。这为生成式AI从“现实复现者”迈向“创意协作者”提供了可行路径。
这一成果对生成式AI研究具有重要启示:未来T2V系统应更关注“语义结构感知”的推理机制,使模型能够理解提示中实体之间的复杂关系;测试时搜索策略设计需考虑提示的语义复杂度,为不同难度的提示分配适当的计算资源;动态奖励机制对解决语义漂移问题至关重要,应根据提示的语义难度调整评估标准。
研究者开源了LDT-Bench和ImagerySearch代码,为社区提供标准化评测工具和方法,填补了长距离语义评测空白,推动创意视频生成研究。LDT-Bench不仅提供了2,839个精心筛选的长距离语义提示,还包含完整的评估协议ImageryQA,使研究者能够系统地评估模型在想象力任务上的表现。
未来,可以继续探索更灵活的奖励机制,进一步增强视频生成的创意能力。随着这一方向的持续发展,生成式AI有望突破现有局限,将“熊猫在火星沙尘暴中演奏小提琴”这样的超现实想象转化为高质量的视觉内容,开启创意表达的新路径。ImagerySearch不仅是技术上的突破,更是对AI如何理解和呈现人类想象力的一次重要探索。通过将人类心智意象构建的认知原理转化为可计算的工程实现,ImagerySearch为解决生成式AI中的长尾分布问题提供了新思路。这一工作表明,即使在训练数据有限的情况下,通过智能的测试时推理策略,模型也能超越训练分布的限制,展现出更接近人类的想象力和创造力。随着这一研究方向的深入,我们有望看到AI系统在创意内容生成领域实现质的飞跃,真正成为人类创造力的延伸和增强。


