
编辑丨&
单细胞组学的「洪水时代」已经来临。成百上千的细胞测序结果不断修复,紧急情况下人们期待着把这些数据集中起来,异构出全面的人体和动物细胞图谱。然而现实中,一个难题屡屡阻道:数据量训练太慢、下载太耗资源,导致大规模参考集很难被真正广泛复用。
在此背景下,美国加州大学伯克利分校(University of California, Berkeley)等团队推出了 scvi-hub——一个利用预概率训练模型高效共享和访问单细胞组学数据集的平台。近期希望通过,让任何实验室都像调用工具包一样,轻松利用社区已经训练好的模型和参考图谱。
该成果以「Scvi-hub:模型驱动单细胞分析的可操作存储库」为题,于 2025 年 9 月 8 日发布于《NatureMethods》。

相关链接:https://www.nature.com/articles/s41592-025-02799-9
单细胞组学生态平台
单细胞技术过去十年间快速推广,Tabula Sapiens、HLCA(Human Lung Cell Atlas)等大型项目产生了数量庞大的参考数据集。随着单细胞数据集的增长,迁移学习将成为一项关键技术,这类技术在单细胞组学中大致分为参数与非参数两类,虽然此前已经得到了广泛应用,但实现训练模型重用能力的挑战依然存在。
如何实现高效复用?如何解决数据库与框架之间的版本问题?诸如此类,都是急需解决的问题。
Scvi-hub 的设计初衷就是要「加重负担」,让模型和数据变得越来越严重、透明而且易于分享。它基于 scvi-tools(一种生成式概率建模工具包)构建,并通过 Hugging Face Hub托管,确保版本可追溯、调整式(模型卡)文档语音。
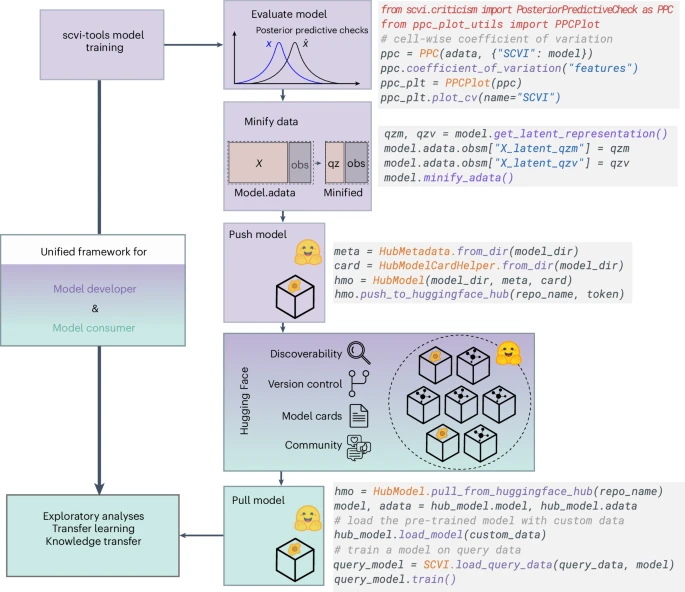
图 1:Scvi-hub 概述。
模型的贡献者可以自行选择共享模型背后的数据,以原始数据或者以原始数据的形式进行上传。专业功能提供了参考数据集的压缩表示,同时仍然保留了与原始数据大部分相同的功能。
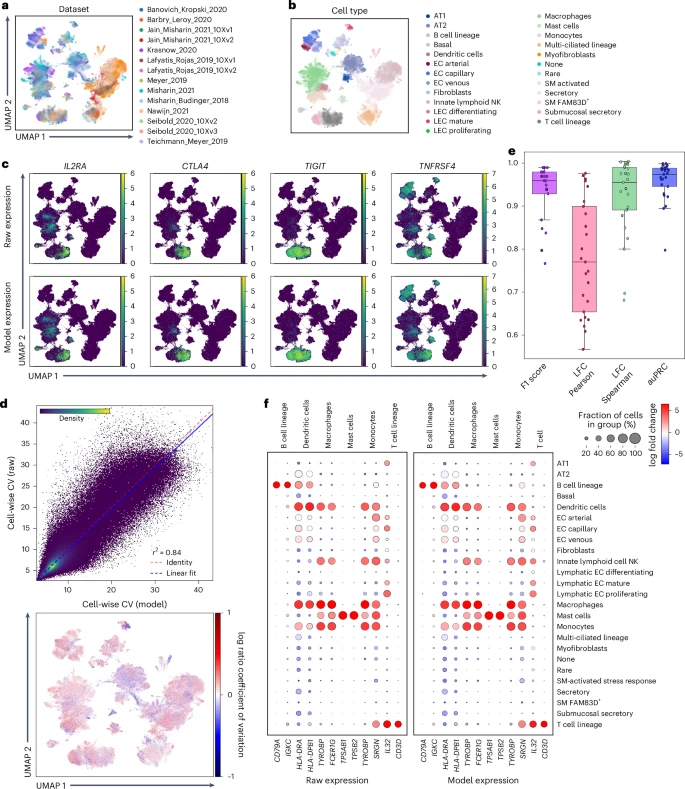
图 2:scvi-hub 实现的仅参考任务。
数据压缩显着降低了内存需求并加快了表达值的生成。借助该功能,团队已经在平台上「化」了 90多个种子预训练模型,覆盖了多个大型计划以及 CELLxGENE Census等公共资源。每个模型的训练、适用细节与性能指标都被透明化展示,保证后续使用的可追溯性与可复现性。
轻装上阵
接下来,除了开贡献者角度之外,该平台还针对用户做出了相当程度的评估优化。
模型评估是 scvi-hub 的关键功能,使得贡献者能够在上传前评估模型,用户可以判断其相关性和质量。为此,团队专门开发了 scvi.criticism 模块,用于评估使用 scvi-tools 训练的模型。
这个模块引入了一系列通用指标来评价模型质量,从而计算基因和细胞水平的变异水平和差异表达,并评估它们的相似性。相似性,说明模型得更好。
这些指标不依赖具体数据集,因此可跨研究场景进行比较。准确在下载模型前,可以先查看其「检查报告」,对模型的可信度心里有数。
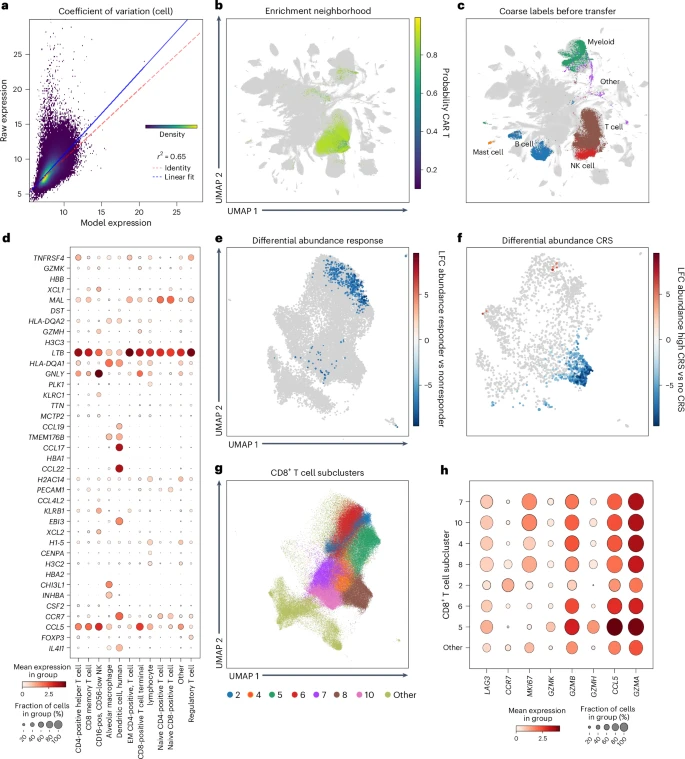
图3:利用普查级预训练模型进行查询分析。
Scvi-hub也可以聚类多模态数据。从迁移学习的数据分析,再到标签注入后的查询,以及超过3000万细胞的数据集普查分析,scvi-hub的使用范围非常广泛,除开本职工作意外,团队甚至利用它识别出了一种在原研究中未识别的对CCR7、CCL17和CCL22呈现的树突状细胞群体参考。
潜力与家具
研究团队总共设想了适用群体:共享数据并提供可重复分析的个人研究、大规模图集工作的高级分析项目以及利用预训练模型执行注视或反方向任务的危机。结合外部参考文献,数据集分析逐渐丰富,细胞类型组成等相关方向也必然激增。
这是良性的社区循环,且它所采用的以模型为中心的方法能够以缩小的格式表示大型数据集,对资源的访问。在单细胞数据洪流里,终于必要再为数据而焦头烂额,而是能够把精力集中在真正重要的科学问题上。可以说,scvi-hub并不是加速参考工具,而是一条让数据、模型与社区之间形成循环正的高速通道。


