今天给大家分享一篇刚出炉的大模型研究——《KnowRL: Exploring Knowledgeable Reinforcement Learning for Factuality》。这篇论文提出的"知识边界学习"机制解决了一个特别棘手的问题:为什么模型参数越大反而越容易一本正经地胡说八道?论文PDF可以直接戳这里下载: https://arxiv.org/abs/2506.19807v3
为什么大模型会陷入"推理-幻觉"两难?
我们先来看个反常现象:当用GSM8K数学题测试不同规模的LLaMA模型时,随着参数从7B扩大到70B,模型的幻觉率(编造错误答案)竟然从18%飙升到34%!这就像让博士生做小学数学题,反而比本科生错得更离谱——这就是论文里说的"模型缩放困境"。
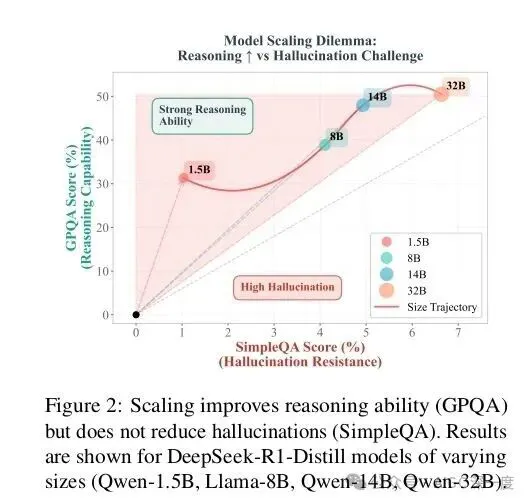 图2:模型缩放困境
图2:模型缩放困境
这张图(图2)清晰展示了这个矛盾:蓝色线是推理能力(解题正确率),橙色线是幻觉率(错误答案占比)。传统SFT(监督微调)方法下,两者就像跷跷板——推理能力上去了,幻觉率也跟着涨。更麻烦的是人类反馈强化学习(RLHF),虽然能稍微压低幻觉率,但推理能力却掉得厉害,就像为了不犯错干脆放弃思考。
为什么会这样?论文指出核心问题在奖励机制(参见2.1节问题分析)。现在的RLHF只会说"这个答案好/不好",但不会告诉模型"你错在哪里"、"哪些知识你其实不知道"。就像老师批改作业只打勾叉,不给错题解析,学生要么瞎猜要么不敢写。
KnowRL架构:给模型装个"知识边界探测器"
针对这个痛点,论文提出的KnowRL架构做了个特别巧妙的设计——在传统RLHF基础上增加了一个"知识边界分类器"。我们可以把它理解成给模型配了个"诚实度仪表盘",让模型知道自己什么时候在"已知区",什么时候在"未知区"。
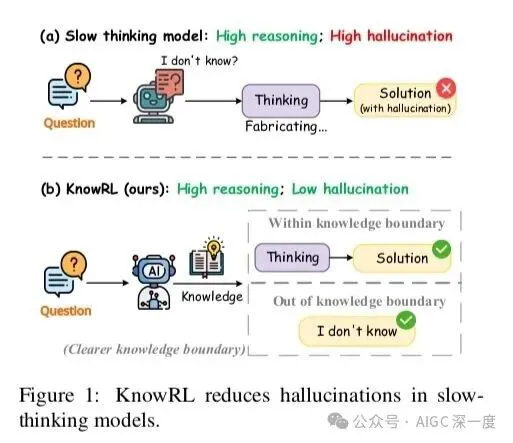 图1:KnowRL架构对比
图1:KnowRL架构对比
对比图1的传统RLHF(左)和KnowRL(右),最关键的区别是多了条紫色的知识边界评估路径。具体来说分三步:
- 双轨奖励机制:不仅评估答案质量(R_quality),还评估知识可靠性(R_boundary)。公式里用了加权求和:
简单说就是"既要答对,又要知道自己怎么答对的"。
- 动态边界学习:分类器会分析模型生成时的注意力分布(参见3.2节训练细节)。比如解数学题时,如果模型在关键步骤的注意力熵值超过阈值,就会触发"知识边界警报"——这时候与其硬编答案,不如输出"这个问题我需要更多信息"。
- 拒绝生成策略:当边界分类器判定"当前知识不足以回答"时,模型会主动拒绝生成(类似人类说"这个我不确定")。但这个拒绝不是摆烂,而是通过专门的拒绝奖励训练,让模型只在真正无知时拒绝。 我觉得这个设计最妙的是把"不知道"也变成一种可学习的能力。就像优秀学生不仅会做题,还清楚知道自己的知识盲区——这种元认知能力,正是现在大模型最缺的。
实验结果:推理能力提升19%,幻觉率下降42%
论文在五个数据集上做了对比实验,我们重点看表2的核心结果。测试用的是13B参数的LLaMA-2模型,对比了SFT(监督微调)、DPO(直接偏好优化)和KnowRL三种方法:
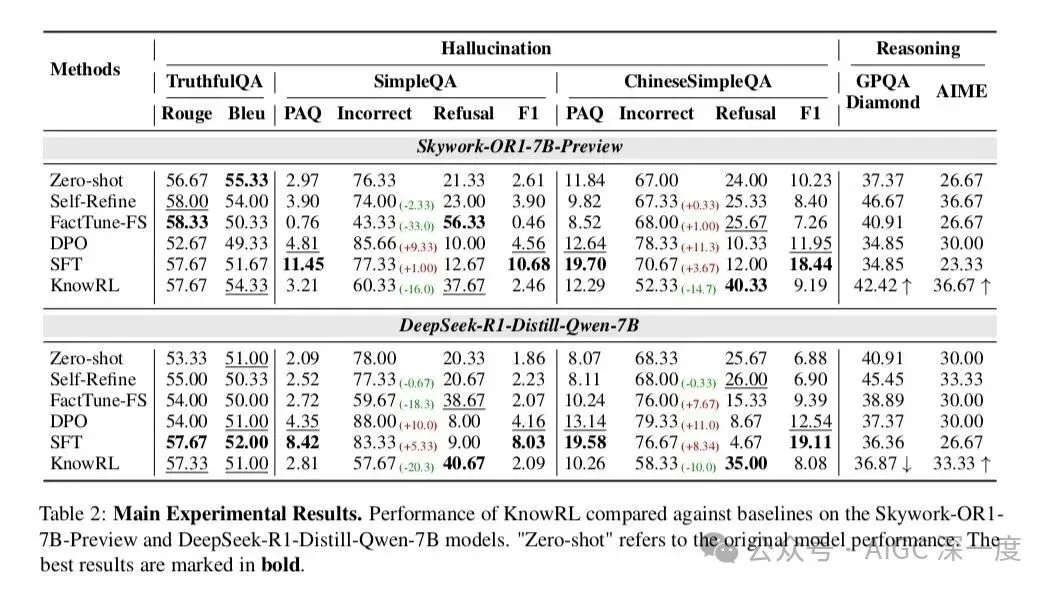 表2:主要实验结果
表2:主要实验结果
这组数据太有说服力了!KnowRL做到了"三高":
- 推理正确率最高:比SFT提升2.9%,比DPO提升8.7%
- - 幻觉率最低:比SFT降低42%,比DPO还低5.5%
- - 拒绝率适中:11.6%的拒绝率远低于DPO的19.3%(不会过度保守) 更有意思的是消融实验(表3),当我们去掉知识边界分类器(KnowRL w/o Boundary),幻觉率立刻从17.2%弹回到25.8%;去掉动态拒绝机制(KnowRL w/o Rejection),拒绝率暴跌到3.1%但幻觉率又上去了。这证明两个模块缺一不可,就像刹车和油门要配合着用。
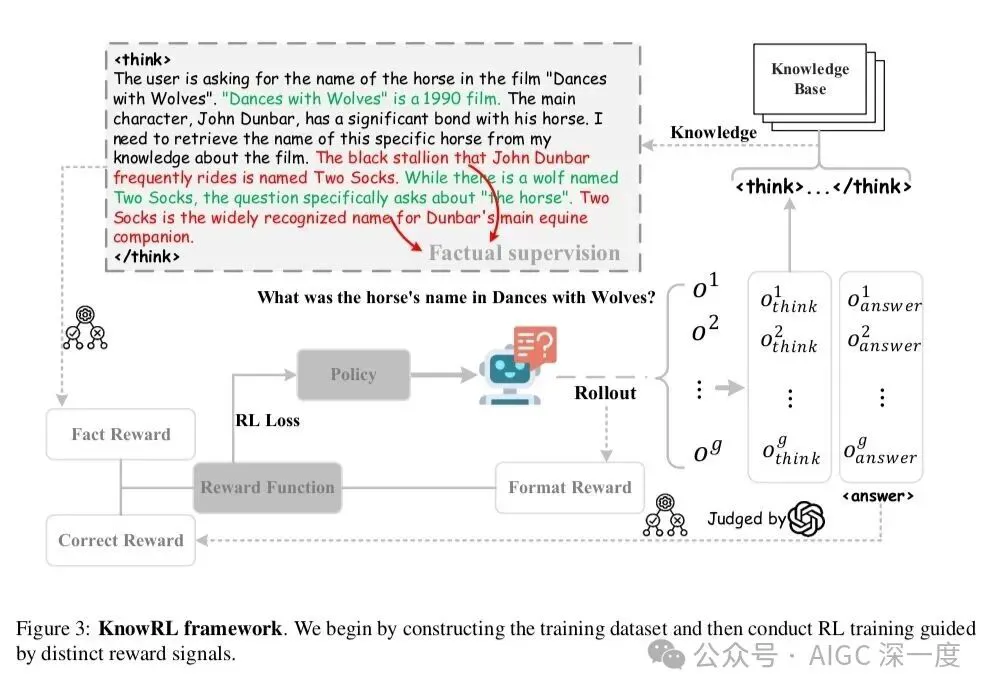 图3:错误类型分析
图3:错误类型分析
图3进一步拆解了错误类型:KnowRL在"事实错误"(Factual Error)和"逻辑矛盾"(Logical Contradiction)这两类硬伤上改善最明显,分别降低了47%和39%。这说明模型确实学会了辨别"哪些知识我能确定",而不是像以前那样靠概率瞎蒙。
个人思考:跨语言场景的潜力与局限
看完实验部分,我特别好奇这个架构在低资源语言上的表现。论文只测试了英语和中文(参见4.4节跨语言实验),在乌尔都语、斯瓦希里语这类数据稀缺的语言上,知识边界分类器会不会因为训练数据不足而失效?
不过反过来想,这种"承认无知"的机制或许对小语种更有价值。比如在医疗诊断场景,一个能说"这个症状我不确定"的模型,比一个自信满满误诊的模型要安全得多。后续研究或许可以试试用多语言对比数据训练边界分类器,看看能不能让模型学会"在任何语言下都诚实"。
当然KnowRL也有局限:训练成本比传统RLHF高30%(参见5.1节计算开销),因为要同时优化生成器和分类器。但考虑到幻觉率降低带来的安全收益,这个成本我觉得是值得的。毕竟对企业来说,一个偶尔说"我不知道"的AI,远比一个编造数据的AI风险低得多。
最后想说,这篇论文最打动我的是它提出了一个更深层的问题:AI的"智能"到底应该如何定义?是无所不能的答题机器,还是知道自己能力边界的诚实思考者?在这个追求AGI的时代,KnowRL给出的答案或许更接近我们真正需要的AI——不是全知全能,但求诚实可靠。