大模型做数独,总体正确率只有15%???

继出场自带十篇完整学术论文的史上首个“AI科学家”之后,Transformer作者Llion Jones又带着他的创业公司Sakana AI来搞事情了。
这次,Sakana AI公布了一个AI模型解决数独问题能力的排行榜。
问题集是该公司推出的全新基准Sudoku-Bench,包含了从简单的4x4到复杂的9x9现代数独问题,旨在考验大模型创造性推理能力。
榜单显示,大模型不仅总体正确率只有15%,在9×9的现代数独中,即使是高性能模型o3 Mini High,正确率也只有2.9%。
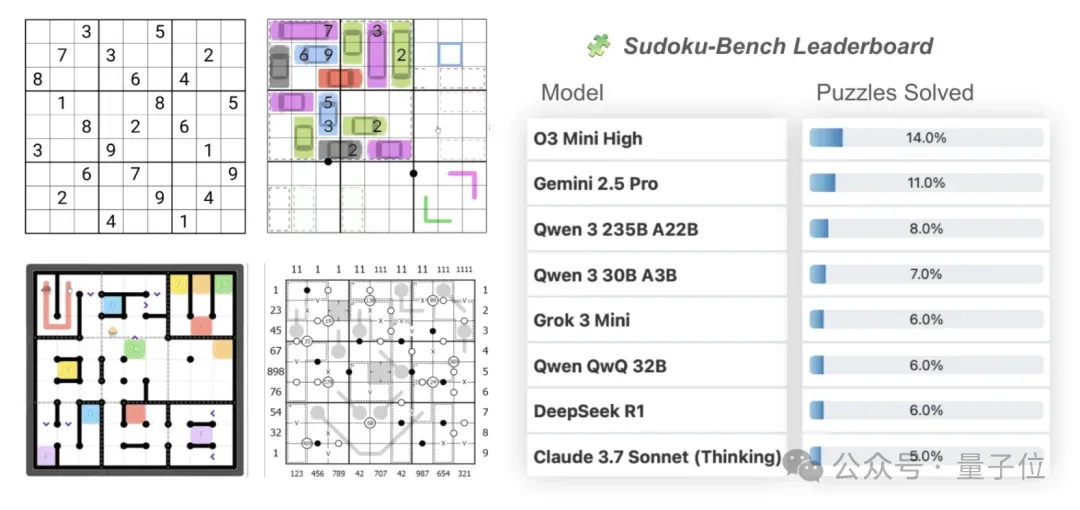
Sudoku-Bench项目在2025NVIDIA GTC开发者大会上进行了展示。
NVIDIA首席执行官黄仁勋对此评价:
像数独这样的谜题将有助于提高AI的推理能力。

Sudoku-Bench全新基准测试
Sudoku-Bench是Sakana AI在今年3月发布的一项由不同难度级别的数独谜题组成的基准测试,用于衡量人工智能的多层次和创造性推理能力。
1、现有问题:大模型的 “记忆依赖症”
目前大多数推理基准测试存在一个缺陷:大模型往往通过记忆标准答案或固定模式来完成任务,而不是真正运用逻辑推理能力。
当遇到与训练数据中 “类似” 的问题时,模型会直接套用记忆中的解决方案,而非通过逻辑推导得出答案。
对于全新规则或未见过的模式,模型往往无法有效应对,因为缺乏可直接匹配的记忆模板。
传统数独游戏对大模型来说可能已经 “太简单”,它们可能只是记住了套路,而不是学会如何创造性地解决新问题。
2、解决方案:Sudoku-Bench用 “变异数独” 考倒大模型
近年来,各种各样具有独特规则的衍生谜题出现。
这些“变异数独”谜题需要多步骤和创造性的推理技巧,但只有一个正确答案,特点是无法通过记忆解决,必须通过多步逻辑推理找到 “突破口”。
这些特点使得“变异数独”成为测试AI推理能力的理想选择。
以下就是一个“变异数独”示例,你不仅需要遵循原始规则,而且沿着彩色线条排列的数字还需要遵循额外的规则。
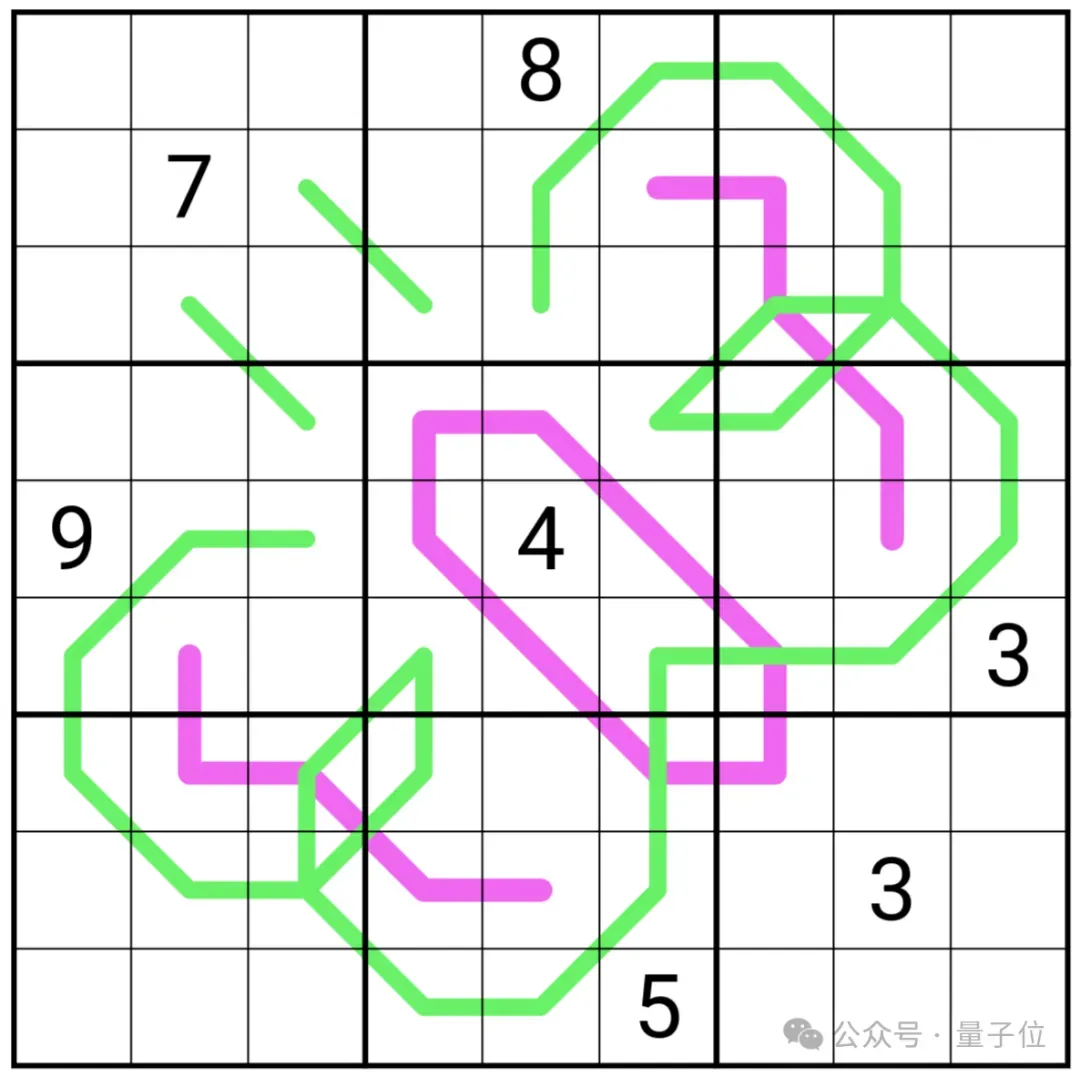
Sudoku-Bench基准包括传统和现代数独(变异数独)问题,难度分级,从当前模型可以解决的简单问题到甚至最先进的推理模型也无法处理的极其困难的问题。
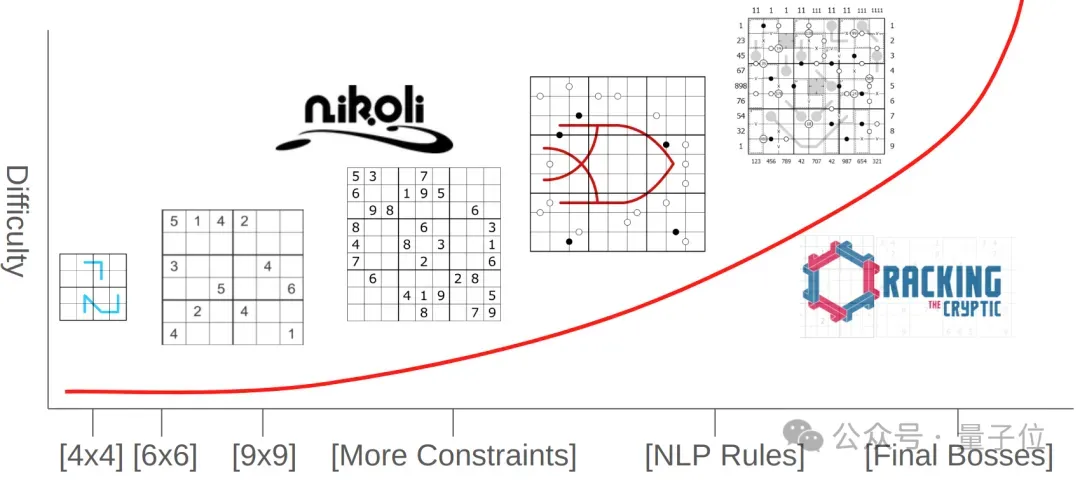
Sudoku-Bench还包含了由Nikoli(日本著名的数独公司,数独正是其名称的由来)提供的100道手工数独题。

3、大模型的 “惨败”:基线实验结果
在今年3月该基准发布后,研究人员测试了多个AI模型,包括Gemini 2.5 Pro、GPT-4.1、Claude 3.7等在内的最先进大模型。
为了给模型一个公平的机会,团队为模型提供了部分完成的谜题,并评估它们完成谜题的能力。
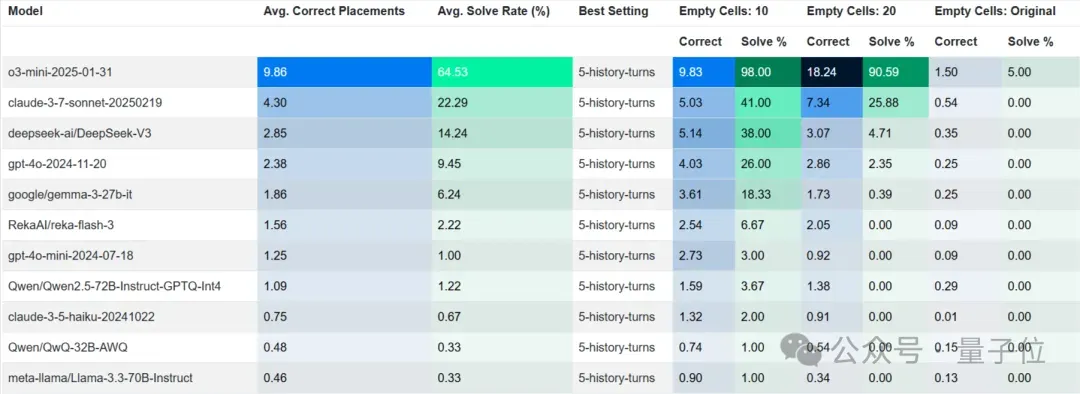
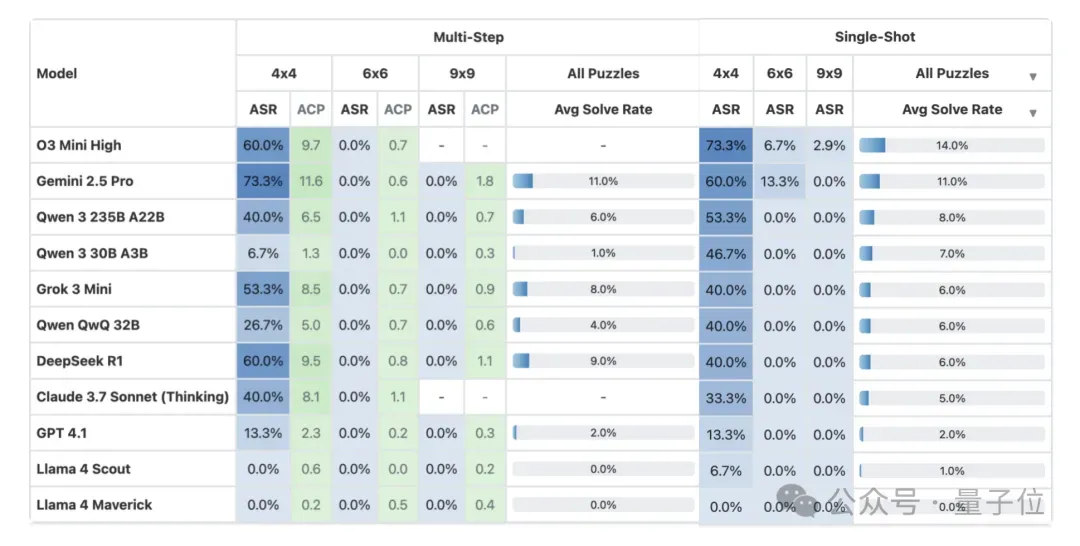
结果显示,一些模型在这种辅助下表现得相当不错,但关键结果在于最后两列。
即使是最先进的模型,平均连一个正确的数字都放不下,而OpenAI最新的推理模型ChatGPT o3是唯一能够解决基准测试中所有谜题的模型。
最新的排行榜显示:
- 无工具辅助时,所有模型在100个谜题中的总体正确率低于15%;
- 小网格(4x4)表现稍好(40%-73% 正确率),但9x9网格几乎全败,正确率接近0%,即使是高性能模型“o3 Mini High”的正确率也只有2.9%。
- 模型常犯错误包括:错误解答、放弃解题、误判规则矛盾,尤其是面对需要 “突破口” 的谜题时,只会盲目猜测,无法像人类一样通过逻辑链缩小搜索范围。
测试团队详细列出了模型在每个谜题上的表现,感兴趣的朋友可戳文末链接查看~
关于Sakana AI
Sakana AI由前谷歌研究人员Llion Jones(Transformer作者之一)和David Ha于2023 年7月在东京成立,主要对生成文本和图像的AI基本模型进行研究。
此前,该公司开源发布了AI科学家和AI审稿人,前者一出场就独自完成了十篇完整的学术论文,包括但不限于扩散模型方向、Transformer与强化学习等,引起了不小的轰动。
后者能对AI写的论文进行评审,提供改进意见,主打“以我之矛攻我之盾”。

该公司还发布了一种名为“连续思维机器 (CTM)”的新型AI模型,通过像人类一样“逐步”思考并学习世界的内部模型,超越了简单的模式识别,并获得了逐步解决迷宫等复杂问题的能力。
Sakana AI还与Cracking The Cryptic(YouTube 上最大的谜题评论频道之一)合作,Cracking The Cryptic每天都会演示一些世界上最好的数独谜题的逻辑解决方案。

Sakana AI获得了这些视频的文字记录以及答题过程中采取的行动数据。这些数据可以作为训练AI推理模型的理想数据,并与Sudoku-Bench一起发布。
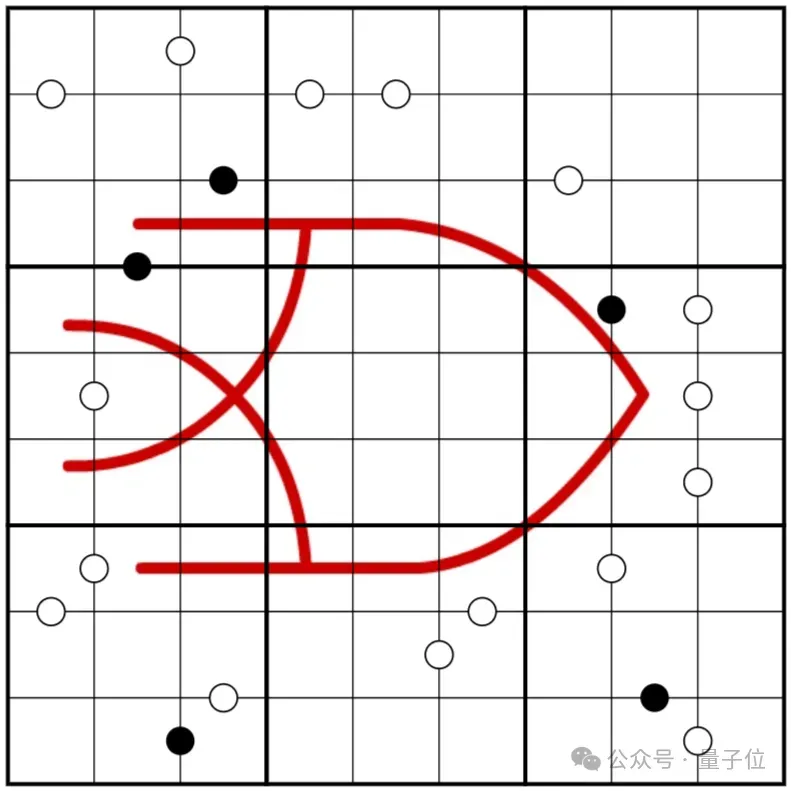
著名的数独出题人Marty Sears还为Sakana AI定制了一款名为“奇偶鱼”的数独游戏:沿着Sakana AI红色标志线相邻的任何数字都必须包含一个偶数和一个奇数。
感兴趣的朋友可以尝试一下(解答过程已附在文末)~
技术报告:https://arxiv.org/abs/2505.16135
排行榜:https://pub.sakana.ai/sudoku/
Github:https://github.com/SakanaAI/Sudoku-Bench
奇偶鱼题目:https://sudokupad.app/wsj7iunsg6解答过程:https://www.youtube.com/watch?v=JdHSSNKuIzU


