Airbnb最近完成了第一次由 LLM 驱动的大规模代码迁移,将 3500 个测试文件从 Enzyme 更新为 React测试库(RTL,React Testing Library)。最初我们估计这需要 1 年半的时间来手工完成,但通过使用前沿模型和强大的自动化组合,我们在 6 周内完成了整个迁移。
本文将重点介绍从 Enzyme 迁移到 RTL 所面临的独特挑战,如何通过 LLM 解决这些挑战,以及如何构建迁移工具来执行 LLM 驱动的大规模迁移。

一、背景
2020 年,Airbnb 采用 React 测试库(RTL)进行所有新的 React 组件测试开发,标志着我们迈出了远离 Enzyme 的第一步。尽管自 2015 年以来,Enzyme 一直为我们提供良好的服务,但它是为 React 的早期版本设计的,并且该框架对组件内部的深度访问不再符合现代 React 测试实践。
但由于框架之间存在根本性差异,我们无法轻易替换(阅读 Introducing the React Testing Library[2] 获取更多关于差异的信息)。而且分析发现如果仅仅删除 Enzyme 文件,会在代码覆盖率中造成显著缺口。为了完成迁移,需要一种自动化方法来将测试文件从 Enzyme 重构为 RTL,同时保留原始测试意图以及代码覆盖率。
二、如何做到
2023 年中,Airbnb 的一个黑客马拉松团队展示了大语言模型可以在短短几天内成功将数百个 Enzyme 文件转换为 RTL。
在这个很有希望的结果基础上,我们在 2024 年为 LLM 驱动的迁移开发了一个可扩展流水线。我们将迁移分解为离散的、可以并行化每个文件步骤和配置的重试循环,并通过额外的上下文显著扩展了提示词。最后,对复杂文件的长尾执行了宽度优先的提示词调优。
1. 文件验证和重构步骤
首先将迁移分解为一系列自动验证和重构步骤。可以把它想象成一个生产流水线:每个文件都经过验证阶段,当检查失败时,就引入 LLM 来修复。
我们将此流程建模为状态机,只有在前一个状态通过验证后才将文件移动到下一个状态:
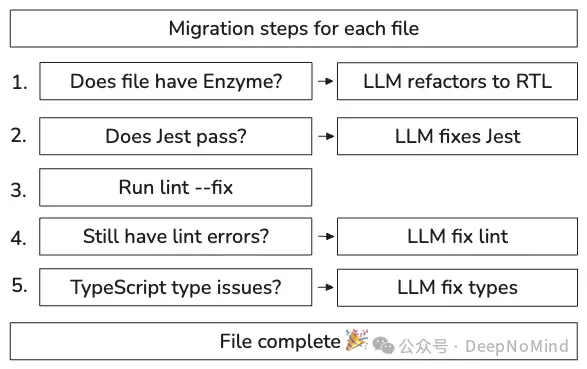
这种分步骤的方法为自动化流水线提供了坚实基础,使我们能够跟踪进度,优化特定步骤的故障率,并在需要时重新运行文件或步骤。基于步骤的方法还使同时在数百个文件上运行迁移变得简单,这对于快速迁移简单文件和在迁移过程中逐渐消除长尾文件至关重要。
2. 重试循环和动态提示
在迁移早期,我们尝试了不同的提示工程策略来提高每个文件迁移的成功率。然而,在分步骤方法的基础上,我们发现改善结果的最有效途径是简单的蛮力:多次重试步骤,直到通过或达到极限。我们更新了步骤,为每次重试使用动态提示,将验证错误和文件的最新版本提供给 LLM,并构建了循环执行器,可以配置每个步骤的尝试次数。
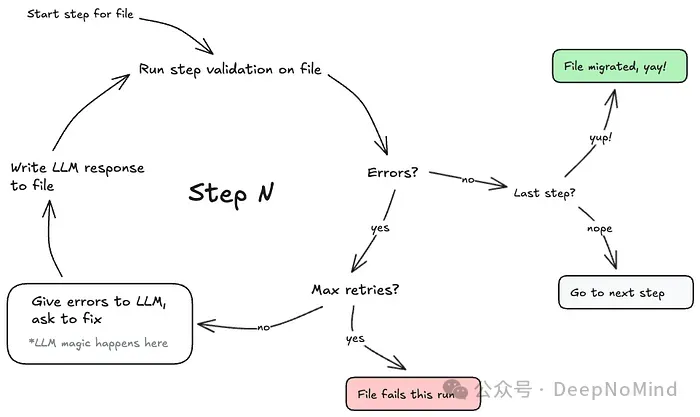
通过简单的重试循环,我们发现可以成功迁移大量简单到中等复杂度的测试文件,其中有些需要重试几次才能成功完成,大多数可以在 10 次尝试后成功完成。
3. 扩展上下文
对于具有一定复杂度的测试文件,只需增加重试次数就可以了。然而,要处理具有复杂的测试状态设置或过多间接文件,我们发现最好的方法是将尽可能多的相关上下文放入提示词中。
在迁移结束时,我们的提示已经扩展到 40,000 到 100,000 个 token,涉及多达 50 个相关文件,大量手工编写的示例,以及来自同一项目中现有的、编写良好的、通过测试的文件示例。
每个提示词包括:
- 被测组件的源代码
- 正在迁移的测试文件
- 验证失败的步骤
- 来自同一目录的相关测试(维护团队特定模式)
- 一般性的迁移指南和通用解决方案
下面是实际应用中的样子(为了可读性做了部分修改):
复制// Code example shows a trimmed down version of a prompt
// including the raw source code from related files, imports,
// examples, the component source itself, and the test file to migrate.
const prompt = [
'Convert this Enzyme test to React Testing Library:',
`SIBLING TESTS:\n${siblingTestFilesSourceCode}`,
`RTL EXAMPLES:\n${reactTestingLibraryExamples}`,
`IMPORTS:\n${nearestImportSourceCode}`,
`COMPONENT SOURCE:\n${componentFileSourceCode}`,
`TEST TO MIGRATE:\n${testFileSourceCode}`,
].join('\n\n');这种丰富的上下文方法被证明对更复杂的文件非常有效,LLM 可以更好的理解团队的特定模式、通用测试方法和代码库的整体体系架构。
应该注意到,尽管我们在这个步骤中做了一些提示工程,但主要成功驱动因素是选择正确的相关文件(查找附近的文件,来自同一个项目的好的示例文件,过滤与组件相关的文件的依赖项,等等),而不是依赖更完美的提示工程。
通过重试、构建丰富的上下文以及测试迁移移脚本之后,当我们进行第一次批量运行时,在短短 4 个小时内就成功迁移了 75% 的目标文件。
4. 从 75% 到 97%:系统化改进
75% 的成功率确实令人兴奋,但仍然有近 900 个文件没有达到验证标准。为了解决这个长尾问题,我们需要一种系统化方法来了解剩余文件卡在哪里,并改进迁移脚本来解决这些问题。我们希望首先扩展广度,积极减少剩余文件,而不要被最困难的迁移案例所困。
为此,我们在迁移工具中构建了两个特性。
- 首先,我们构建了一个简单的系统,通过在文件中添加自动生成的注释来记录每个迁移步骤的状态,从而使我们能够看到脚本所面临的常见问题。下面是代码注释的样子:
// MIGRATION STATUS: {"enyzme":"done","jest":{"passed":8,"failed":2,"total":10,"skipped":0,"successRate":80},"eslint":"pending","tsc":"pending",}- 其次,我们添加了轻松重新运行单个文件或路径模式的能力,根据它们所携带的特定步骤进行过滤:
$ llm-bulk-migration --step=fix-jest --match=project-abc/**
基于这两个功能,我们可以快速运行反馈循环来改进提示和工具:
- 运行所有剩余的失败文件,以找到 LLM 卡住的常见问题
- 选择文件样本(5 到 10 个)来说明某个常见问题
- 更新提示词和脚本来解决这个问题
- 重新运行失败文件样本以验证修复
- 再次对所有剩余的文件执行上述操作
在运行这个“采样、调整、扫描”循环 4 天后,我们已经将完成的文件从所有文件的 75% 推到了 97%,只剩下了不到 100 个文件。到目前为止,我们已经对许多长尾文件进行了 50 到 100 次重试,似乎已经达到了通过自动化修复的极限。我们没有投入更多调优,而是选择手动修复剩余文件,从基线(失败)开始重构,从而减少修复这些文件的工作量。
三、结果及影响
有了验证和重构流水线、重试循环和扩展上下文,我们能够在4小时内自动迁移 75% 的目标文件。
经过四天的“采样、调优和扫描”策略实现的提示词和脚本优化,我们完成了 3500 个原始 Enzyme 文件的97%。
对于剩余的 3% 没有通过自动化完成的文件,脚本为手动干预提供了一个很好的基线,帮助我们在一周之内完成了剩余文件的迁移。
最重要的是,我们能够在保持原始测试意图和代码覆盖率的同时替换 Enzyme。即使在迁移的长尾上有很高的重试次数,总成本(包括 LLM API 的使用和 6 周的工程时间)被证明比最初手动迁移的估算要高效得多。
四、下一步
这种迁移突出了 LLM 对大规模代码转换的能力。我们计划扩展这种方法,开发更复杂的迁移工具,并探索 LLM 驱动的自动化的新应用,以提高开发人员的生产力。
参考资料
- [1] Accelerating Large-Scale Test Migration with LLMs: https://medium.com/airbnb-engineering/accelerating-large-scale-test-migration-with-llms-9565c208023b
- [2] Introducing the React Testing Library: https://kentcdodds.com/blog/introducing-the-react-testing-library


