相信扩散模型(DMs)大家一定都不陌生了,目前已经成为文本生成图像的核心方法,凭借强大的图像生成能力,正重塑艺术创作、广告设计、社交媒体内容生产格局。现在,用一段文字生成个性化头像都不算啥新鲜事儿了。
不过仍然会有这样一个问题,目前我们看到的基于人物的文生图大多还是生成一个人的,对于多人同时生成的目前还没有很好的样例。然而这些场景又会经常出现在我们的生活中,举个例子:
- 朋友缺席聚会,能不能“补全”一张全员到齐的合影?
- 广告里,能不能自由搭配多位虚拟角色,讲个精彩的多人物故事?
目前对于个性化多人图像生成仍然面临很大的技术挑战。比如最大的难点就是身份特征泄露,明明是两个人,结果生成的面容却“融合”在一起,让人傻傻分不清。而且,用户还希望能精准指定每个人的位置和动作,让构图更自然、互动更有趣。一旦位置出错,可能生成的图像就惨不忍睹了!

今天给大家介绍的由字节跳动和密歇根州立大学提出的个性化多身份图像生成方法ID-Patch,对于身份泄露、ID一致保持,模型推理速度等都给我们带来了一些惊喜。下面展示的结果为该方法与最先进的多身份生成方法的比较:
 从左到右:条件输入,OMG(InstantID)、InstantFamily 和 ID-Patch。OMG 未能保留中间人的发型,并为右边女性的手部创建了伪影。InstantFamily 存在 ID 泄露问题,导致中间人 ID 不正确。ID-Patch保留了每个人的详细身份信息。此外,ID-Patch 比 OMG 快 7 倍,并且计算开销比 InstantFamily 更少。
从左到右:条件输入,OMG(InstantID)、InstantFamily 和 ID-Patch。OMG 未能保留中间人的发型,并为右边女性的手部创建了伪影。InstantFamily 存在 ID 泄露问题,导致中间人 ID 不正确。ID-Patch保留了每个人的详细身份信息。此外,ID-Patch 比 OMG 快 7 倍,并且计算开销比 InstantFamily 更少。
效果展示
 使用 ID-Patch 生成任意姿势图像
使用 ID-Patch 生成任意姿势图像 即插即用:Canny Edge
即插即用:Canny Edge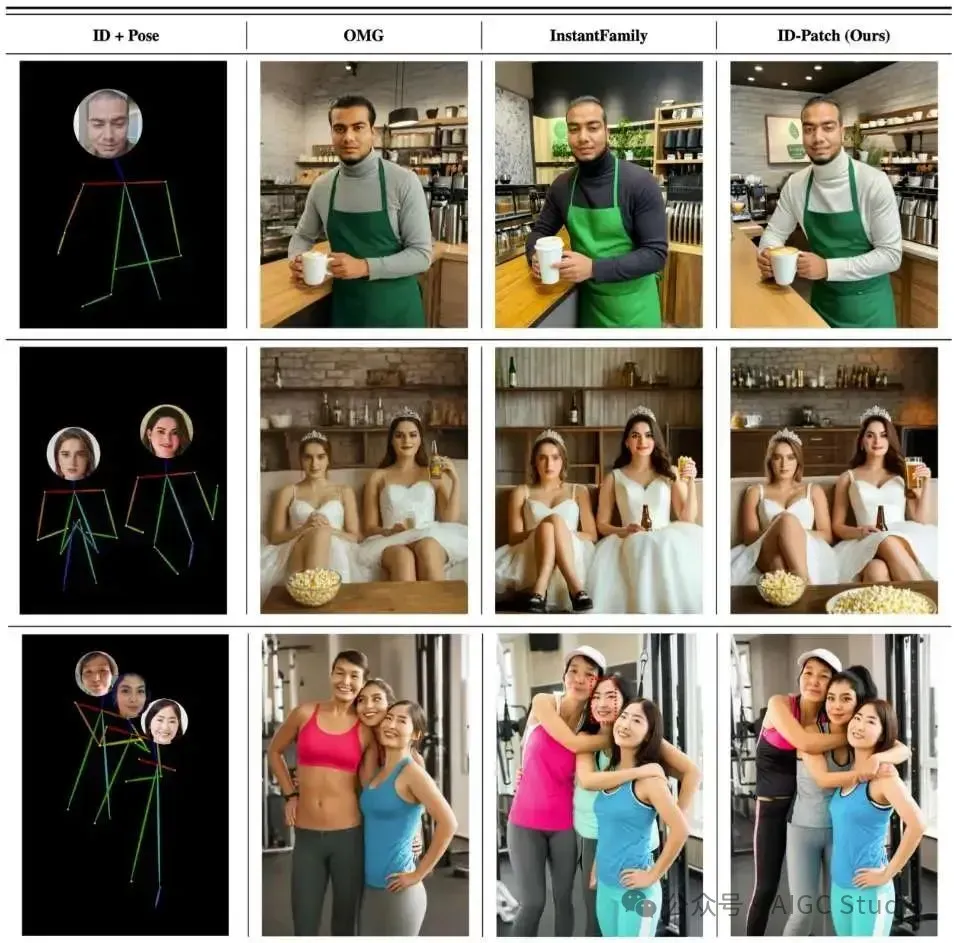
姿势条件生成
相关链接
- 论文:https://arxiv.org/abs/2411.13632
- 主页:https://byteaigc.github.io/ID-Patch/
- 模型:https://huggingface.co/ByteDance/ID-Patch
- 试用:https://huggingface.co/spaces/ByteDance/ID-Patch-SDXL
论文介绍

综合个性化的小组照片并指定每个身份的位置的能力具有巨大的创造潜力。尽管这种图像在视觉上具有吸引力,但它对现有技术提出了重大挑战。一个持续的问题是身份(ID)泄漏,其中注入的面部特征彼此干扰,导致较低的面部相似,定位不正确和视觉伪像。现有方法受到限制,例如依赖分割模型,增加运行时或ID泄漏的可能性很高。
为了应对这些挑战,论文提出了ID-PATCH,这是一种新颖的方法,可以在身份和2D位置之间提供牢固的关联。该方法从相同的面部特征生成一个ID补丁和ID嵌入:ID补丁位于条件图像上以进行精确的空间控制,而ID嵌入与文本嵌入式集成以确保高相似。实验结果表明,ID-PATCH超过了跨指标的基线方法,例如面部ID相似,ID位置关联的准确性和生成效率。
方法概述
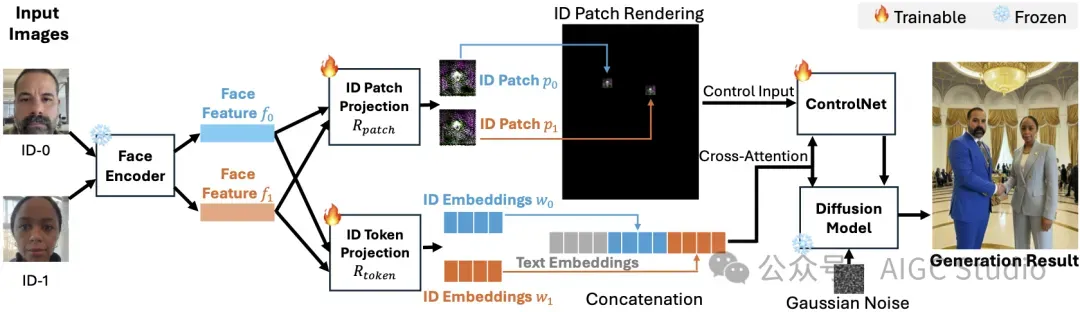 ID-Patch管道。给定文本提示(例如,两个人握手),n个脸部图像和位置,我们与n ID。我们为每个ID提取面部功能,然后将其投影到ID补丁和ID嵌入中。 ID补丁在黑色上渲染 帆布(或添加在姿势图像的顶部)根据面部位置并发送到控制网中以控制生成的位置 面孔。 ID嵌入插件被附加到文本嵌入中,以通过扩散模型提供详细的面部信息,并通过 跨注意。
ID-Patch管道。给定文本提示(例如,两个人握手),n个脸部图像和位置,我们与n ID。我们为每个ID提取面部功能,然后将其投影到ID补丁和ID嵌入中。 ID补丁在黑色上渲染 帆布(或添加在姿势图像的顶部)根据面部位置并发送到控制网中以控制生成的位置 面孔。 ID嵌入插件被附加到文本嵌入中,以通过扩散模型提供详细的面部信息,并通过 跨注意。

ID嵌入的有效性。没有ID嵌入,可以区分两个人,但相似之处很低。合并ID嵌入可显着改善 脸相似

ID-PATCH结合姿势条件。提供 (a)中的用户ID映像,我们的方法只能生成结果 鼻尖位置的规格如(b)所示。合并 带有姿势图像的ID补丁(C)增强了对 产生的结果如(d)所示,没有产生任何计算开销。

两阶段训练以提高定位鲁棒性。 给定(a)中的姿势和ID条件,单级训练不能 完全防止面部定位问题不正确。例如,在 (b)这个人被错误地放在中央底部的位置, 产生不可分割的结果。 (c)引入了两个阶段训练以解决此问题。从第一行可以看出 图,与这些方法相比 来自单阶段训练。我们的实验结果证明了这一点 解决ID泄漏问题至关重要。
实验结果
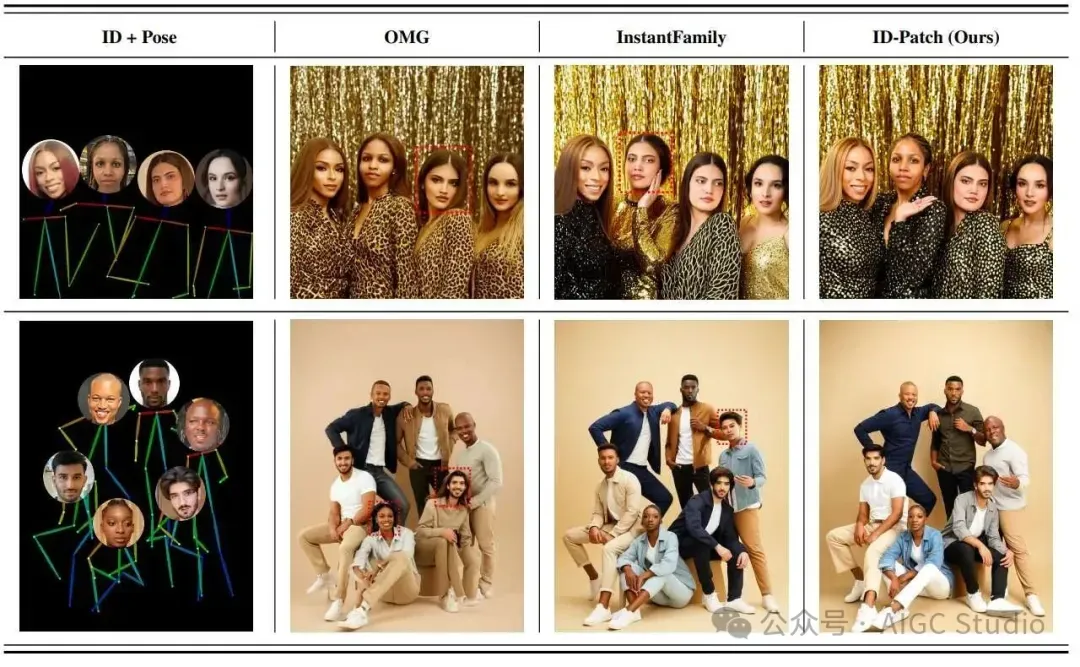 与姿势条件生成基线的 相似。在第1行中,OMG无法保留第三个女人的脸部形状(从左到右),因为它的第一阶段导致冲突 带有此ID的脸部形状。由于第三名女性的ID泄漏,瞬间家庭会产生第二个人。在第2行, OMG不会为红色盒子中的两个人生成正确的发型和准确的面部特征,而瞬时生成 红色框中的错误ID。与姿势条件生成基线的比较,红色虚线盒突出显示了具有低身份的实例 相似。在第1行中,OMG无法保留第三个女人的脸部形状(从左到右),因为它的第一阶段导致冲突 带有此ID的脸部形状。由于第三名女性的ID泄漏,瞬间家庭会产生第二个人。在第2行, OMG不会为红色盒子中的两个人生成正确的发型和准确的面部特征,而瞬时生成 红色框中的错误ID。
与姿势条件生成基线的 相似。在第1行中,OMG无法保留第三个女人的脸部形状(从左到右),因为它的第一阶段导致冲突 带有此ID的脸部形状。由于第三名女性的ID泄漏,瞬间家庭会产生第二个人。在第2行, OMG不会为红色盒子中的两个人生成正确的发型和准确的面部特征,而瞬时生成 红色框中的错误ID。与姿势条件生成基线的比较,红色虚线盒突出显示了具有低身份的实例 相似。在第1行中,OMG无法保留第三个女人的脸部形状(从左到右),因为它的第一阶段导致冲突 带有此ID的脸部形状。由于第三名女性的ID泄漏,瞬间家庭会产生第二个人。在第2行, OMG不会为红色盒子中的两个人生成正确的发型和准确的面部特征,而瞬时生成 红色框中的错误ID。
更多结果



结论
ID-PATCH显着增强了身份相似之处和位置生成。通过将每个身份功能嵌入独特的补丁并利用ControlNet准确地放置在指定的空间位置,有效的减少了ID泄漏。该方法与其他条件信号(例如姿势)无缝集成 控制。
ID-PATCH这项工作为未来铺平了道路 多ID图像生成中的探索。潜在的未来研究方向包括利用多个图像 来自不同角度的同一个人的进一步增强身份相似和同时控制 使用补丁技术的位置和面部表情。


