在 3D 重建领域,无论是 NeRF 还是最新的 3D Gaussian Splatting(3DGS),在生成逼真新视角时仍面临一个核心难题:视角一旦偏离训练相机位置,图像就容易出现模糊、鬼影、几何错乱等伪影,严重影响实际应用。
为了解决这个问题,来自英伟达的研究团队联合提出了一种创新方案 —— Difix3D+,通过单步扩散模型对 3D 渲染结果进行 “图像修复”,显著提升新视角图像的质量和一致性。该工作已被 CVPR 2025 接收,并入选 Best Paper Award 候选。

- 🌐项目主页:https://research.nvidia.com/labs/toronto-ai/difix3d
- 📄论文地址:https://arxiv.org/abs/2503.01774
- 💻代码地址:https://github.com/nv-tlabs/Difix3D
 背景:3D 重建的 “致命短板”
背景:3D 重建的 “致命短板”
近年来,NeRF(神经辐射场)和 3D Gaussian Splatting(3DGS)等技术在三维重建与新视角合成中取得突破。然而,在训练相机视角之外,这些方法往往会出现模糊、鬼影、几何错乱等伪影,尤其在视角跨度较大、数据稀疏、光照变化或相机标定不准确的情况下尤为严重。这些伪影极大限制了其在自动驾驶、机器人、AR/VR 等真实场景中的应用。
这主要是因为传统方法过度依赖局部一致性和 per-scene 优化流程,缺乏跨场景泛化能力,且无法有效填补观测稀疏区域的 “空洞”。
关键洞察:2D 扩散模型为何能 “修好” 3D?
Difix3D+ 提出了一个突破性的视角:将预训练 2D 扩散模型的视觉先验引入 3D 渲染流程,将其作为 “图像修复器”,精准去除神经渲染伪影。
这一设计基于一个关键观察:神经渲染伪影的分布,与扩散模型训练过程中的噪声图像分布惊人地相似。

为验证这一点,研究者将渲染图输入扩散模型进行单步 “去噪”,并系统性测试不同噪声强度(t)的效果 ——
- 高噪声(t=600):虽然伪影被去除,但内容也严重变形
- 低噪声(t=10):图像结构完整,但伪影几乎未去除
- 中等噪声(t=200):在保留语义结构的同时,有效消除了渲染伪影
这一发现使得单步扩散模型成为 “修复” NeRF/3DGS 渲染图的理想选择,不仅效率高,而且具备泛化能力。
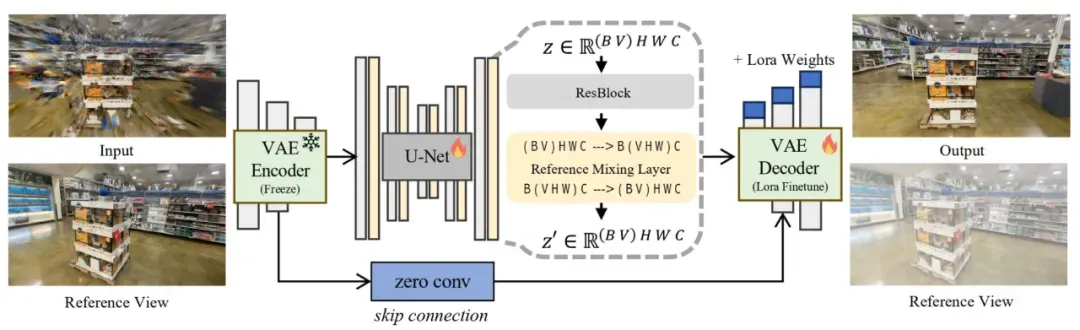
Difix 具备以下核心优势:
1. 单步扩散:发现渲染伪影的分布在 t=200 处最接近扩散模型训练数据,DIFIX 可一次去除伪影并保留语义结构。
2. 无需大量训练:仅需在消费级 GPU 上训练几个小时,即可适配 NeRF/3DGS 的渲染伪影;
3. 支持多种 3D 表征:同一个模型可同时修复 NeRF(隐式)与 3DGS(显式)渲染;
4. 近实时推理:在 NVIDIA A100 上,仅需 76ms 即可完成图像修复,比传统多步扩散快 10 倍以上。
5. 可进可退:修复后的图像还能反向蒸馏回 3D 模型,提升整体建模精度和一致性。
解决方案:DIFIX3D+ = 扩散模型 + 蒸馏增强 + 实时修复
DIFIX3D+ 以一个经过少量微调的单步扩散模型(DIFIX)为核心模块,结合渐进式优化策略,构建出一个无需修改原始 3D 重建结构即可增强视觉质量的插件化系统。
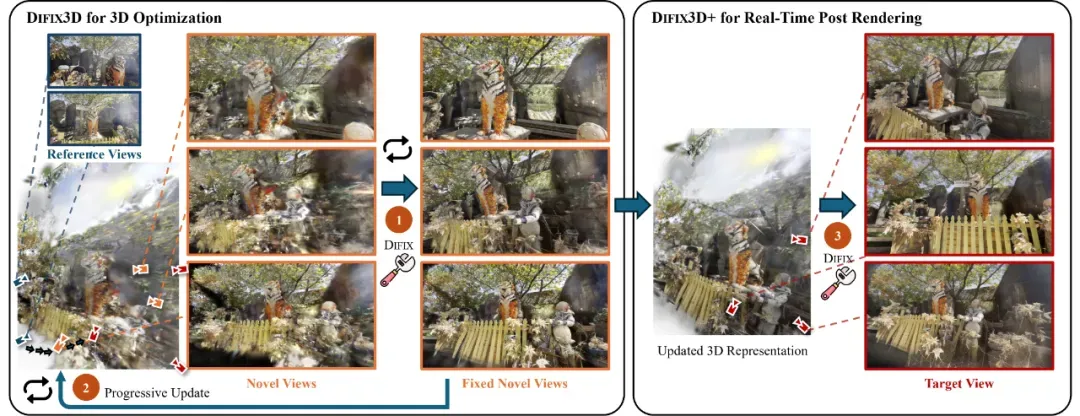
核心三步流程:
Step 1:DIFIX 修复中间视角图像。从训练视角向目标视角进行插值采样,生成中间视角图,并用 DIFIX 去除伪影。
Step 2:蒸馏至 3D 表示。将修复后的图像 “反向蒸馏” 回 3D 表示中,逐步提升建模质量与区域覆盖度。
Step 3:推理时再修复。最终渲染出的图像,再次通过 DIFIX 后处理,消除残留细节错误,仅需 76ms,支持实时渲染。
实验结果一览:效果、指标全面领先
支持 NeRF、3DGS 多种 3D 表征。

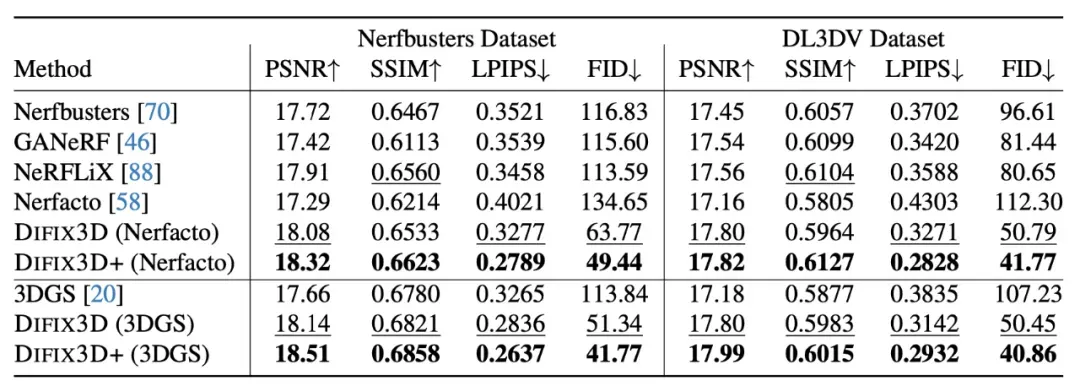
FID 降幅超过 60%~70%,LPIPS 接近 SOTA 一半,大幅领先其他方法。
此外,在自动驾驶场景中(横向 6 米偏移或仰角 30°),DIFIX3D+ 仍能维持视角一致性与图像清晰度,极具工程落地价值。
结语:让 2D 模型 “反哺” 3D,打开新一代 3D 重建大门
DIFIX3D+ 展示了 2D 扩散模型在 3D 渲染修复中的巨大潜力。它无需改变原始建模流程,即可显著提升重建质量,为未来更加通用、智能、高效的 3D 场景生成与理解提供了坚实基础。


