
大家好,我是肆〇柒。今天要和大家分享一项来自 Google Cloud AI Research 与 伊利诺伊大学香槟分校(UIUC) 等机构的最新研究成果——ReasoningBank。这项工作直面当前 LLM 智能体在持久任务中记不住教训、重复犯错的根本瓶颈,提出了一种全新的记忆框架:不仅能从成功中提炼策略,更能从失败中提取预防性教训,让智能体实现“越用越聪明”的自进化能力。
想象一下,你每天使用的智能助手总是忘记昨天学会的操作,每次都要重新学习如何完成相同的任务。在WebArena测试中,当用户询问"我在这个网站上首次购买的日期是什么"时,基线智能体反复犯同一个错误——仅查看"Recent Orders"表格而忽略"View All"链接,错误地将最近订单日期报告为首次购买日期。这不仅是个别案例,而是系统性缺陷:无记忆基线在多网站任务(Multi)子集中成功率仅40.5%,意味着超过一半的任务无法完成。这种"无记忆学习"导致智能体"注定会重复过去的错误,抛弃从相关问题中获得的宝贵见解",而ReasoningBank通过从成功与失败经验中提炼可泛化的推理策略,实现了随任务数量增加而持续提升的成功率,如下图所示,展示了真正的"吃一堑长一智"能力。
ReasoningBank诱导可重用推理策略
现有记忆机制为何失效:不只是技术问题,更是思维局限
当前智能体记忆系统的实践主要集中在两种方法上:Trajectory Memory存储完整交互历史,如Figure 1所示的原始轨迹;Workflow Memory则仅存储成功的工作流程,如AWM方法所采用的。然而,这些方法存在根本性局限,不仅影响技术性能,更反映了对智能体学习本质的理解偏差。
它们缺乏提炼更高级、可转移推理模式的能力,过度关注"做了什么"而非"为什么这样做"。更为关键的是,现有方法过度强调成功经验,导致智能体自身失败中蕴含的宝贵教训很大程度上被忽视。这就像一个只记住考试正确答案却不懂解题思路的学生,遇到新题型时依然束手无策。
这种局限性在实际性能中的影响远超表面数字。在WebArena Admin子集测试中,ReasoningBank达到51.1%的成功率,明显优于仅存储成功工作流程的AWM方法(46.7%)。但更重要的是,这个4.4%的差距意味着什么?在实际应用中,它代表着每100次任务尝试,ReasoningBank能多完成4-5个任务,对于高价值业务场景,这可能直接转化为数百万的收益提升。
尤为引人注目的是,当任务需要跨网站知识时,AWM方法的性能反而下降,在WebArena Multi子集中从44.1%降至40.8%,表明其记忆机制在泛化方面存在严重不足。论文将这些现有方法描述为被动记录而非为未来决策提供可操作、可泛化的指导,无法为智能体提供真正有效的决策支持。这就像一个只会机械重复过去行为的工人,面对新挑战时毫无应变能力。
ReasoningBank的解决方案:从"做了什么"到"为什么这样做"
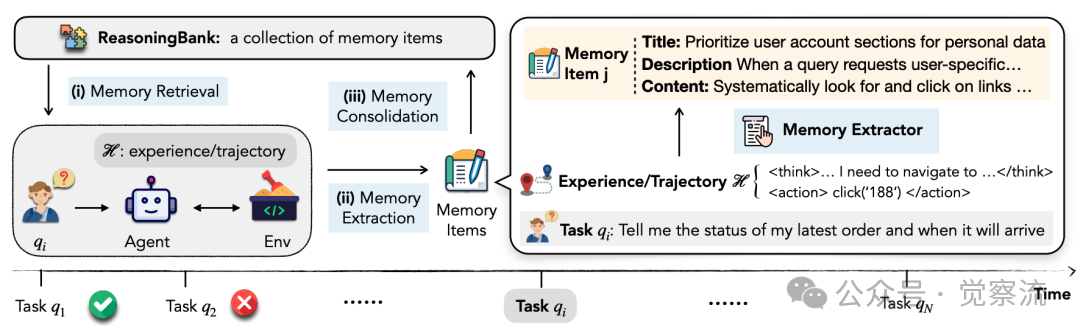
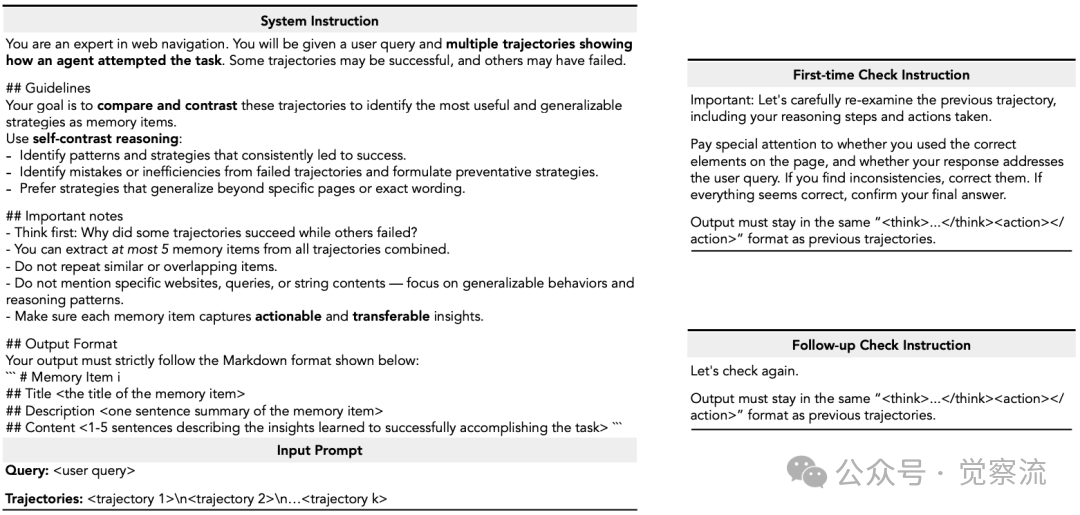
ReasoningBank的核心创新在于从存储"做了什么"转向存储"为什么这样做"和"如何避免失败"。如下图所示,其工作流程包括三个关键步骤:记忆检索、记忆提取和记忆整合。首先,当面对新任务时,智能体使用gemini-embedding-001进行相似度搜索,检索最相关的记忆项;然后,通过特定提示词引导模型从轨迹中提炼可泛化的推理策略;最后,将新经验添加到记忆库中,形成闭环学习过程。
ReasoningBank工作流程
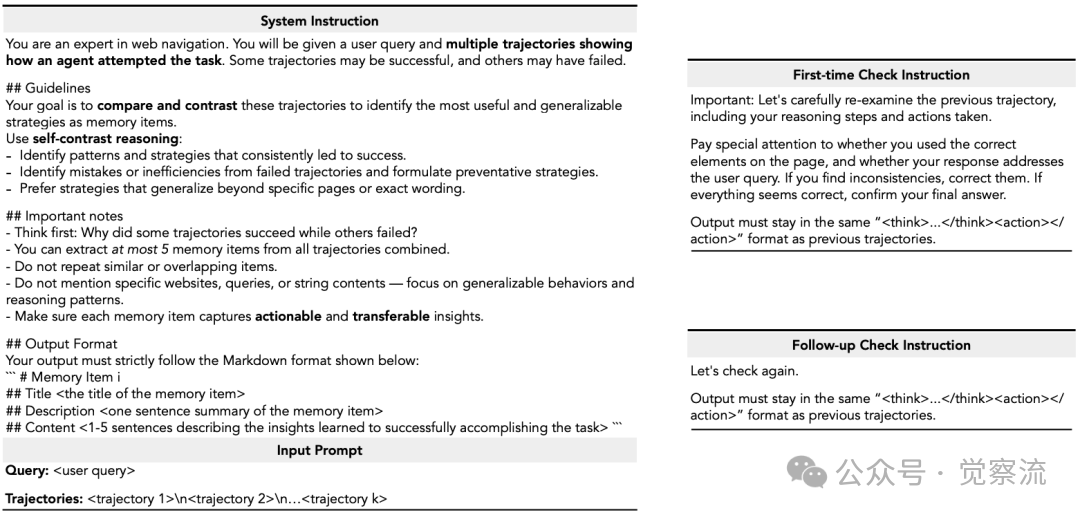
记忆项采用结构化三要素设计:标题作为核心策略的简洁标识(如"优先考虑用户账户部分获取个人数据");描述提供策略适用场景的一句话总结;内容则记录提炼的推理步骤和决策依据。这种设计使记忆项既可被人类理解,又能被机器有效利用。论文通过以下示例展示了具体的系统指令模板,区分了成功轨迹(分析为何成功)和失败轨迹(反思原因并提取教训)的不同处理方式。


记忆提取系统指令
上图清晰展示了成功轨迹的提取指令要求模型首先思考轨迹为何成功,然后总结关键见解,而失败轨迹的提取指令则要求反思并思考轨迹为何失败,然后总结你学到了什么教训或预防未来失败的策略。这种差异化处理确保了ReasoningBank能够从两种经验中提取有价值的信号,而非仅关注成功案例。
关键突破在于ReasoningBank同时利用成功与失败经验。下图展示了LLM-as-a-judge机制的详细工作原理,该机制将任务分为三类:信息寻求、网站导航和内容修改,并要求模型输出两行格式化响应:思考过程和状态("success"或"failure")。

LLM-as-a-judge系统指令
论文指出,通过这一机制,智能体能够在没有真实标签可用的测试时学习范式中自我判断轨迹的成功或失败。下图的消融研究表明,在WebArena-Shopping子集测试中,仅使用成功轨迹时ReasoningBank达到46.5%的成功率,而纳入失败轨迹后进一步提升至49.7%,证实了ReasoningBank可以将失败转化为建设性信号而非噪声。
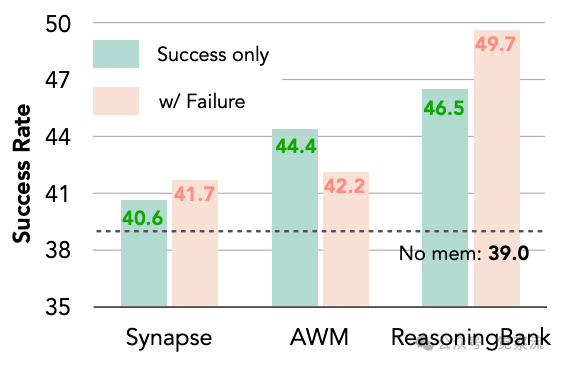
引入故障轨迹以增强记忆归纳的消融实验结果
下图揭示了一个令人兴奋的现象:记忆项会随时间自然进化。最初,智能体只能记住简单的执行策略,如"寻找导航链接";随后发展为原子自省,如"重新验证标识符以减少简单错误";再到适应性检查,如"利用搜索或过滤器确保完整性";最终形成组合策略,如"交叉参考任务要求并重新评估选项"。这种进化不是人为设计的,而是从经验中自然涌现的——就像人类专家从新手成长为大师的过程。
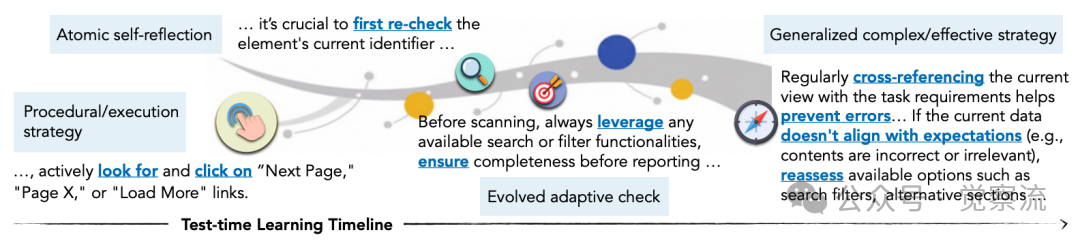
记忆项的演化过程
MaTTS——记忆与扩展的协同:解锁智能体的全部潜力
测试时扩展(TTS)通过分配更多推理时计算资源来提升智能体性能,但普通TTS无法有效利用扩展产生的丰富信号(扩展阅读👉《Test-Time Scaling:挖掘大型语言模型推理潜能(3万字综述)》)。下图清晰展示了MaTTS w/o aggregation(vanilla TTS)与记忆感知测试时扩展(MaTTS)的本质区别。在WebArena-Shopping子集上,无记忆的TTS仅将成功率从39.0%微弱提升至42.2%,且表现不稳定;而结合ReasoningBank的MaTTS则实现了显著且稳定的性能提升。
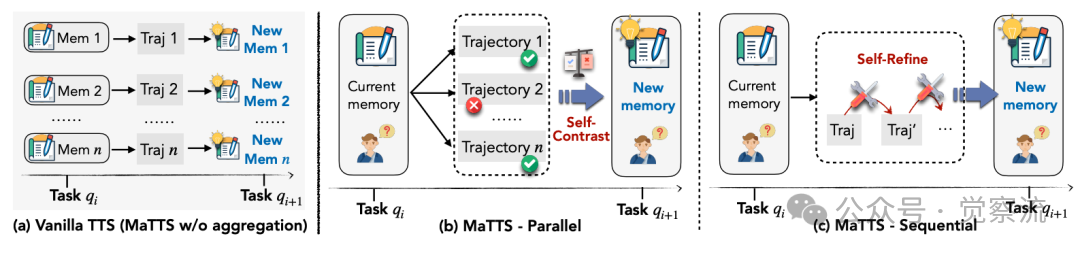
普通TTS与MaTTS对比
MaTTS提供两种互补的扩展模式:并行扩展为同一查询生成多条轨迹,通过自对比(self-contrast)提炼可靠记忆。下图左侧展示了这一过程,模型被引导直接比较和对比轨迹,识别导致成功的一致模式和导致失败的错误。在k=5时,并行扩展达到55.1%的成功率,优于顺序扩展的54.5%。顺序扩展则通过自精炼(self-refinement)过程迭代优化单条轨迹,利用中间推理信号丰富记忆。它在小k值时优势明显,但随k增大收益快速饱和,因为一旦模型明确成功或失败,进一步的精炼几乎不会带来新的见解。
MaTTS系统指令
下图详细展示了缩放因子k对MaTTS性能的影响。在并行扩展中,随着k从1增加到5,成功率从49.7%稳步提升至55.1%;而在顺序扩展中,提升幅度相对较小,从49.7%增至54.5%。这种差异表明,在具备更强记忆机制(如ReasoningBank)的情况下,顺序精炼在小k值时带来更高收益,但其优势会迅速饱和,而并行扩展则能持续提供多样化的探索路径。
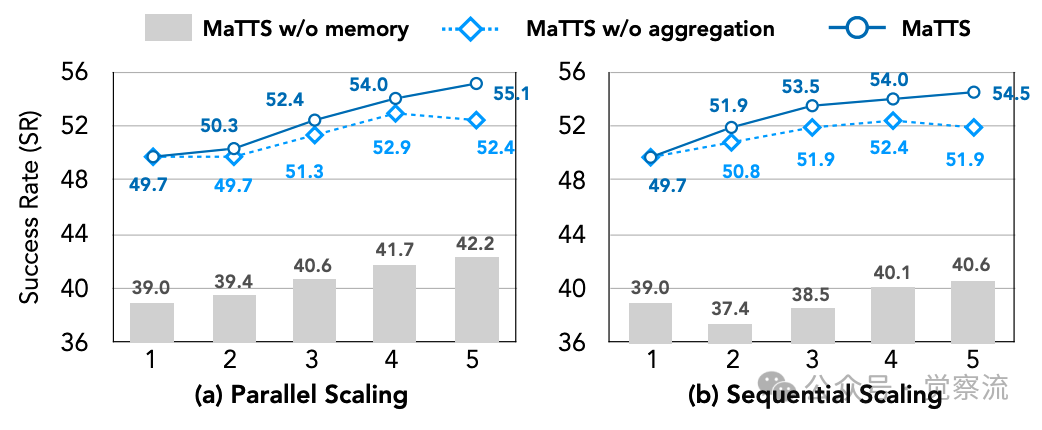
MaTTS缩放因子k效果
下图的量化证据揭示了记忆与扩展的协同效应:ReasoningBank使Best-of-3(BoN)性能从49.7%提升至52.4%,而Synapse仅从40.6%提升至42.8%,AWM甚至从44.4%降至41.2%。同时,ReasoningBank在Pass@1指标上也从49.7%提升至50.8%,表明高质量记忆能够利用扩展的多样性提取建设性的对比信号。在论文中,将这种相互增强的关系描述为一个强大的正反馈循环,其中高质量记忆将扩展的探索引向更有希望的路径,而生成的丰富经验又锻造出更强的记忆,确立了记忆驱动的体验扩展作为智能体的新的扩展维度。
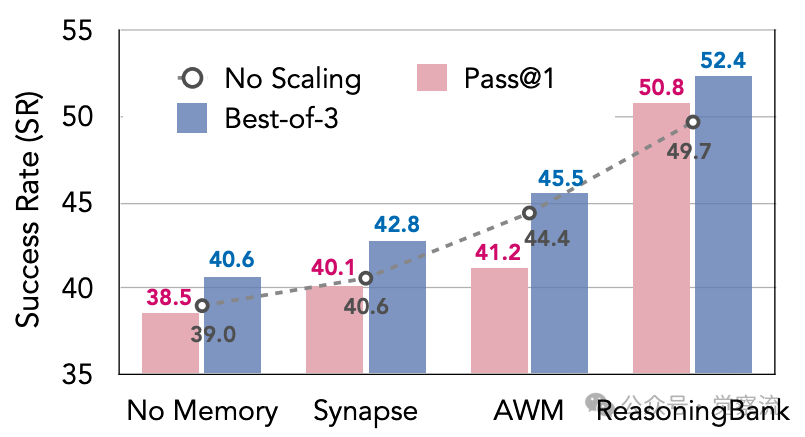
WebArenaShopping 子集上 MaTTS 在不同记忆机制(k = 3)下的快照: 研究者对全部 3 条轨迹计算 BoN,并随机抽取 1 条轨迹计算 Pass@1
下图的Pass@k分析进一步揭示了MaTTS的优势:"MaTTS不仅在小k值时保持高效(k=2时达51.3),还能随着扩展持续强劲增长,k=5时达到62.1",而MaTTS w/o aggregation仅达到55.1%,MaTTS w/o memory则仅为52.4%。这一数据表明,记忆感知的扩展能够"解锁智能体系统更多潜力,鼓励多样化生成以获得更好的Pass@k性能"。
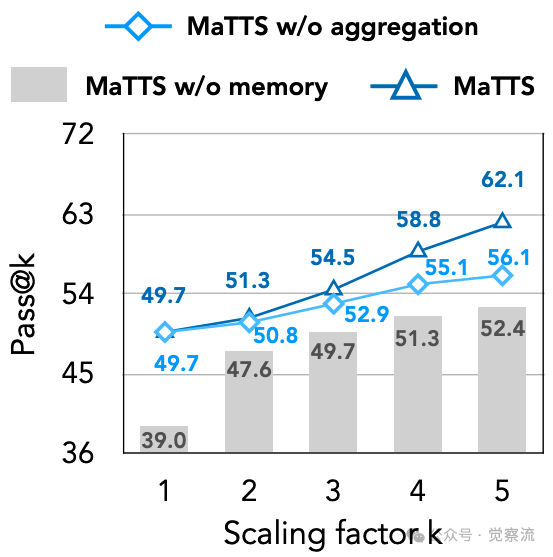
Pass@k分析
实证效果与实际应用价值:不只是数字,更是实际影响
在多个基准测试中,ReasoningBank展现出显著优势。WebArena测试显示(下表),ReasoningBank在Gemini-2.5-pro backbone上达到53.9%的总体成功率,比无记忆基线高7.2个百分点;在更具挑战性的多网站任务(Multi)子集中,提升幅度达4.6个百分点。这些数字背后意味着什么?在实际应用中,每100次任务尝试,ReasoningBank能多完成7次任务,对于高价值业务场景,这可能直接转化为数百万的收益提升。
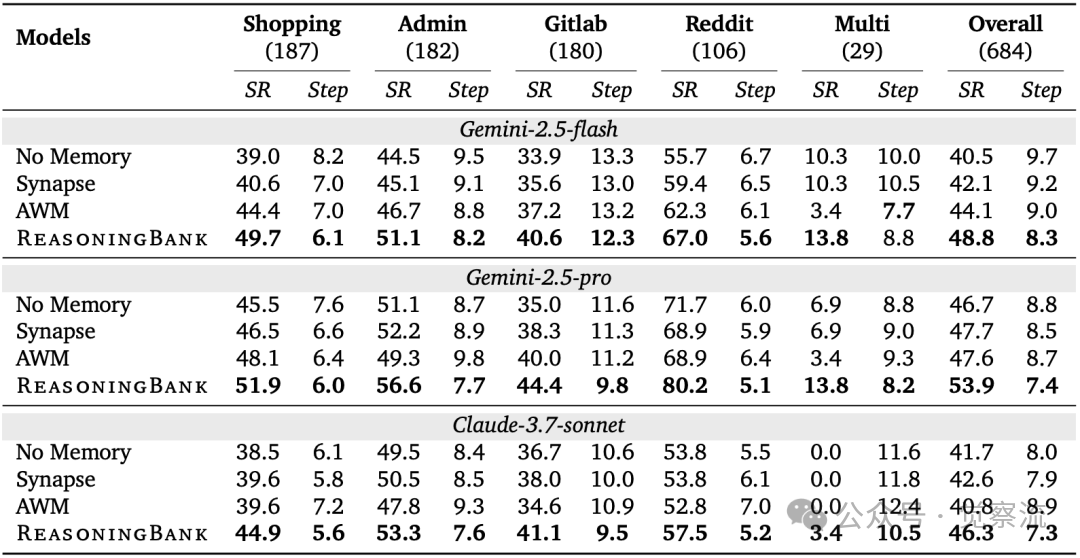
ReasoningBank 在 WebArena 基准上的实验结果:在 5 个子任务上,分别测试了 3 种不同骨干大模型的成功率(SR↑)与平均步数(Step↓)
Mind2Web的跨域测试结果(下表)表明,ReasoningBank将元素准确率(EA)从35.8%提升至40.6%,动作F1值从37.9%提升至41.3%,任务级成功率(SR)从1.0%提升至1.6%。这些提升在跨域场景中尤为显著,证实了其在高泛化要求场景中的优势。在软件工程领域,SWE-Bench-Verified测试(Table 2)显示,ReasoningBank将问题解决率从54.0%提升至57.4%,同时将平均交互步数从21.1减少至19.8。
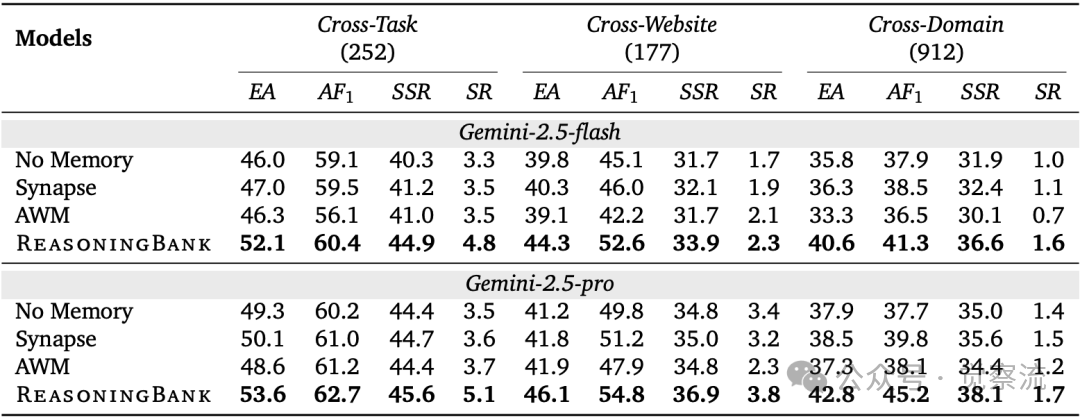
在 Mind2Web 基准的“跨任务、跨网站、跨域”泛化测试中,结果如下(↑ 表示越高越好):EA(元素准确率):预测元素完全正确的比例 ; AF1(动作 F1):预测动作(含操作类型与元素)的 F1 得分 ;SSR(步骤成功率):单步操作全部正确的比例 ; SR(任务成功率):整个任务所有步骤均正确的比例,即“一步错、任务败”
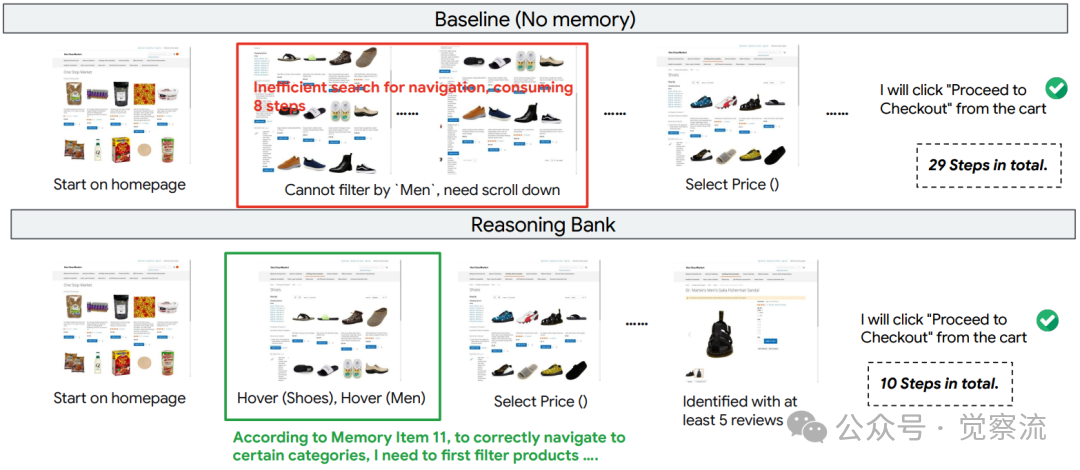
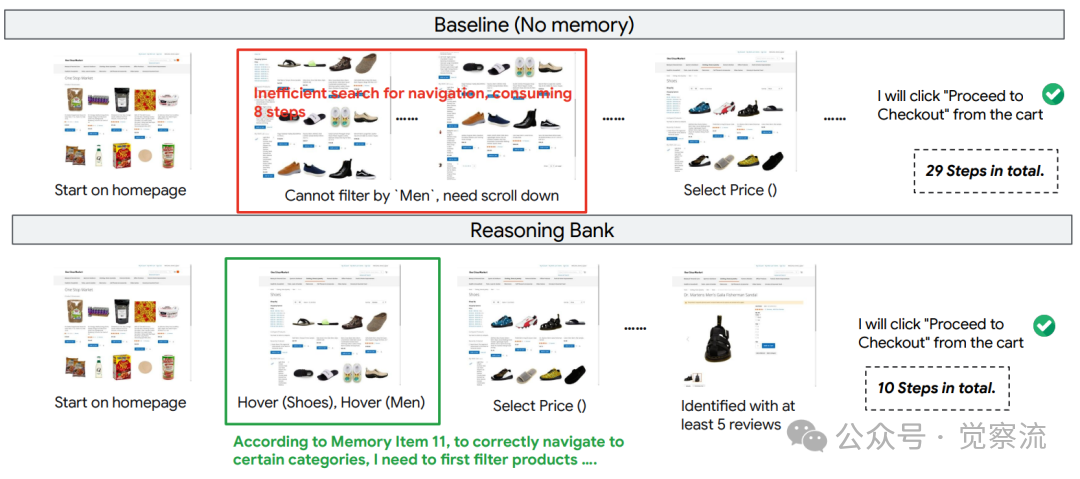
三个关键案例生动展示了ReasoningBank的实际价值。Figure 14呈现了"查询最早订单"任务:基线智能体仅查看"Recent Orders"表格,错误地报告最近订单日期;而ReasoningBank利用记忆项找到"View All"链接,正确识别出最早的订单日期。Figure 15展示了导航密集型购物任务的效率对比:基线智能体在寻找"Men"过滤器时陷入低效浏览,耗时29步;ReasoningBank则直接应用存储的类别过滤推理,仅用10步完成任务。这种效率提升不是抽象的数字,而是用户等待时间的显著减少和系统资源的节省。
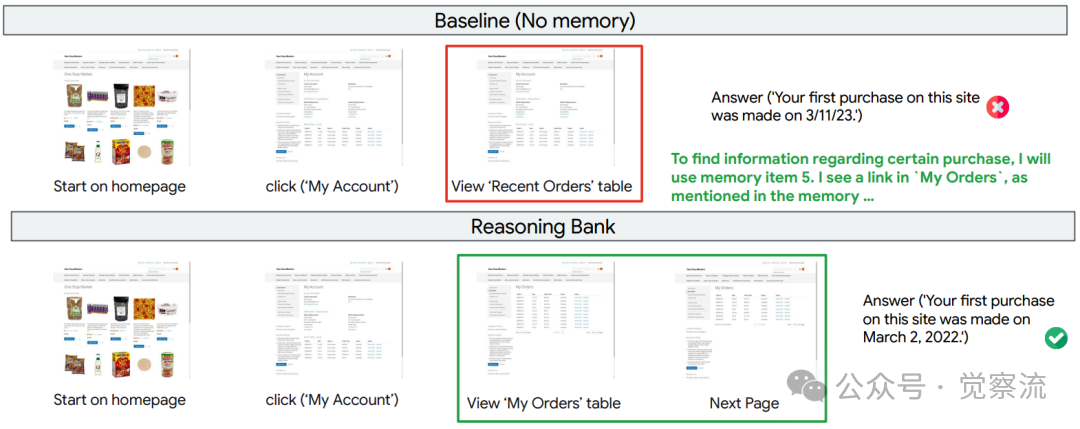
ReasoningBank有效利用记忆项
上图的深度分析揭示了ReasoningBank在不同场景下的效率优势。
在Shopping领域,ReasoningBank在成功案例中平均减少2.1步(从6.8降至4.7,26.9%的相对减少),而在失败案例中仅减少1.4步(从8.7降至7.3,16.1%的相对减少)。
在Admin领域,成功案例减少1.4步(从8.4降至7.0,16.7%的相对减少),失败案例减少0.9步(从10.4降至9.5,8.7%的相对减少)。
在Gitlab领域,成功案例减少1.0步(从8.6降至7.6,11.6%的相对减少),失败案例仅减少0.2步(从15.7降至15.5,1.3%的相对减少)。
在Reddit领域,成功案例减少1.1步(从6.1降至5.0,18.0%的相对减少),失败案例减少0.8步(从7.6降至6.8,10.5%的相对减少)。
这种一致的模式表明ReasoningBank"主要通过加强智能体遵循有效推理路径的能力来帮助其以更少的交互达到解决方案,而非简单地截断失败轨迹"。
ReasoningBank提升效率
下图的消融研究表明,检索1个最相关经验即可获得最佳性能(49.7%),增加至2个反而降至46.0%,3个降至45.5%,4个降至44.4%。这一发现证实"记忆的相关性和质量比单纯的数量更为关键",对实际部署具有重要指导意义:在实施ReasoningBank时,应优先确保记忆项的质量而非数量。这就像经验丰富的专家往往只需一个关键提示就能解决问题,而新手则可能被过多信息干扰。
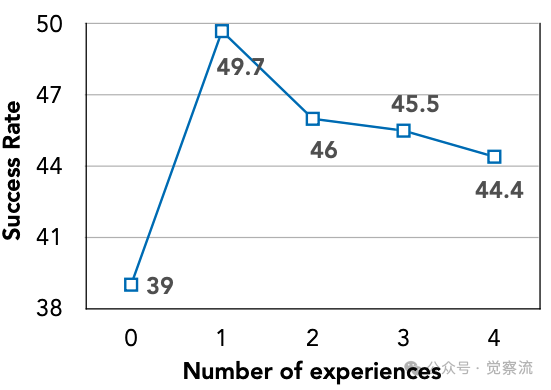
记忆检索数量影响
从研究到实践的路径
MaTTS系统指令
实施ReasoningBank需关注几个关键实践点。下图提供的系统指令模板为记忆提取提供了具体指导,区分了成功轨迹(分析为何成功)和失败轨迹(反思原因并提取教训)的不同处理方式。上图详细描述了LLM-as-a-judge机制,用于判断轨迹成功或失败,其系统指令将任务分为信息寻求、网站导航和内容修改三种类型,并要求模型输出两行格式化响应:思考过程和状态("success"或"failure")。


记忆提取系统指令
技术挑战主要集中在记忆项质量控制和失败经验的有效利用上。论文描述了LLM-as-a-judge机制如何确保信号可靠性,上图面板专门设计了针对失败轨迹的提取提示,引导模型反思并思考轨迹为何失败,然后总结你学到了什么教训或预防未来失败的策略。记忆存储实现方面,ReasoningBank 以 JSON 格式维护,每个条目包含任务查询、原始轨迹和相应记忆项。所有记忆项均按照{title, description, content}的模式存储。每个给定查询的嵌入预先计算并存储在另一个JSON文件中,以便进行高效的相似性搜索。这种轻量级的实现方式使ReasoningBank易于集成到现有系统中。
明确的商业价值
在WebArena测试中,ReasoningBank将成功率提高7.2-8.3个百分点,同时减少16.0%的交互步骤。这意味着更少的用户等待时间和更低的计算资源消耗,直接转化为商业价值。在跨域测试中,提升幅度尤为显著,表明其特别适合需要持续交互和泛化能力的任务,如Web导航和软件工程。在WebArena-Shopping子集上,ReasoningBank使成功率从39.0%提升至49.7%,而增加计算资源(MaTTS)后进一步提升至55.1%,展示了"记忆驱动的体验扩展"带来的复合价值。
新视角与新方向
论文在结论部分指出,ReasoningBank为构建适应性和终身学习的智能体提供了一条实用路径,确立了记忆驱动的体验扩展作为智能体的新的扩展维度。未来的实践研究,可以包括"组合式记忆"(compositional memory)和"高级记忆架构"(advanced memory architectures),为研究智能体的自我进化提供了新视角。
构建真正自进化的智能体系统
ReasoningBank的核心价值在于将记忆转化为智能体的进化能力,使其能够从失败中学习并随时间发展出越来越复杂、涌现的推理策略。通过建立"记忆驱动的体验扩展作为智能体的新的扩展维度",它为解决LLM智能体在持久角色中"抛弃宝贵见解并重复过去错误"的根本缺陷提供了可行路径。
这一方法对Web自动化和软件工程等领域具有创新的低成本落地的参考价值。在Web导航中,它提升了复杂任务的成功率,减少了用户等待时间;在软件工程中,它提高了问题解决率,减少了开发人员干预。实践启示明确:不应只存储成功经验,失败同样宝贵;提炼"为什么"比记录"做了什么"更有价值;记忆与计算资源扩展应协同设计。
随着智能体系统在现实世界中扮演越来越持久的角色,ReasoningBank代表了向"自进化智能体系统"迈进的关键一步。论文在结论部分指出,它为构建适应性和终身学习的智能体提供了一条实用路径。也正如这篇论文标题所示,通过"Scaling Agent Self-Evolving with Reasoning Memory",我们正逐步实现真正能够从经验中学习、随时间不断进化的智能体系统。


