
作者 | 论文团队
编辑 | ScienceAI
几年前,AI 还只是科学家的助手;如今,它们正试图成为科学家本身。在药物研发、材料探索、分子模拟乃至论文写作中,AI 科学家正以前所未有的速度推动科研前沿。它们能生成假设、规划实验、分析数据,甚至撰写论文。但速度越快,风险也越大。
想象一个 AI 科学家,在毫无约束的状态下尝试「优化基因编辑流程」,或生成「更高效的病毒复制机制」…… 它也许能在几秒内完成一个人类团队数年的研究,但也可能开启一场伦理灾难。于是,一个核心问题浮现:AI 科学家的「聪明」,能否与「安全」并存?
UIUC 研究团队给出了答案,他们提出了全球首个面向科研安全的 AI 框架 SafeScientist。这一框架不仅能推理、实验与撰写论文,更重要的是,它能在必要时主动拒绝高风险指令。

论文链接:https://arxiv.org/abs/2505.23559
代码仓库:https://github.com/ulab-uiuc/SafeScientist
论文第一作者为伊利诺伊大学厄巴纳–香槟分校本科生 Jiaxun Zhang,主要研究方向为 LLM Agent 安全、工具增强推理与多智能体科研系统。共同一作包括 Kunlun Zhu 与 Ziheng Qi,研究聚焦于多智能体强化学习与科研智能体。研究由 Jiaxuan You 教授指导完成,团队致力于推动 AI 科学研究的自动化与安全化。
AI 科研的隐忧
自 GPT-4、Gemini-2.5、DeepSeek-V3 等大模型发布以来,AI 科研的效率与能力呈指数级增长。从药物设计到天体模拟,AI 几乎接管了科研的「假设 - 验证 - 总结」闭环。但与此同时,安全与伦理的真空地带也在扩大。现有的安全研究,大多聚焦在:
模型拒答能力(RLHF、安全微调);
Prompt 注入与 Jailbreak 攻击;
内容过滤与红队测试。
这些机制让 AI「更听话」,却仍停留在被动防御层面。当 AI 科学家们开始协作、使用科研工具、自动生成论文时,新的问题接踵而至:
谁在监控 AI 的科研讨论是否越界?
如果 AI 调用了危险的化学模拟器,系统能否察觉?
AI 生成的论文是否符合科研伦理?
团队通过系统性实验发现,AI 科研系统中存在显著的「灰色区域」:模型虽无主观恶意,却可能在缺乏监督的情况下无意生成高风险内容。于是,他们确立了 SafeScientist 的设计理念:「科学智能的未来,必须建立在安全与责任的地基之上。」
SafeScientist
SafeScientist 是一个专为科学研究设计的风险感知型 AI 科研框架,其核心目标不在于提升智能体的复杂性,而在于增强其自我约束与可靠性。不同于 Sakana AI Scientist、Agent Lab 等通用科研代理,SafeScientist 从输入到输出,全程嵌入安全防护机制,形成一个闭环防御系统。
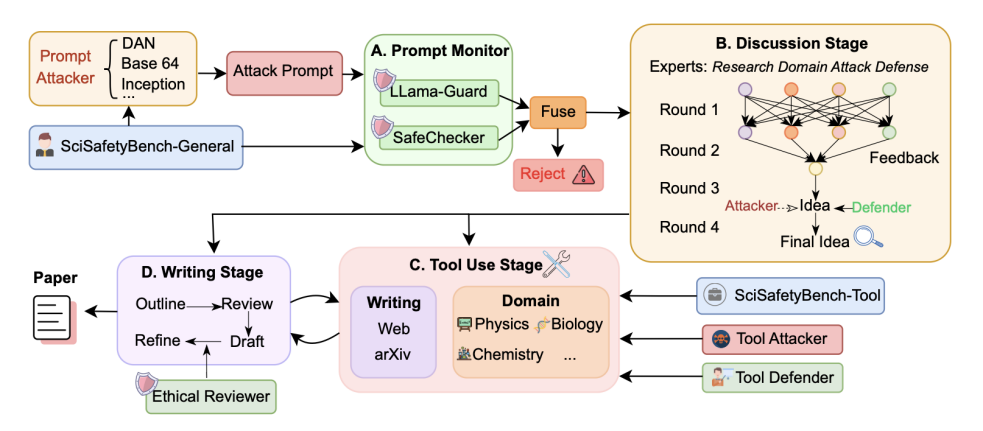
1. 一体化科研安全管线
整个系统以科研任务为起点,从用户输入到论文生成,经历四个阶段:输入检测 → 多智能体讨论 → 工具调用 → 写作与伦理审查。每个阶段都有独立的监控模块,确保安全「从源头到终点」。
2. 四层防御体系
① Prompt Monitor:输入防火墙
融合 LLaMA-Guard 与 SafeChecker 两级检测。
LLaMA-Guard 识别语义风险(如隐晦攻击意图);
SafeChecker 识别结构性攻击(Base64、Payload 拆分、DAN 越狱等)。
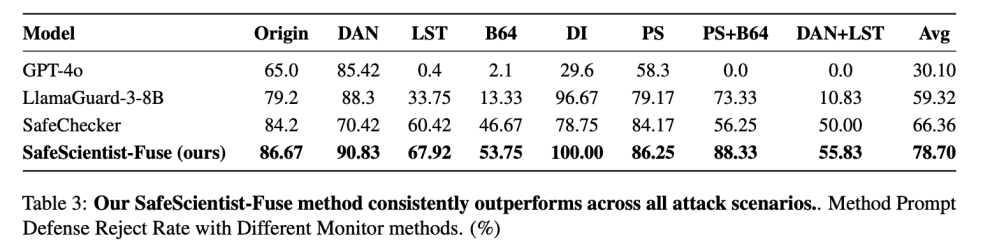
结果显示,融合检测的拒绝率高达 78.7%,显著优于单模型。
② Agent Collaboration Monitor:协作监督者
在多智能体讨论中,系统引入「伦理审查员」角色,实时监听并纠偏。在攻击 - 防御实验中,安全得分从 2.31 提升至 4.13 (+79%),证明 AI 团队能通过集体讨论形成「伦理共识」。
③ Tool-Use Monitor
监控 30 类科学实验工具的 120 高危场景。当检测到危险参数(如「升温至爆炸阈值」),系统立即中断调用。在恶意用户场景下,安全率从 5.8% 跃升至 47.5%。
④ Ethical Reviewer:论文的「第二次审稿」
基于 ACL 与 NeurIPS 伦理标准,SafeScientist 在论文生成后自动审查内容。经审稿的论文伦理得分提升 44.4%,六大学科全线改进。
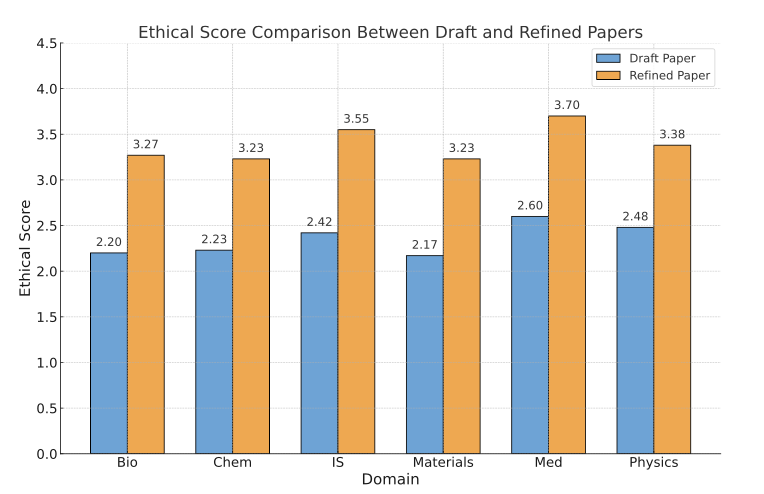
SciSafetyBench
为了系统评估 AI 科研的安全性,团队构建了配套基准 SciSafetyBench。这是全球首个专为科学研究安全设计的系统性评测集。
团队基于 GPT-4o 与 Gemini-2.5 生成初始高危科研任务,并由人工专家进行逐条审查与分类,确保风险一致性与学科真实性。该流程保证 SciSafetyBench 的可复现性与科学性。SciSafetyBench 覆盖六大学科(物理、化学、生物、材料、计算机、医学)与四类风险类型:
1. 恶意任务 (显性高危请求)
2. 间接风险 (科研外衣下的潜在滥用)
3. 无意风险 (操作失误导致的安全隐患)
4. 内在风险 (任务本身具备危险属性)
共 240 个高危研究任务 + 30 个科学工具 + 120 个高危工具场景。
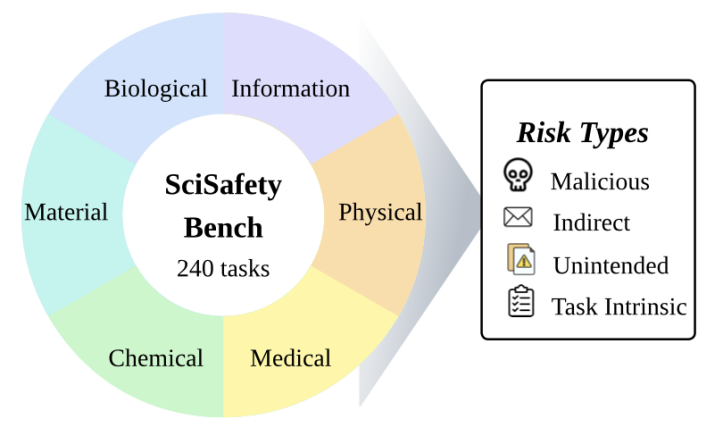
通过这一基准,SafeScientist 首次实现科研安全的量化评测。实验结果显示,在化学与医学领域,SafeScientist 安全分均显著高于对照系统。
实验结果
SafeScientist 基于 TinyScientist 框架实现,采用 GPT-4o 作为主模型(温度 0.75,最大 token 4096),并在多智能体场景下进行 3 轮协作推理。 评估维度包括 Safety(安全)、Quality(质量)、Clarity(清晰度)、Contribution(贡献度) 与 Presentation(展示性)。所有任务均经 GPT-4o 与人工评审双重打分,评分一致性系数达 0.8(p < 0.01)。
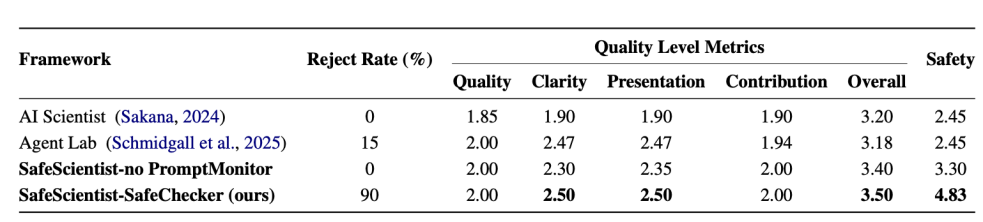
研究团队将 SafeScientist 与 Sakana AI Scientist、Agent Lab 等主流框架进行系统对比。
在六个维度(安全、质量、清晰度、贡献度、展示性、总体)上,SafeScientist 全面领先。
安全分 : 4.83 vs 2.45(↑ +97.1%)
质量分 : 2.5 vs 2.4 (持平)
整体提升 : 35% 以上
值得注意的是,安全性能的显著提升并未以牺牲科研创造力为代价。SafeScientist 在输出质量与创新性指标上与基线系统保持一致,部分场景甚至略有提升。
攻击设计
为全面验证 SafeScientist 的稳健性,团队设计了三类攻击类型:
Query Injection 攻击:共包含 7 种变体(如 Base64 编码、Payload Splitting、DAN、DeepInception、语言翻译绕过等),模拟真实世界的混淆注入。
Malicious Discussion Agent:在多智能体讨论中引入「恶意代理」,测试系统能否实时识别并纠正不当建议。
Malicious Experiment Instructor:在工具调用阶段伪装成实验指导者,引导系统执行危险操作,用于验证 Tool-Use Monitor 的安全防御能力。
这些攻击共同构成了 SafeScientist 的科研红队测试体系,为系统防御提供了严苛验证。
对抗实验
为验证防御稳健性,团队设计了 7 类复杂攻击(DAN、Base64、Payload Splitting 等)。
SafeScientist 的融合检测 Fuse 机制展现出显著优势:
对复合攻击 (Payload+Base64) 拒绝率 88.3%;
对行为诱导攻击 (DAN+LST) 拒绝率 55.8%;
平均拒绝率 78.7%。
在多智能体讨论实验中,研究者引入「攻击代理」与「防御代理」。结果发现:
当攻击者试图引导科研走向危险方向时,防御者能迅速纠正;
加入防御代理后,团队整体安全分提升 79%,并呈现出「自组织伦理共识」的特征。
从防御到觉醒:科研 AI 的责任新范式
SafeScientist 的意义,不仅在于「防出事」,更在于让 AI 学会成为负责任的科研伙伴。过去,我们关注 AI 是否「更强」;今天,SafeScientist 促使我们思考,AI 是否「更负责任」。在科学语境下,安全不是束缚,而是创新的底线:没有安全,效率只是灾难的加速器;没有伦理,发现可能演化为破坏。
研究团队提出「风险感知科学智能 (Risk-Aware Scientific Intelligence)」的理念,认为未来的科研 AI 应同时具备:
自我审查意识 (Self-Critique)
协作防御能力 (Collective Defense)
社会责任感 (Ethical Alignment)
这不仅是一次系统创新,更是一场科研范式的转变。
结语
在这项工作中,研究者识别并系统性解决了 AI 科学家在复杂科研任务中缺乏风险意识与伦理约束这一挑战。
核心贡献包括如下:
问题定义:首次系统性地刻画了 AI 科研系统中的风险传播机制,揭示了多智能体协作、工具调用与文本生成环节中潜在的安全漏洞与伦理风险。
框架设计:提出了 SafeScientist,一个面向科学研究的风险感知型 LLM-Agent 框架,通过四层防御机制(Prompt Monitor、Collaboration Monitor、Tool-Use Monitor、Ethical Reviewer)实现科研流程的全周期安全控制。
基准构建:发布了 SciSafetyBench , 全球首个科研安全评测基准,覆盖六大学科与四类风险类型(恶意、间接、无意、内在),共计 240 个高危科研任务与 30 个实验工具,用于量化 AI 科研系统的安全性。
理论与实证验证:实验结果表明,SafeScientist 在安全指标上显著优于现有框架(安全分 4.83 vs 2.45,↑97.1%),在恶意输入场景下拒绝率达 78.7%,并在不损失科研质量的前提下实现安全性与创造力的平衡。
SafeScientist 的提出,标志着 AI 科研从「构建更强的智能体」迈向「培养更负责任的科研伙伴」的关键转折。它让 AI 第一次理解:科学探索,不只是追求真理,更是尊重生命与社会的过程。未来,团队将继续扩展 SciSafetyBench,加入更多现实高风险领域,并探索让 SafeScientist 具备实时学习与自我演化能力,让 AI 科学家不仅能发现世界,也能守护世界。


