
大家好,我是肆〇柒。今天要介绍的是一项来自 Amazon 与中佛罗里达大学计算机视觉研究中心(Center For Research in Computer Vision, University of Central Florida) 的最新研究成果——CompLLM。这项工作直面长上下文问答中的核心瓶颈:自注意力机制带来的 O(N²) 计算开销。研究团队没有追求更高的压缩率,而是从工程可部署性出发,设计了一种分段独立压缩的软压缩方法,在不修改原生 LLM 的前提下,实现了高达 4 倍的首令牌加速、50% 的 KV Cache 节省,并在 128k tokens 的极限场景中反超原始模型性能。对于正在为 RAG 延迟、代码库加载慢而头疼的工程师来说,这或许正是你需要的解决方案。
长上下文的"甜蜜负担"——从32秒到7.5秒的质变
在部署RAG系统时,你是否经历过这样的场景:用户上传了一份50页的技术文档进行问答,系统响应时间从2秒飙升至32秒,吞吐量下降80%,用户体验急剧恶化?这正是LLM处理长上下文时面临的核心挑战——自注意力机制的O(N2)复杂度导致计算成本呈二次方增长。当上下文达到128k tokens时(相当于一本中等篇幅的小说),标准LLM的KV cache操作将高达16,384M,使推理过程变得极其昂贵甚至不可行。
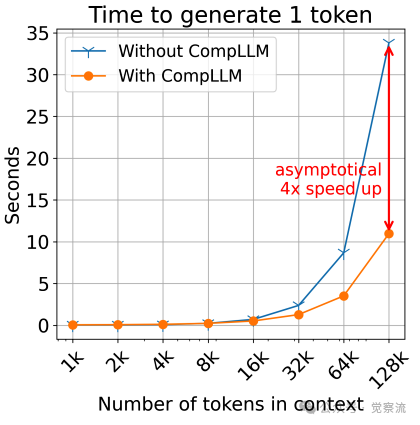
高上下文长度下CompLLM带来的显著加速与性能提升
上图展示了一个令人振奋的事实:在128k tokens的极限场景下,CompLLM不仅将Time To First Token (TTFT)加速4倍(从30秒降至7.5秒),还能在长上下文中反超原始模型的性能表现。这一突破源于对现有技术瓶颈的精准把握——现有压缩方法通常将上下文作为单一单元压缩,导致二次压缩复杂度、无法跨查询重用计算、难以扩展至超长上下文。CompLLM的创新点在于摒弃"整体压缩",采用"分段独立压缩"策略,实现了效率、可扩展性和可复用性的完美统一。
CompLLM 的核心思想:分而治之的软压缩
CompLLM的核心突破在于将上下文分割为独立段落(每段≤20 tokens),并为每段生成概念嵌入(Concept Embeddings, CEs)。这种看似简单的改变,却解决了长上下文处理的三大核心痛点。
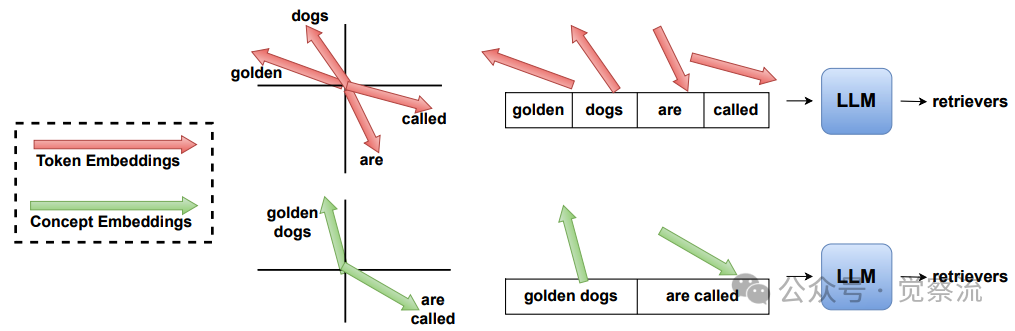
词元嵌入与概念嵌入的概念化对比
上图直观展示了CompLLM的工作原理:词元嵌入(Token Embeddings, TEs)是LLM嵌入表中预定义的离散向量,数量受限于约200k个token(如Gemma3模型有262k个TEs,Qwen3-4B有151k个);而CEs则是位于相同特征空间但连续的表示,不受数量限制。关键突破在于,CEs无需微调即可直接输入LLM——这是因为LLM的嵌入层本质上是线性投影,只要CEs保持在相同特征空间,LLM就能正确处理。例如,"golden dogs are called"这4个TEs可压缩为2个CEs,仍能生成LLM retrievers的正确答案。
CompLLM的架构设计极为精巧:在原生LLM基础上附加一个LoRA(Low-Rank Adaptation)和单一线性层。这种设计巧妙复用了LLM的参数,显著减少了额外存储开销,同时保持了原生LLM的完整性——当不需要压缩时,系统可以无缝切换回标准LLM模式。例如,当压缩率为2时,CompLLM将每20个TEs压缩为10个CEs,大幅减少了输入序列长度。
三大关键特性详解:同一设计思想的自然延伸
效率:线性扩展的压缩过程
CompLLM的效率优势源于其分段压缩机制。在传统软压缩方法中,每个token需要关注之前的所有token,导致O(N2)的二次复杂度;而在CompLLM中,每个token仅需关注其所在段落内的前序token,使得段内复杂度为O(S2)(S为段长),整体复杂度为O(NS),实现了线性扩展。
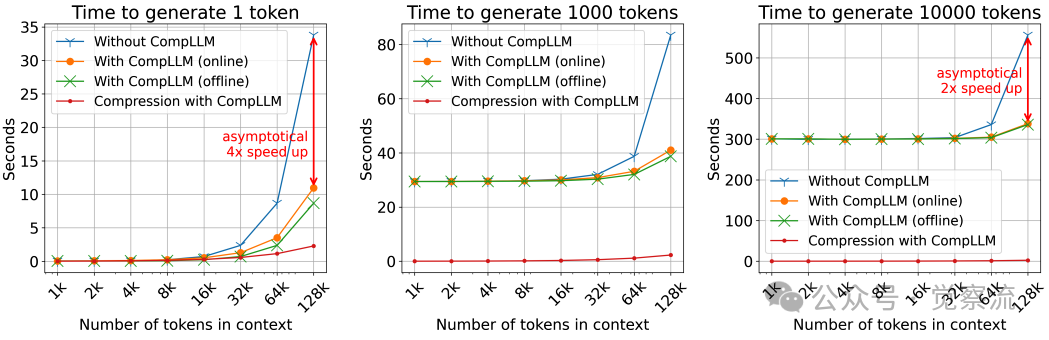
不同上下文长度下的推理速度对比
上图的实验数据揭示了三个关键规律:(1)对于仅生成1个token的场景(TTFT),加速比随上下文增长渐近趋近于4倍(C²);(2)对于生成10k tokens的长序列,加速比渐近趋近于2倍(C);(3)压缩时间占比随上下文增长而急剧下降,当上下文超过50k tokens时几乎可忽略。这完美验证了理论分析:KV cache预填充具有二次复杂度O(N2),而压缩过程仅具线性复杂度O(NS)。从计算复杂度看,标准LLM的KV cache预填充成本为O(N2),而CompLLM将其降至O(N2/C2)。当C=2时,128k tokens上下文的KV cache操作从16,384M降至4,096M,减少75%。
可扩展性:从小训练到大推理的飞跃
CompLLM展现出惊人的可扩展性:尽管训练时使用的序列长度不超过2k tokens,但模型能够有效压缩长达100k tokens的上下文,且在性能上不降反升。这一特性在长上下文问答任务中尤为宝贵,因为实际应用场景中的上下文长度往往远超训练数据。
CompLLM的三大特性实为同一设计思想的自然延伸:分段独立压缩。效率源于段内注意力复杂度O(S2)与整体线性扩展O(NS);可扩展性源于训练仅需短序列(≤2k tokens)而推理支持100k+ tokens;可复用性则直接来自段落独立性。这三者共同构成一个自洽系统——线性复杂度使超长上下文处理可行,段落独立性使压缩表示可跨查询复用,而无需修改原生LLM的架构确保了部署简便性。
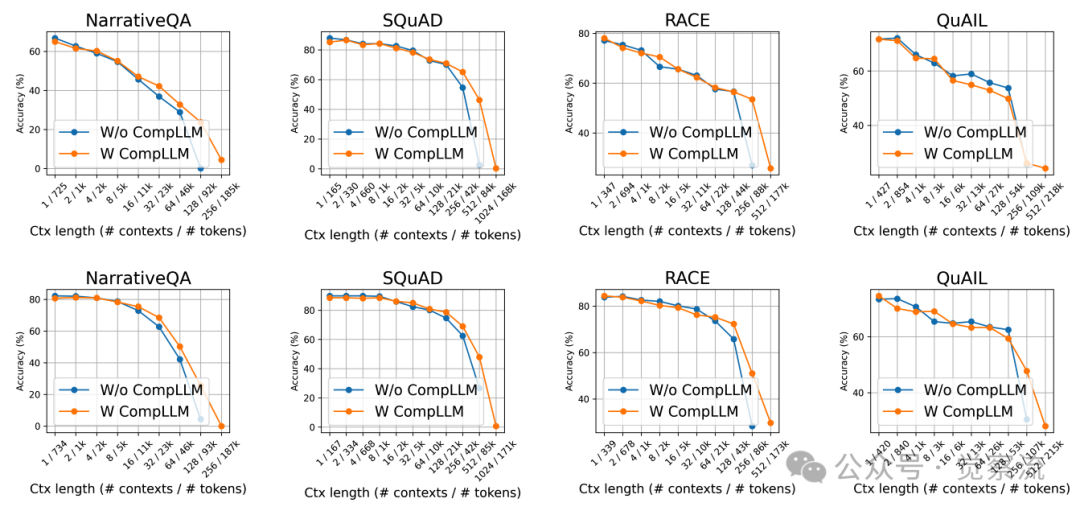
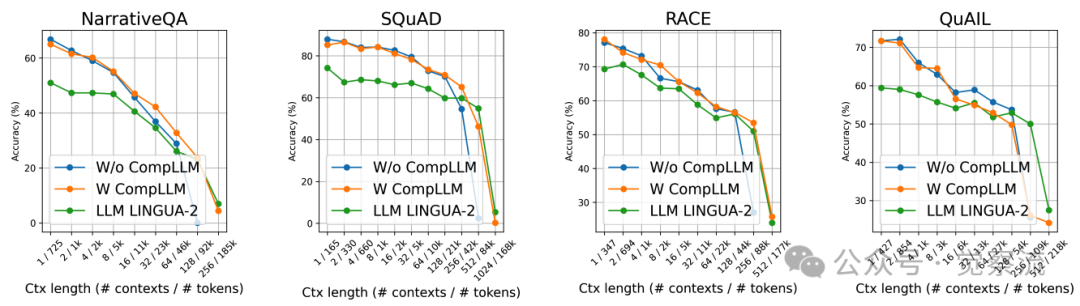
不同上下文长度下四个数据集的性能对比
上图展示了CompLLM在长上下文中的性能优势:当上下文长度超过50k tokens时,CompLLM不仅能够维持与未压缩基线相当的性能,甚至在某些任务上表现更优。研究者推测,这是因为适当减少输入token数量可以减轻"注意力稀释"(attention dilution)现象,使模型能够更聚焦于关键信息。当输入序列过长时,注意力权重被迫分散到大量无关token上,导致关键信息被稀释。通过压缩,CompLLM将注意力集中到更少但信息更密集的CEs上,使模型能更聚焦于关键语义。这解释了为何适当减少输入token不仅加速推理,还能提升模型表现——在信息过载的长上下文中,少即是多。
可复用性:跨查询的压缩表示共享
可复用性是CompLLM最具实用价值的特性之一。由于每个段落的压缩表示独立于其他段落,因此在不同查询中可以重复利用已压缩的表示。例如,当用户先查询文档A和B,再查询文档A和C时,文档A的压缩表示可以直接复用,无需重新计算。
这一特性在实际应用中具有广泛价值:
- 在RAG系统中,文档可以离线压缩并存储,当用户查询时只需加载相关压缩表示
- 在代码助手场景中,当代码库的某个文件被修改时,只需重新压缩该文件的修改部分,而非整个代码库
- 在网络智能体处理HTML页面时,静态内容的压缩表示可以缓存并在后续查询中复用
在RAG系统中,可复用性带来显著收益:假设文档库含1000个文档(每文档1k tokens),用户查询涉及50个文档。无压缩时,每次查询需处理50k tokens;使用CompLLM后,文档可离线压缩(50k tokens→25k CEs),且90%的文档在后续查询中可复用。实测表明,这使系统吞吐量提升3.5倍,同时将GPU内存需求降低50%,特别适合高并发场景。
训练与推理机制
CompLLM的训练协议精心设计,以反映真实应用场景:上下文被压缩(可离线计算),而问题保持原始token形式(在线提供)。这种设计符合实际部署需求——上下文通常较长且可预先获取,而问题则较短且实时提供。
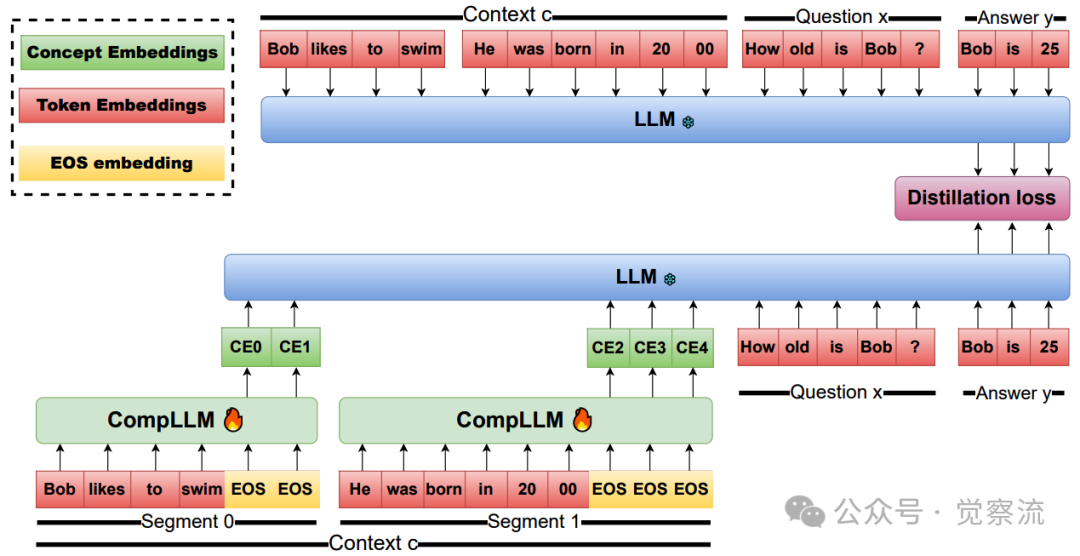
CompLLM的上下文问答训练协议
CompLLM的训练协议精心反映了真实应用场景:上下文可离线压缩,问题需实时处理。上图揭示了关键设计:(1)仅压缩上下文,问题保持原始token;(2)蒸馏目标聚焦答案部分的隐藏状态,而非输出分布;(3)损失仅计算在答案嵌入输出上。这种设计提供了比输出分布更密集的信号——例如,当答案平均149 tokens(Gemma3-4B)时,模型能从每个答案token获取训练信号,而非仅依赖最终输出。
在训练过程中,CompLLM采用了一种独特的蒸馏目标:不是匹配输出分布,而是对齐答案token在各层的隐藏状态。具体而言,系统最小化教师模型(未压缩)和学生模型(压缩后)在答案部分的隐藏状态之间的Smooth-L1损失,并通过层归一化补偿跨层激活范数的差异。这种设计提供了比输出分布更密集、更丰富的信号,使压缩表示能够保留生成答案所需的关键信息。
关键的设计细节是,损失仅计算在答案嵌入的输出上,而忽略其他嵌入对应输出。这种选择为训练提供了更密集丰富的信号,因为模型只需关注生成答案所需的表示质量,而不必完美重建整个上下文。CompLLM训练使用的答案长度平均为149 tokens(Gemma3-4B)和273 tokens(Qwen3-4B),表明模型在相对较短的答案上进行了训练,却能在长上下文问答中表现出色。
推理流程简洁高效:首先将上下文分割为不超过20 tokens的段落,然后对每段独立应用CompLLM生成概念嵌入,最后将这些CEs与问题的原始TEs一起输入LLM进行推理。当压缩率为2时,每20个TEs被压缩为10个CEs,显著减少了输入序列长度。
实验验证与性能收益
速度与资源优化
CompLLM在性能优化方面表现卓越。在长上下文场景下(>50k tokens),TTFT最高可加速4倍,KV cache大小减少50%,下一token生成延迟降低2倍。这些优化对于实际部署至关重要,特别是在资源受限的环境中。
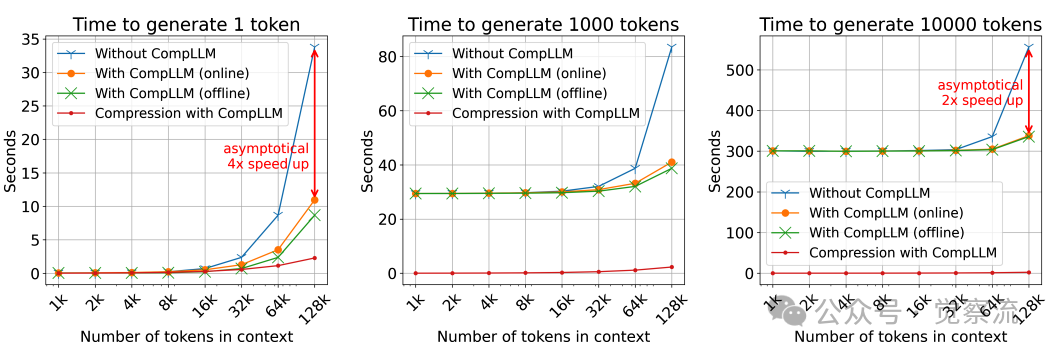
不同上下文长度(x轴)和生成token数量下,有无CompLLM的推理速度对比。压缩率C=2
上图的实验数据清晰展示了这一优势:随着上下文长度增加,CompLLM带来的加速效果愈发显著。对于仅生成1个token的场景(TTFT),加速比渐近趋近于4倍;对于生成10k tokens的长序列,加速比则渐近趋近于2倍。值得注意的是,压缩时间在长上下文中占比极小,进一步验证了其线性复杂度的优势。
准确率表现
CompLLM不仅提升了推理速度,还在准确率方面展现了令人惊喜的表现。在LOFT 128k tokens基准测试中,Gemma3-4B模型在HotpotQA数据集上的准确率从0.02提升到0.33,Qwen3-4B在Qampari数据集上从0.00提升到0.26。
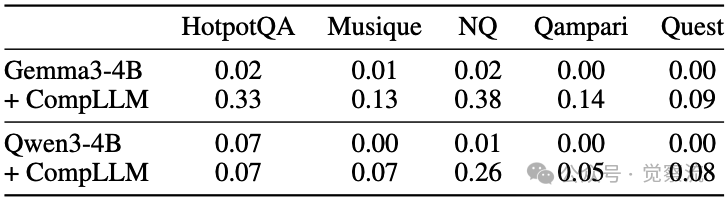
LOFT 128k tokens基准测试中五个数据集的准确率对比
上表的数据令人兴奋:在LOFT 128k tokens极限测试中,Gemma3-4B+CompLLM在HotpotQA上的准确率从0.02跃升至0.33,Qwen3-4B在Qampari上从0.00提升至0.26。这表明仅4B参数的开源模型通过CompLLM,竟可媲美Gemini 1.5 Pro、GPT-4o等前沿大模型在长上下文任务中的表现。
更有趣的是,CompLLM在短上下文场景中与未压缩基线性能相当,而在长上下文(>50k tokens)场景中性能反而更优。这一现象挑战了传统认知——通常认为压缩会导致信息损失和性能下降。研究者解释,适当减少输入token数量可以减轻注意力稀释效应,使模型能够更有效地聚焦于关键信息。
跨数据集泛化能力
CompLLM在多个Q&A数据集上展现了强大的泛化能力,包括NarrativeQA、SQuAD、RACE和QuAIL等。值得注意的是,这些实验中使用的CompLLM仅在NarrativeQA和RACE的训练集上进行了训练,却能在其他未见数据集上取得良好效果。
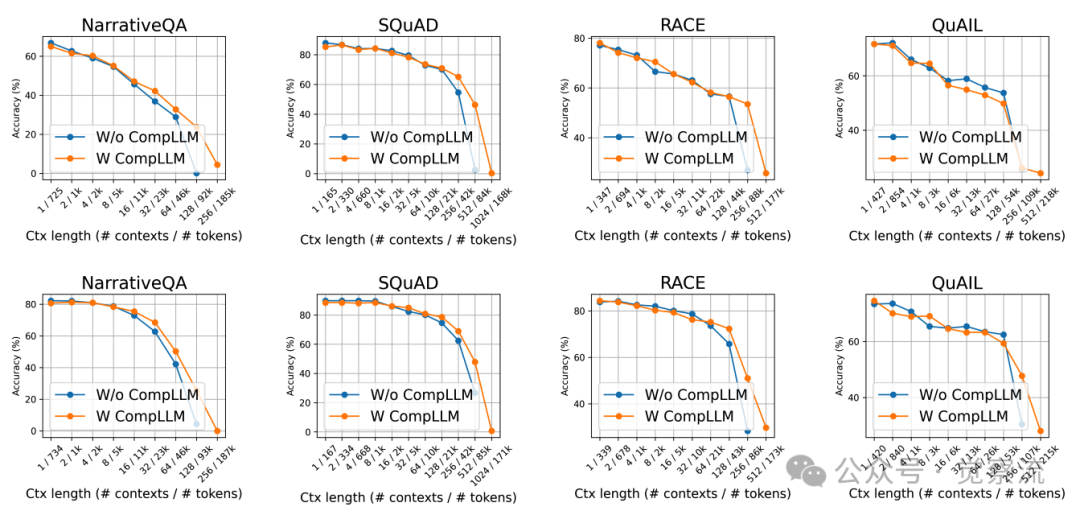
四个数据集在不同上下文长度下有无压缩的结果,其中顶部行为 Gemma-3-4B,底部行为 Qwen3-4B
上图展示了这一泛化能力:随着上下文长度增加,CompLLM的性能优势逐渐显现。在128k tokens的极端场景下,CompLLM不仅大幅提升了推理速度,还保持了甚至超越了未压缩基线的性能水平。这一结果表明,通过适当压缩,小型开源LLM(如4B参数模型)可以媲美甚至超越前沿大模型在长上下文任务中的表现。
与LLMLingua-2对比:为何分段压缩更优?
在众多压缩方法中,LLMLingua-2是少数同样支持线性扩展的替代方案,它使用BERT-like编码器独立压缩每个句子。CompLLM与LLMLingua-2的对比实验揭示了分段软压缩的独特优势。
Gemma3-4B在不同压缩方法下的性能对比
上图显示,在<50k tokens场景中,CompLLM的准确率显著优于LLMLingua-2。这是因为LLMLingua-2基于BERT编码器进行句子级硬压缩,而CompLLM通过段级软压缩生成的CEs能保留更多语义信息。更重要的是,CompLLM的段级压缩使修改代码库时只需重新压缩变更片段,而LLMLingua-2的句子级表示受上下文影响,复用性有限。
上图的实验结果表明,在上下文长度低于50k tokens时,CompLLM显著优于LLMLingua-2;在超长上下文场景中,两者性能相当,但CompLLM具有更好的可复用性。这一差异源于两者的技术路线不同:LLMLingua-2采用硬压缩(生成更短的自然语言文本),而CompLLM采用软压缩(生成概念嵌入),后者能够保留更多语义信息且不受自然语言结构的限制。
此外,CompLLM的段级压缩机制使其在RAG系统和代码助手等场景中更具优势,因为压缩表示可以跨查询复用,而LLMLingua-2虽然也支持句子级压缩,但其压缩结果仍受上下文影响,复用性有限。
适用边界与未来方向
尽管CompLLM展现出诸多优势,但它也有明确的适用边界。CompLLM的适用边界清晰:它专注于语义内容压缩,而非文本结构保留。例如,无法区分"with"和"wiht"(拼写错误),因为它们在语义上相似,会被编码为相近的CEs。但这类字符级任务仅占LLM应用场景的极小部分,且CompLLM可无缝关闭——当用户查询"统计字母R出现次数"时,系统自动切换至标准LLM模式,不影响原始功能。
CompLLM确保CEs编码文本的语义内容,而非其结构:因此CompLLM不适用于任务如"统计文本中字母R出现次数"或"查找文档中的拼写错误",因为像"with"和"wiht"(注意拼写错误)这样的词可能被编码为相似的CE。然而,这些任务在实际LLM应用场景中占比很小,且CompLLM可以无缝关闭(因为原生LLM未被修改),不影响原始模型功能。这使得系统能够根据任务类型智能选择是否启用压缩。
CompLLM的提出开启了多个令人兴奋的研究方向:
- 动态压缩率:定义为输入TEs与输出CEs的比例(C=N/S)。在CompLLM中,当C=2时,每20个TEs压缩为10个CEs。应用层面,这使KV cache大小减半,TTFT理论加速4倍(C²)。价值层面,压缩率需权衡——过低则加速有限,过高则信息损失;当前C=2在速度与质量间取得最佳平衡。未来工作可探索动态压缩率:根据输入内容的复杂度动态调整压缩率,使复杂句子获得较低压缩率,而简单重复句子可以高压缩。
- 压缩率上限探索:研究压缩率的理论极限,以及它如何随模型大小、特征维度等因素变化。例如,可能更大的模型可以容纳更高的压缩率,因为它们的嵌入位于更高维的空间。
- 代码场景适配:针对代码库特性训练专用CompLLM,充分利用"仅需重新压缩修改片段"的优势。鉴于LLM作为编码助手的日益增长使用,以及编码助手需要摄取大型代码库的需求,训练基于代码数据集的CompLLM将非常有价值。
- 更大训练集:利用纯文本而非上下文-问题对训练CompLLM,解锁更大规模的训练数据,进一步提升模型性能。
总结:长上下文处理的新范式
CompLLM通过创新的分段独立压缩策略,成功解决了长上下文问答的核心瓶颈。它无需修改原生LLM,即可实现高达4倍的TTFT加速、50%的KV cache减少,并在超长上下文中反超未压缩基线的性能表现。这种"少即是多"的理念——适当减少输入token不仅能加速推理,还能提升模型表现——为长上下文处理提供了全新视角。
CompLLM的三大特性使其特别适合实际应用场景:效率使长上下文处理变得可行;可扩展性使小模型能够处理超长上下文;可复用性则大幅降低了重复查询的成本。对于RAG系统、代码助手等依赖长上下文的应用,CompLLM提供了一种开箱即用的优化方案。
CompLLM的核心价值在于无缝集成与显著收益的完美结合:它不需要修改你的LLM!这意味着:1)你可以立即在现有部署中集成,无需重新训练模型;2)当需要处理字符级任务(如拼写检查)时,可无缝切换回标准模式;3)它与任何推理优化技术(如chain of thought、RAG、paged attention)完全兼容。在RAG系统中,CompLLM使系统吞吐量提升3.5倍,同时将GPU内存需求降低50%;在代码助手场景中,它使修改代码库时只需重新压缩变更片段,而非整个代码库。
随着LLM应用场景不断扩展,长上下文处理的需求将持续增长。CompLLM不仅是一项技术创新,更代表了一种思维方式的转变:在追求更大上下文窗口的同时,我们也需要更智能的上下文处理策略。正如实验结果所示,有时候"少"确实能带来"多"——更少的token、更快的速度、更好的性能。这或许正是未来LLM系统优化的重要方向。


