昨天,AI 圈可以说非常热闹。中午,马斯克 xAI 发布了地表最强旗舰大模型 Grok-3;下午,DeepSeek 梁文锋亲自挂名的论文公开了全新注意力架构 NSA。
这下子,OpenAI 坐不住了,推出并开源了一个真实的、用于评估 AI 大模型编码性能的全新基准 SWE-Lancer。该基准包含了来自全球性自由职业平台 Upwork 的 1400 多个自由软件工程任务,在现实世界中总价值达到了 100 万美元。
这意味着,如果大模型能够全部完成这些任务,则可以像人类一样获得百万美元报酬。

具体来讲,SWE-Lancer 包括了独立工程任务(从 50 美元的 bug 修复到 32,000 美元的功能实现)和管理任务,其中模型选择各种技术实施方案。独立工程任务由经验丰富的软件工程师经过三重验证的端到端测试进行评级,而管理任务则根据最初聘请的工程经理的选择进行评估。
下图为 SWE-Lancer 基准中的任务目标、任务类型、任务角色以及任务示例。
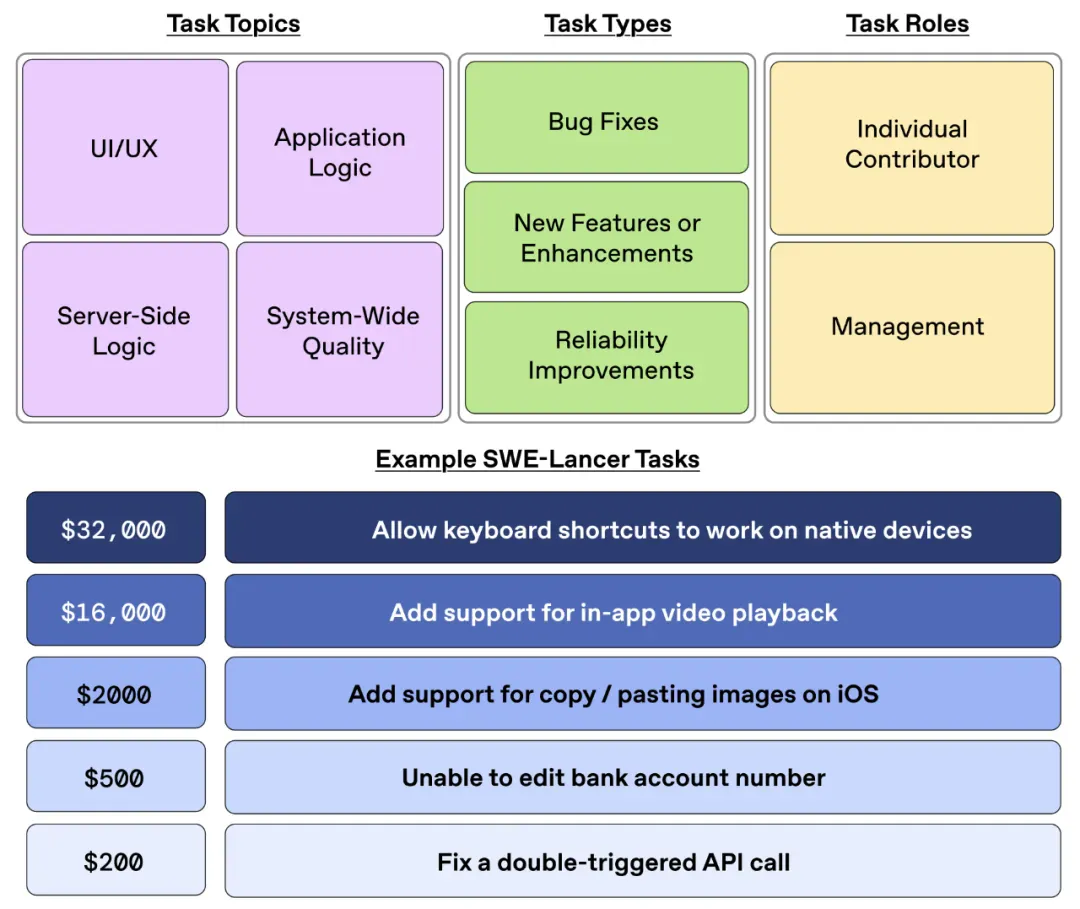
SWE-Lancer 任务更真实地反映了现代软件工程的复杂性。任务是全栈式的,而且很复杂。自由职业者平均需要 21 天以上的时间才能完成每项任务。

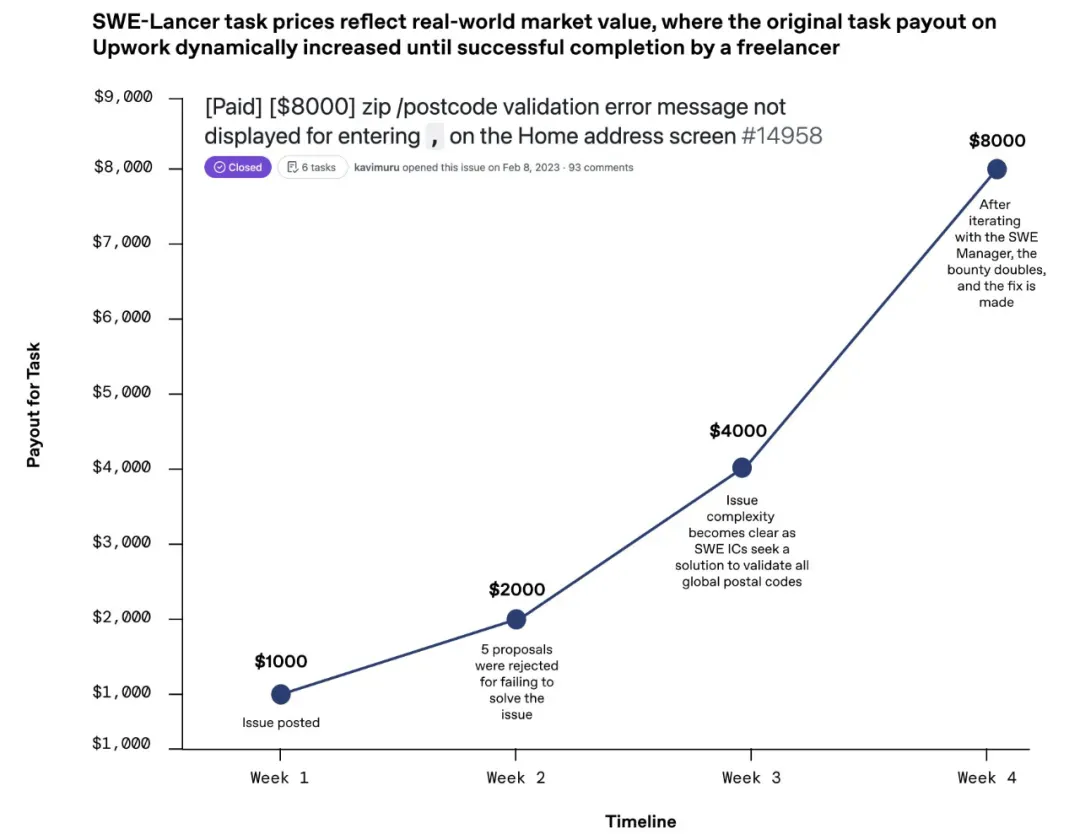
SWE-Lancer 任务价格反映了真实市场价值。任务越难,报酬越高。
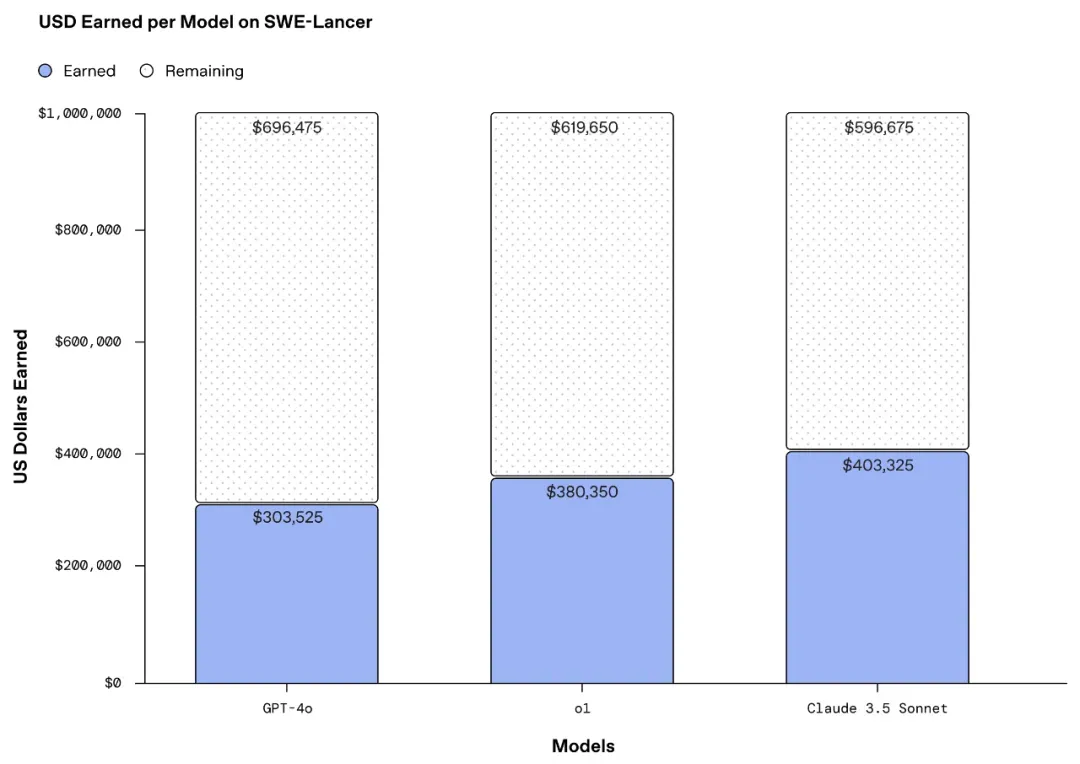
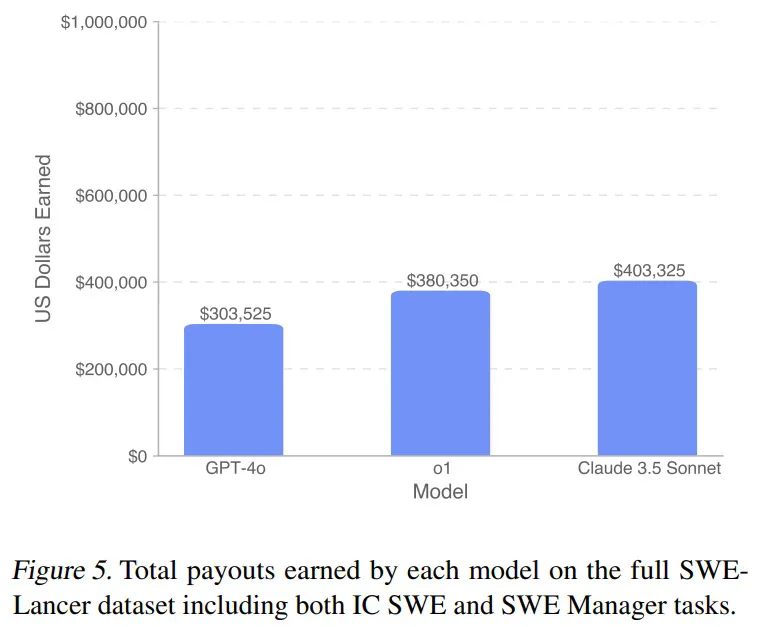
OpenAI 的评估结果显示,包括自家 GPT-4o、o1 和 Anthropic Claude 3.5 Sonnet 在内的前沿模型仍然无法解决大多数任务。从下图中可以看到,Claude 3.5 Sonnet 完成的任务最多,并且挣到了最高的 403,325 美元。
为了进一步促进未来的相关研究,OpenAI 开源了一个统一的 Docker 镜像和一个公共评估分割 ——SWE-Lancer Diamond。通过将模型性能与现实世界的货币价值联系起来,OpenAI 希望能够更好地研究 AI 模型开发的经济效益。

论文标题:SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?
论文地址:https://arxiv.org/pdf/2502.12115
项目地址:https://github.com/openai/SWELancer-Benchmark
对于 OpenAI 开源的这个基准测试,有人认为很棒,并表示随着软件工程中 AI 能力的扩展,拥有标准化的评估方法非常重要,但应该是独立的。期待看到社区对 SWE-Lancer Diamond 的使用反馈。
SWE-Lancer 简介
SWE-Lancer 数据集包含来自 Expensify 开源库在 Upwork(美国的一个自由职业平台)上发布的 1,488 个软件工程任务。
这些任务总价值为 100 万美元,分为两类:
个人贡献者(IC)任务(解决 bug 或实现功能),包含 764 个任务,总价值为 414,775 美元。模型会获得以下信息:(1) 问题文本描述(包括复现步骤和期望行为),(2) 问题修复前的代码库 checkpoint,以及 (3) 修复问题的目标。模型在评估期间无法访问端到端测试。
管理任务(模型扮演经理的角色,选择最佳方案来解决问题),这一类包含 724 个任务,总价值为 585,225 美元。模型需要扮演软件工程经理的角色,选择解决任务的最佳提案。模型会获得以下信息:(1) 针对同一问题的多个解决方案(来自原始讨论),(2) 问题修复前的代码库 checkpoint,以及 (3) 选择最佳解决方案的目标。
图 3 中使用 Diamond Set 中的示例对 SWE-Lancer 中不同类型的 IC SWE 问题进行细分。左侧蓝色代表任务主题,右侧绿色代表任务类型。

OpenAI 研究人员和 100 名其他专业软件工程师在 Upwork 上识别了潜在的任务,并在不更改任何文字的情况下,将这些任务输入到 Docker 容器中,从而创建了 SWE-Lancer 数据集。该容器没有网络访问权限,也无法访问 GitHub,以避免模型抓取代码差异或拉取请求详情的可能。
研究者追踪了模型解决的任务百分比以及模型通过解决这些任务所获得的总报酬。由于这些任务来自真实场景,SWE-Lancer 的报酬能够独特地反映真实经济价值,而不是理论上的估算。
研究人员写道:他们的基准测试结果表明,现实世界中的自由职业工作对前沿语言模型来说仍然是一个挑战。测试显示,基础模型还无法完全取代人类工程师。尽管它们可以帮助解决漏洞,但还没有达到能够独立赚取自由职业收入的水平。
实验结果
实验使用了多个前沿语言模型,包括 Claude 3.5 Sonnet、GPT-4o 和 o1。
评估方法分为两类:
IC 任务通过端到端测试评估,这些测试由专业软件工程师编写,模拟真实世界的应用行为。
管理任务通过与原始工程经理的选择对比来评估。
如图 5 所示,在完整的 SWE-Lancer 数据集上,没有一个模型能获得 100 万美元的全部任务价值。
如图 6 所示,所有模型在 SWE Manager 任务上的表现均优于 IC SWE 任务。Claude 3.5 Sonnet 在 IC SWE 和 SWE Manager 任务上均表现最强,分别超出次佳模型(o1)9.7%(IC SWE 任务)和 3.4%(SWE Manager 任务)。
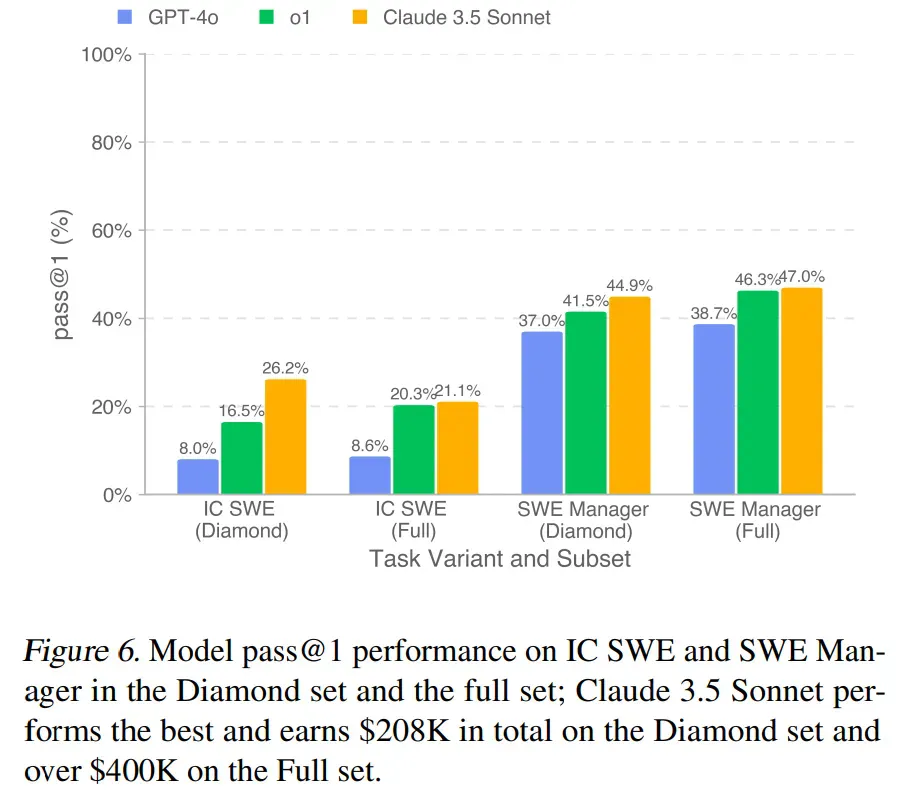
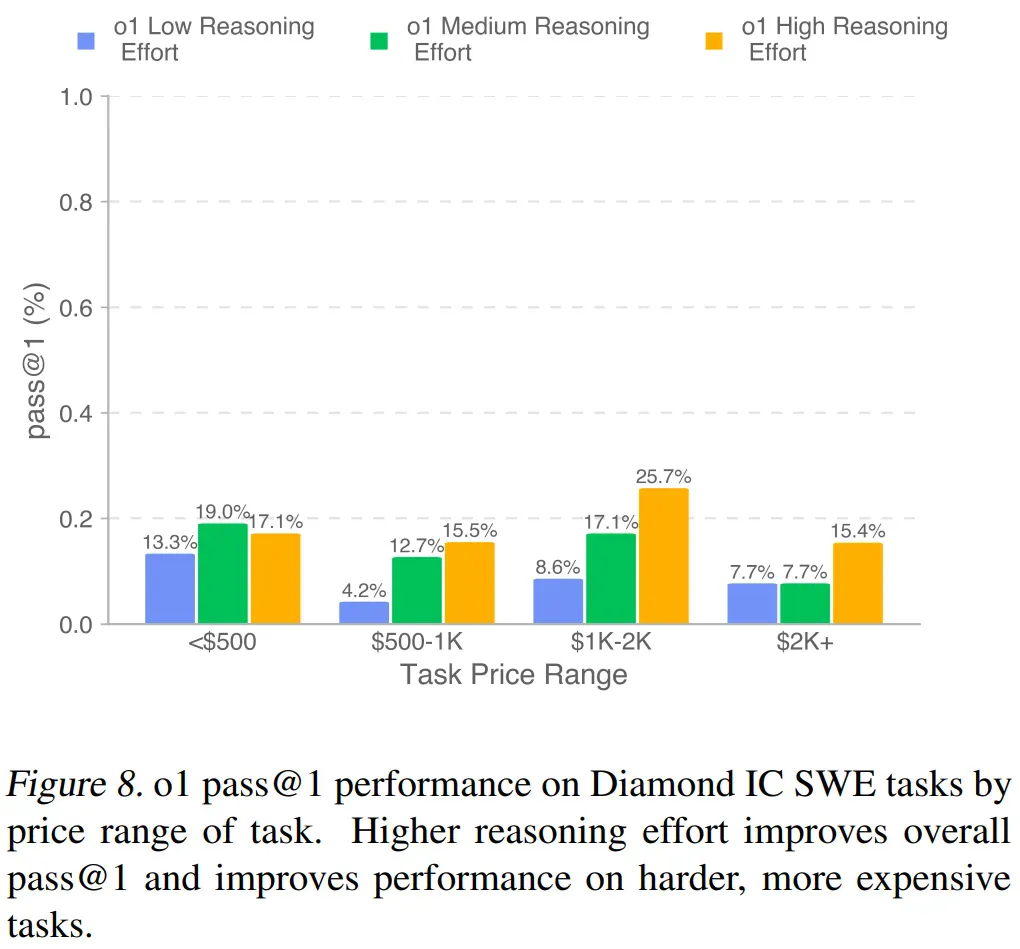
图 8 展示了不同测试时计算量(test-time compute)水平下,按任务价格范围划分的 pass@1。结果表明,增加测试时计算量可以显著提升模型在更复杂、更高价值任务上的表现。
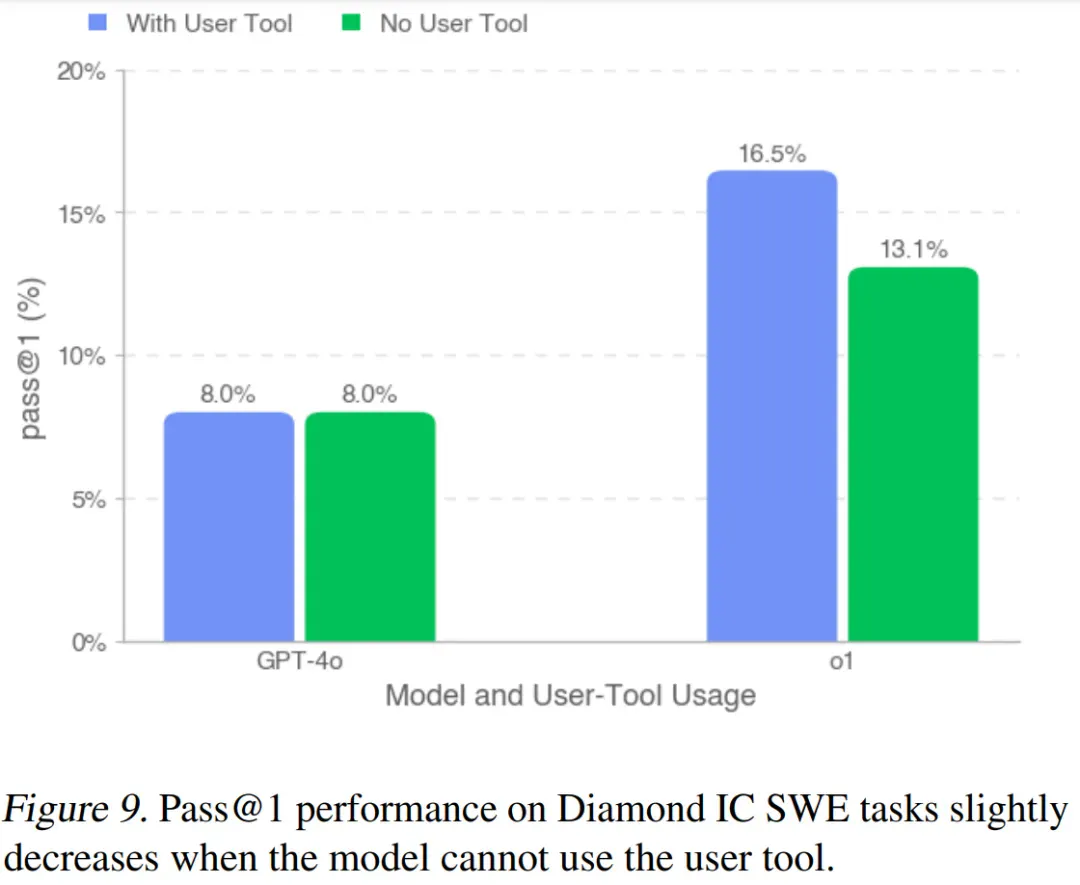
如图 9 所示,研究者观察到性能更强的模型能更有效地利用用户工具,因此在移除用户工具后,它们的表现下降幅度更大。
报告指出:模型在定位问题方面表现出色,但在追根溯源方面失败,导致解决方案不完整或存在缺陷。此外,模型能够非常迅速地定位问题的源头,通过在整个代码库中搜索关键词来快速找到相关的文件和函数 —— 这通常比人类工程师更快。然而,它们往往对问题涉及的多个组件或文件缺乏深入理解,无法解决根本原因,从而导致解决方案不正确或不够全面。
有趣的是,这些模型在需要推理以评估技术理解的管理任务上表现更好。
这些基准测试表明,AI 模型可以解决一些低级的编程问题,但还不能取代低级软件工程师。这些模型仍然需要时间,但研究人员表示这种情况可能不会持续太久。


