如今,深度生成模型(Deep Generative Models),如变分自编码器(VAE)和扩散模型,已成为图像、音频乃至视频生成领域的核心技术。
它们通过学习数据的潜在分布,赋予AI强大的「想象力」,能够创造出以假乱真的新内容。
然而,这些模型内部运作的机制却如同一个巨大的「黑箱」。
我们只知道输入指令,得到输出结果,但对于模型内部的「思考过程」——也就是那些被称为潜在变量 (latent variables) 的抽象表示——我们知之甚少。
这带来了三大难题:
- 语义缺失:潜在变量本身是数学向量,没有直接的现实世界含义。我们无法理解某个数值的变化对应着的具体语义。
- 偏见与幻觉:在解释过程中,如果忽略模型本身的「归纳偏置」(inductive bias),比如要求不同变量代表独立的因素(解耦),就很容易产生错误甚至「幻觉」的解释。
- 解释的不确定性:并非所有潜在变量都具有可解释的意义。有些变量可能只是噪声,强行解释只会误导用户。
面对上述挑战,美国埃默里大学的研究团队提出了一个通用、创新的框架LatentExplainer,旨在自动为深度生成模型中的潜在变量生成人类可理解的、语义丰富的解释。该研究已被CIKM 2025大会接收。

论文链接:https://arxiv.org/abs/2406.14862
代码链接:https://github.com/mengdanzhu/LatentExplainer
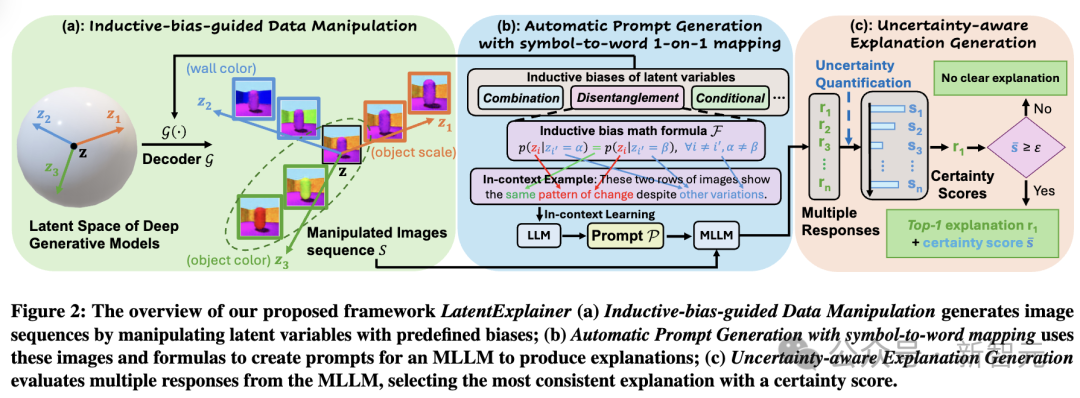
整个流程可以分为三步:
1. 归纳偏置引导的数据扰动 (Inductive-bias-guided Data Manipulation)
不是盲目地改变潜在变量,而是根据模型预设的「归纳偏置」(如解耦、组合、条件偏置)来设计扰动策略。
例如,对于一个要求「解耦」的模型,会同时扰动两个不同的潜在变量,确保它们之间的变化是相互独立的,从而更准确地捕捉每个变量的独立语义。
2. 自动智能提示生成(Automatic Prompt Generation)
研究者们将复杂的数学公式(代表归纳偏置)转化为自然语言提示(prompt),并建立了一个「符号-词语」映射表,让大模型能够理解并遵循模型的内在逻辑。
这种「数学到语言」的转换,极大地减少了大模型在解释时的「幻觉」,保证了解释的准确性。
利用预训练的语言模型作为coding agent,结合需要解释的潜变量,将自然语言提示自动生成一段修改生成模型解码器(decoder)代码的指令。
3. 感知不确定性的解释生成 (Uncertainty-aware Explanation Generation)
为了应对「并非所有变量都可解释」的问题,LatentExplainer引入了不确定性量化。它会多次向大模型(如GPT-4o)提问,然后计算所有回答之间的相似度(一致性得分)。
只有当解释足够稳定可靠(得分超过阈值)时,才会给出最终解释;否则,它会诚实地说:「无清晰解释」。
性能飞跃,解释质量显著提升
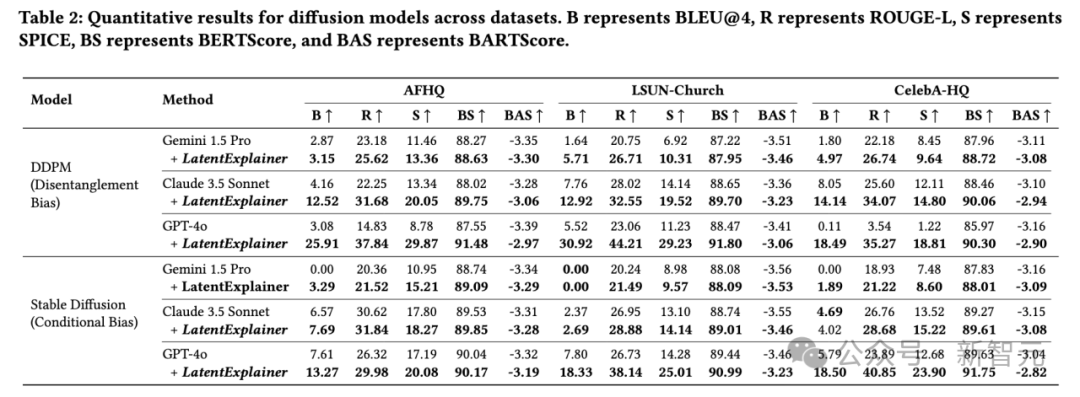
研究团队在CelebA-HQ、LSUN-Church、3DShapes等多个真实和合成数据集上进行了广泛实验,涵盖了VAE和扩散模型两大类主流生成模型,并针对三种不同的归纳偏置(解耦、组合、条件偏置)进行了评估。
全面超越基线: 无论是使用GPT-4o、Gemini 1.5 Pro还是Claude 3.5 Sonnet作为基础大模型,加入LatentExplainer后,其生成的解释在BLEU、ROUGE-L、SPICE、BERTScore、BARTScore等所有自动化评估指标上均取得显著且一致的提升。
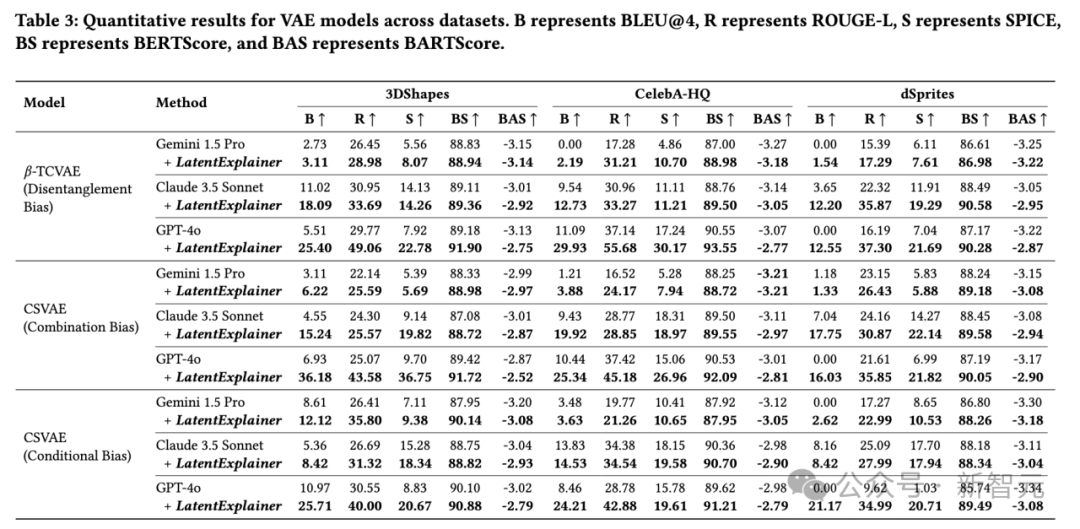
质的飞跃: 以GPT-4o在CelebA-HQ数据集上翻译Stable diffusion潜变量为例,BLEU分数从5.79飙升至18.50,ROUGE-L从23.89提升至40.85,几乎翻倍!这表明LatentExplainer不仅能「说」,还能「说得更好、更准」。
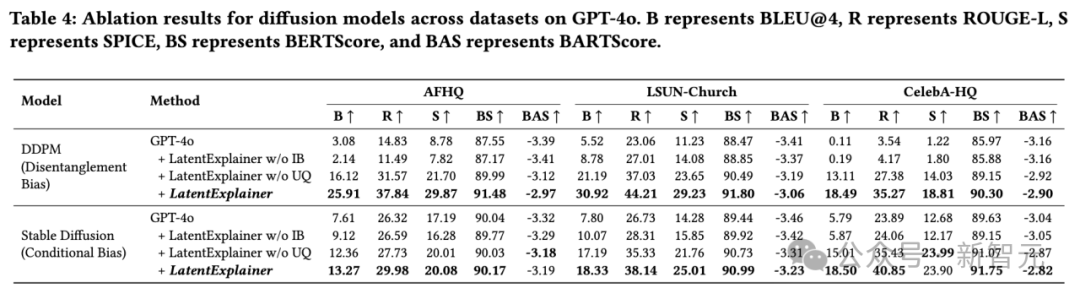
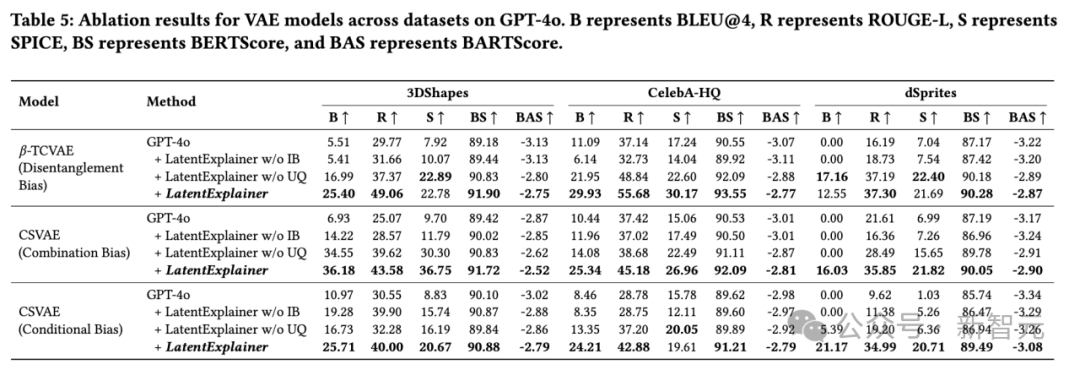
消融实验证明核心价值: 移除「归纳偏置提示」或「不确定性量化」组件后,性能都会出现明显下降,尤其是移除归纳偏置提示,性能损失巨大。这充分证明了这两个设计是LatentExplainer成功的关键。
总结与展望
LatentExplainer的核心突破,在于它不再让大模型「凭空猜测」,而是将生成模型自身的归纳偏置转化为大模型能听懂的「操作指令」。
通过「数据扰动+智能提示+不确定性评估」三步走,它成功地为VAE、Diffusion等模型的潜变量生成了准确、可信的人类可读解释,性能提升近2倍。
LatentExplainer为打开生成模型的「黑箱」提供了一把强有力的钥匙,让模型不仅会生成,更能解释与对齐,为未来构建更透明、更可控、更值得信赖的生成式AI系统奠定了坚实基础。


