今天凌晨,知名开源平台Black Forest开源了,文生图模型FLUX.1-Kontext的开发者版本。
该版本主要专注于图像编辑任务,支持迭代编辑,在各种场景和环境中都能出色地保留角色特征,还允许进行精确的局部和全局编辑,例如,用户想给一个人脸加上胡子或者更改衣服穿着、场景,FLUX.1-Kontext都能轻松实现。

简单来说,FLUX.1-Kontext开发版的主要功能可以像PS一样,让用户通过自然语言就能实现一键P图。
开源地址:https://huggingface.co/black-forest-labs/FLUX.1-Kontext-dev
Github:https://github.com/black-forest-labs/flux
根据Black Forest公布的测试数据显示,FLUX.1-Kontext开发版在人类偏好评估、指令编辑、文本插入与编辑、样式参考等评估基准中,超过了OpenAI发布的最新文生图模型GPT-image-1,成为目前最强开源文生图模型之一。

FLUX.1-Kontext是在Black Forest之前开源的爆火模型FLUX.1基础之上开发而成。FLUX.1 Kontext 采用了基于流匹配的生成模型架构,其基础是在图像自动编码器的潜在空间中运行的整流Transformer。
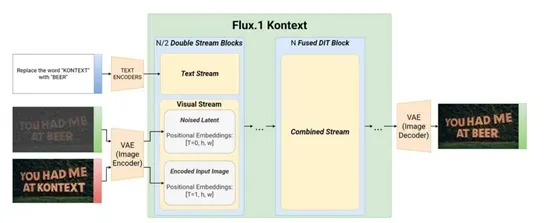
图像会被冻结的FLUX自动编码器编码为潜在 tokens,这些上下文图像 tokens 会被附加到目标图像 tokens 上,再送入模型的视觉流。这种序列连接策略有两个显著优势,一是能够支持不同输入 / 输出分辨率和宽高比,二是可以轻松扩展到多个上下文图像的场景。
为了区分上下文和目标内容,模型通过三维旋转位置嵌入来编码位置信息,为上下文 tokens 设置恒定的时间偏移,使上下文和目标块在保持内部空间结构的同时被清晰分离。
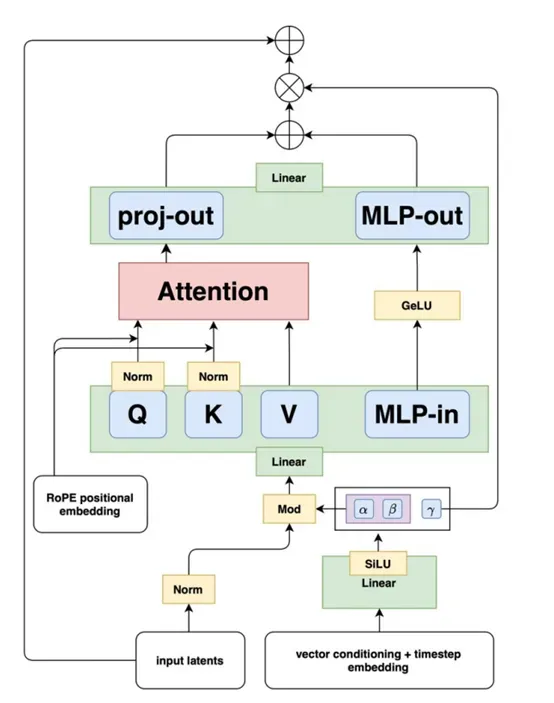
FLUX.1-Kontext的训练是基于整流流匹配损失函数,其核心目标是预测噪声速度以匹配潜在空间中的噪声分布。训练过程中会在干净图像和噪声之间进行线性插值得到混合潜在表示,模型需要学习预测从该混合表示到噪声的速度向量。
这种训练方式使得模型能够同时处理上下文编辑和文本到图像的生成任务当上下文图像存在时,模型执行图像驱动的编辑;当上下文图像不存在时,则从零开始生成新内容。为了提升训练效率和采样速度,模型引入了潜在对抗扩散蒸馏技术,通过对抗训练减少采样步骤,在保证样本质量的同时,将1024×1024 图像的生成时间压缩至 3-5 秒。
在训练阶段,模型基于数百万的关系对进行优化,无需针对不同任务进行参数调整或微调。这种设计使其能够无缝处理局部编辑、全局编辑、角色参考、风格参考和文本编辑等任务。例如,在局部编辑中,模型可以修改汽车颜色而保持背景不变;
在风格参考任务中,它能提取参考图像的艺术风格并应用于新场景。特别值得一提的是,模型在多轮编辑中的角色一致性表现突出,通过 AuraFace 面部嵌入的余弦相似度计算可以看出,其在连续编辑中的视觉漂移明显低于竞争对手,这对于品牌形象维护、故事板生成等需要长期一致性的场景至关重要。

为了实现快速推理,模型在工程层面进行了多项优化。在硬件利用方面,Black Forest与英伟达进行技术合作,专为新的NVIDIA Blackwell 架构设计了优化的 TensorRT 权重,极大提高了推理速度并降低了内存使用量,同时保持了高质量的图像编辑性能。
同时使用 Flash Attention 3 和 Transformer 块的区域编译来提高吞吐量。在训练策略上,结合混合精度训练和选择性激活检查点技术,降低显存占用,支持更大规模的模型训练。这些优化使得FLUX.1 Kontext在保持生成质量的同时,实现了比 GPT-Image-1 等模型快一个数量级的推理速度。


