应用

ICLR 2024 Spotlight | 无惧中间步骤,MUSTARD可生成高质量数学推理数据
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]。近年来,大型语言模型(LLM)在数学应用题和数学定理证明等任务中取得了长足的进步。数学推理需要严格的、形式化的多步推理过程,因此是 LLMs 推理能力进步的关键里程碑, 但仍然面临着重要

AI 赛道火爆背后,大厂工程师吐槽:公司为求快而牺牲准确性等
OpenAI 于 2022 年 11 月发布 ChatGPT-3 以来,AI 赛道就吸引了科技巨头、资本、媒体、用户的广泛关注。CNBC 最新报道聚焦将这些大语言模型搬上舞台的软件工程师,但他们更多的情绪主题是压力、无奈、无力。科技巨头都想要在 AI 赛道上抢占先发优势,因此敦促旗下的工程团队不断迭代和发布新的 AI 产品。微软一位不愿透露姓名的工程师表示,该公司正在展开一场“人工智能激烈的竞赛”,他还声称,微软优先考虑的是发布人工智能产品的速度,而不是道德和安全问题。IT之家援引该媒体报道,一位亚马逊 AI 工程
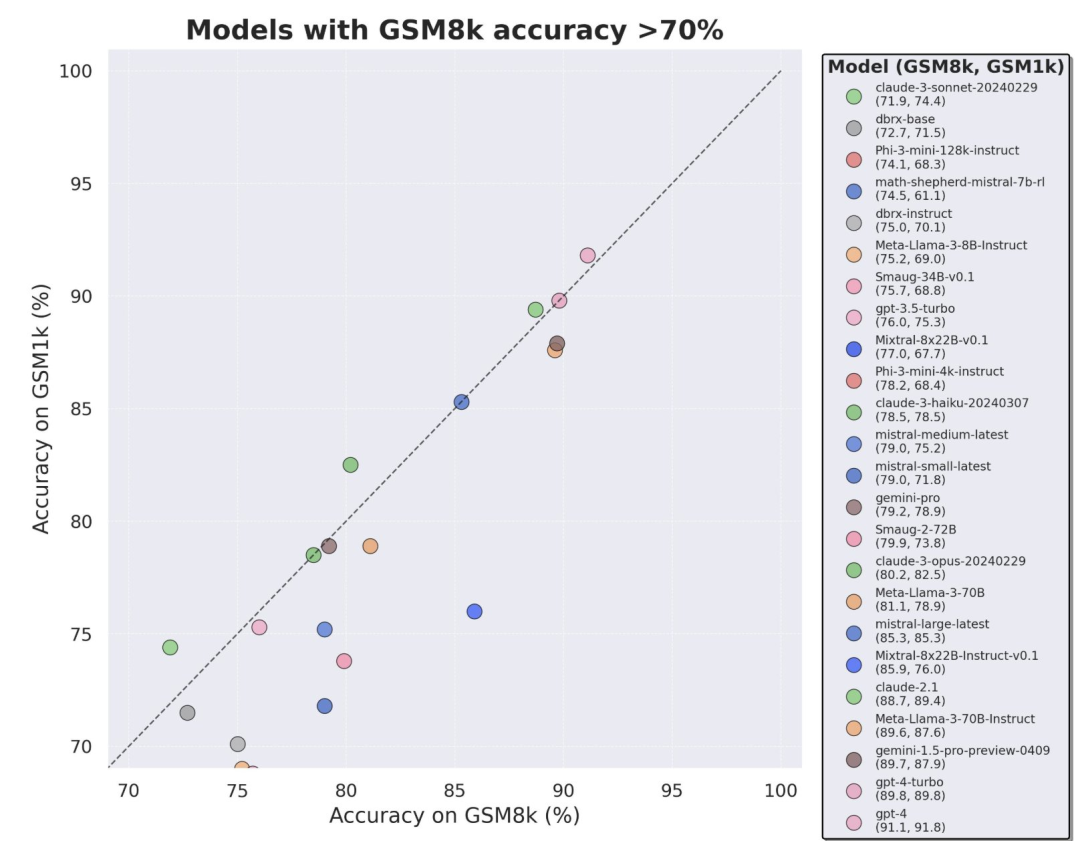
终于有人调查了小模型过拟合:三分之二都有数据污染,微软Phi-3、Mixtral 8x22B被点名
当前最火的大模型,竟然三分之二都存在过拟合问题?刚刚出炉的一项研究,让领域内的许多研究者有点意外。提高大型语言模型的推理能力是当前研究的最重要方向之一,而在这类任务中,近期发布的很多小模型看起来表现不错,比如微软 Phi-3、Mistral 8x22B 等等。但随后,研究者们指出当前大模型研究领域存在一个关键问题:很多研究未能正确地对现有 LLM 的能力进行基准测试。这是因为目前的大多数研究都采用 GSM8k、MATH、MBPP、HumanEval、SWEBench 等测试集作为基准。由于模型是基于从互联网抓取的大

2023 IBM博士生奖学金华人占六成:Vicuna作者吴章昊、清华特奖得主高天宇入选
近日,2023 年 IBM 博士生奖学金计划名单公布。自 1951 年以来,IBM 通过极具竞争力的博士生奖学金(IBM PhD Fellowship Award)计划认可并表彰了来自全球各地的优秀博士生。2023 年,IBM 博士生奖学金计划收到了来自 14 个国家 59 所大学的数百份申请。最终,共有 10 位年轻学者获得本年度博士生奖学金,包括人工智能、混合云技术、量子计算、负责任及包容性技术等前沿研究领域的青年翘楚。特别值得注意的是,其中有六位都是华人。下图为 10 位获奖博士生的完整名单和院校信息:此外,

AIGC实战案例!6组高质量的末日堡垒主题 Midjourney 提示词
今天给大家分享一组 AI 生成作品,主题为末日堡垒,并附上相应的提示词供大家参考。这组作品的灵感,来源于乔纳森·诺兰近期执导由经典游戏改编的佳作《辐射》。在这部作品中,讲述了辐射避难所的居民们因种种原因被迫重返地面的故事,那种在末日废墟中挣扎求生的场景,令人震撼又感慨万分。基于这样的灵感,我们萌生了创作一组“末日堡垒”主题 AI 图片的想法,希望大家喜欢。
当然,我们所展示的风格仅仅是 Midjourney 冰山一角,它能够演绎出千变万化的风格,满足你的各种创意需求,感兴趣的童鞋可以大胆去尝试不一样的风格,相信你会

面壁智能发布 Eurux-8x22B 开源大模型:代码性能超越 Llama3-70B
感谢面壁智能发布开源大模型 Eurux-8x22B,包括 Eurux-8x22B-NCA 与 Eurux-8x22B-KTO,主打推理能力。官方测试中,Eurux-8x22B 在 LeetCode(180 道 LeetCode 编程真题)与 TheoremQA (IT之家注:美国大学水准的 STEM 题目)测试上超越了 Llama3-70B,在 LeetCode 测试上超越闭源的 GPT-3.5-Turbo。▲ 官方测试结果据介绍,Eurux-8x22B 模型激活参数 39B,支持 64k 上下文,是由 Mixtr

AI 入侵华尔街,高盛、摩根大通:66% 初级分析师有被取代风险
【新智元导读】AI 的威力开始在银行业显现!据说,金融分析软件苏格拉底入驻华尔街,三分之二初级分析师将不再需要。AI 又把「魔爪」伸向了一波打工人,而且这次还是一波高级打工人。有银行内部的专业人士表示,即将上任的华尔街初级分析师就有着被人工智能抢走饭碗的风险。高盛、摩根斯坦利和其它几家大银行的内部人士都有此论断。华尔街这个地方,紧紧抓住了时代潮流,开始思考人工智能有没有可能性横插一脚,少招点人。目前,多家大公司都在考虑减少新分析师的招聘工作。降本增效?缩减多少呢?目前预期的数字是三分之二。也就是说,超过一半的岗位都

Transformer要变Kansformer?用了几十年的MLP迎来挑战者KAN
MLP(多层感知器)用了几十年了,真的没有别的选择了吗?多层感知器(MLP),也被称为全连接前馈神经网络,是当今深度学习模型的基础构建块。MLP 的重要性无论怎样强调都不为过,因为它们是机器学习中用于逼近非线性函数的默认方法。然而,MLP 是否就是我们能够构建的最佳非线性回归器呢?尽管 MLP 被广泛使用,但它们存在明显的缺陷。例如,在 Transformer 模型中,MLP 几乎消耗了所有非嵌入式参数,并且通常在没有后处理分析工具的情况下,相对于注意力层来说,它们的可解释性较差。所以,是否有一种 MLP 的替代选

邮件曝光,微软为追谷歌脚步才投资了OpenAI,纳德拉回应:才不是
微软与 OpenAI 剪不断理还乱。微软与 OpenAI 之间的关系紧密而复杂。在 OpenAI CEO Sam Altman 陷入辞退的风波时,微软 CEO 纳德拉曾多次力挺他,并向他抛出橄榄枝。当这场 OpenAI「宫斗」过去后,纳德拉也表示,无论 Altman 身在何处,仍然会支持他。前不久还有微软的员工狂吐苦水,「微软已经沦落为 OpenAI 的一个 IT 部门!」资源倾斜不仅导致员工不满,还有不少高管相继离职。不难看出,微软为了在 AI 赛道中站稳脚跟,对 OpenAI 多有依赖。这份依赖不仅源于 Ope

挑战谷歌巨头地位?消息称 OpenAI 于 5 月 9 日发布 ChatGPT 版搜索引擎
谷歌 Gemini 和微软 Copilot 之间的 AI 大战继续升级,最新消息称 OpenAI 有望今年 5 月 9 日推出基于 ChatGPT 的全新搜索产品,进一步挑战谷歌的传统搜索巨头地位。Reddit 网友近日发帖,表示 search.chatgpt.com 域名和相关的 SSL 证书已经被创建,网友 @nonmayorpete 发布推文称该域名将于 5 月 9 日上线。IT之家现在访问该域名,跳出的结果是“Not found”信息,而不是 404 或者域名错误,进一步间接证明了上述猜测。OpenAI 首

“放飞吧”新品发布会临近,消息称苹果 CEO 库克将同时预告全新 AI 功能
感谢《华盛顿邮报》今晚报道称,为重振消费者热情,苹果 CEO 库克预计下周预告新的人工智能功能,并于 6 月的全球开发者大会上公布。具体来看,库克将在下周的“放飞吧”(Let Loose)活动中对 AI 功能进行预热。根据官方消息,苹果将于 5 月 7 日晚上 10 点举办这场特别活动。从海报来看,此次活动预计将重点关注新一代 iPad 硬件和配件,例如大家期待已久的 iPad Pro 和 Apple Pencil 等。苹果 WWDC 大会将于 2024 年 6 月 11 日至 15 日举行。业界猜测,苹果届时可能

AIGC实战案例!教你一键生成毛绒绒的图标
一键生成毛绒绒 ICON 工作流来啦!只需要输入对应的 logo 和颜色提示词,即可生成毛绒绒效果的 ICON 图标!
ㅤ
「注意事项」:
基本上所有参数都设置好,不需要大幅更改,如果觉得效果不够理想,可以从 lora 权重下手修改看看。如果图标拥有三种颜色或以上的时候,则需要各自生成一张图,再到 PS 做融合处理。

ChatGPT 新增临时聊天功能,对话不留痕
OpenAI 近日连续发布更新,为 ChatGPT 免费和 Plus 用户带来更多数据控制功能。此次更新赋予用户更多对话历史记录的管理权限,并新增了“临时聊天”功能。此前,选择不贡献对话数据以训练模型的用户无法访问自己的聊天历史记录。最新更新取消了这一限制,无论用户是否选择贡献数据,现在都可以访问聊天历史,回顾过去与 ChatGPT 的互动。OpenAI 同时保证,用户此前做出的不贡献数据的选择依然有效。本次更新目前已在 ChatGPT 网页版上线,移动端版本即将推出。IT之家注意到,为满足用户对隐私的进一步需求,
英伟达 ChatRTX 聊天机器人迎 0.3 版本更新:新增照片搜索、AI 语音识别等功能
英伟达旗下聊天机器人 ChatRTX 今日发布了 0.3 版本更新,带来了包括照片搜索、AI 驱动的语音识别等一系列新增功能。同时,ChatRTX 扩充了自身支持的大语言模型种类,例如谷歌新推出的本地模型 Gemma、ChatGLM3-6B 等。与此同时,由于借鉴了 OpenAI 旗下 CLIP 工具的技术(IT之家注:该技术可识别在图像集合中“所见”的内容),ChatRTX 现在能够对图片进行搜索;而得益于对 AI 语音识别系统 Whisper 的支持,ChatRTX 现在可以理解用户口头说出的语音指令。据介绍,

面壁新模型:早于Llama3、比肩 Llama3、推理超越 Llama3!
图注:面壁Eurux-8x22B 模型在 LeetCode 和 TheoremQA这两个具有挑战性的基准测试中,刷新开源大模型推理性能 SOTA。 图注:面壁Eurux-8x22B 模型综合性能比肩 LlaMa3-70B,超越开源模型 WizardLM-2-8x22b, Mistral-8x22b-Instruct,DeepSeek-67b,以及闭源模型 GPT-3.5-turbo。 Eurux-8x22B 由 Mistral-8x22B对齐而来。

口袋 AI 设备 Rabbit R1 本质上只是“套壳”安卓?官方否认
当地时间 30 日,外媒 Android Authority 的记者 Mishaal Rahman 声称,此前在 CES 2024 上引起各界关注的口袋 AI 设备 Rabbit R1 实质上只是“套壳”安卓 App。该报道引述一名姓名未公开的爆料者的说法,经过实测发现,据称是“Rabbit R1 内置启动器”的应用可被安装到 Pixel 6a 智能手机上,手机上的音量加键可以与 Rabbit R1 的功能键相对应,用户也可以直接通过设置向导创建账号、与 AI 助手对话。不过,由于 Rabbit R1 的显示屏远小

余承东卸任华为终端BG CEO,何刚将接任
据多家媒体报道,华为于 4 月 30 日下午内部发布人事调整文件,宣布余承东将卸任华为终端 BG CEO 一职。余承东将仍保留终端 BG 董事长职位。原华为终端 BG、首席运营官何刚将接任华为终端 BG CEO。据透露,除了上述人事变动调整外,该文件并无更多信息。关于这次重大人事变动的背景和余承东卸任终端 BG CEO 之后新的业务重心,也未有进一步的说明。有消息源表示,此次调整属于常规的业务架构调整,可让余承东有更多精力为消费者打造精品。余承东出生于 1969 年,本科毕业于西北工业大学自动控制系,硕士毕业于清华

未经许可重复使用原创文章训练模型,OpenAI 遭美国 8 家报纸出版商起诉
感谢据 CNBC 报道,当地时间 4 月 30 日,8 家美国报纸出版商在纽约的一家联邦法院对微软、OpenAI 提起诉讼,声称后者未经许可在生成式 AI 产品中重复使用这些出版商创作的文章,还将信息的不准确性归咎于出版商本身。图源 Pixabay根据 8 家出版商向美国纽约南区地方法院提交的诉状,ChatGPT 一直在“未经许可、未付款”的情况下,盗用了出版商数百万篇受版权保护的文章。IT之家查询发现,参与诉讼的出版商包括《纽约每日新闻》《芝加哥论坛报》《奥兰多哨兵报》《佛罗里达太阳哨兵报》《圣何塞水星报》《丹佛
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉