应用

Midjourney 的 Style Raw 模式到底怎么用? 一篇文章帮你弄懂!
大家好,这里是和你们一起探索 AI 的花生~
与 stylize、chaos 一样,style raw 也是 Midjourney 出图中常用的的参数之一,可以帮我们实现特定的出图需求,但肯定有很多小伙伴依旧对它的具体作用不太了解,今天就通过这篇文章,详细为大家讲解一下 style raw 的适用场景和使用方法。
上期回顾:一、Style Raw 简介
之前我们提到过,Midjourney 的默认模型( v5.2、v6 等)是自带 “美学滤镜” 的,它们在生成图像时会进行一定的风格化处理,让画面更有艺术性、更好看。
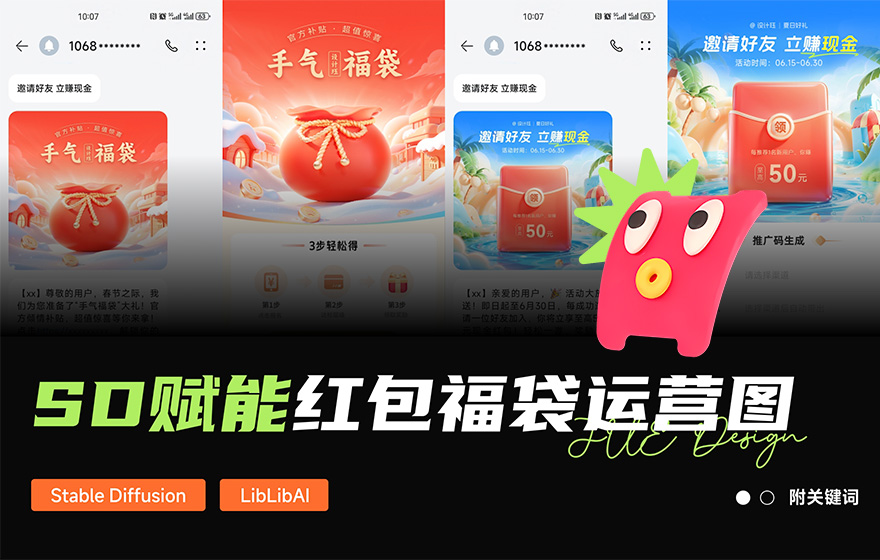
AIGC实战!如何快速完成红包/福袋相关的营销设计?
本文核心在于揭示 AIGC 如何赋能以红包、福袋为主体的运营设计,通过实战案例剖析,解锁新颖设计策略。示例中 H5 页面的下半部分引用了其他 App 界面,特此声明仅作学习之用,无商业目的。前言
在广泛的设计应用场景中,红包、福袋作为标志性元素,频繁现身于银行理财推广、电商促销活动、会员权益彰显等场合,巧妙激活场景氛围。直接步入正题,满满的设计思路全部奉上,评论区虚位以待,诚邀您分享独到观点。
一、红包为主体
1. ControlNet识别形状
绘制红包,确保位置恰当,保存图像。上传至 ControlNet,选 C

清华大学苏世民书院院长薛澜:AI 可能带来多方面风险,误用 / 滥用等问题不可忽视
综合财联社、上证报报道,在今日上午举行的 2024 世界人工智能大会暨人工智能全球治理高级别会议开幕式全体会议上,清华大学苏世民书院院长、人工智能国际治理研究院院长薛澜表示,从全球视角看,AI 的发展面临基础设施不均衡、数字素养存在鸿沟等挑战,这些问题不仅阻碍人工智能产业发展,也影响人工智能全球治理,必须全球共同解决。薛澜表示,目前 AI 可能带来一些风险。技术内在问题,包括所谓“幻觉”。从自主 AI 系统的长远发展来看,可能对人类社会构成的威胁;基于技术开发带来的风险,包括数据安全问题、算法歧视、能源环境等问题;

日本大阪将在多座车站部署实时语音识别系统:透明显示屏形态,支持 23 种语言翻译
据日媒 ROBOSTART 报道,JR 西日本和阪急电铁将于 7 月 12 日至 9 月 13 日在 JR 大阪站、阪急大阪梅田站部署新型实时语音识别系统 YYSystem 进行乘客引导示范测试。据悉,该系统可借助 AI 将对话实时翻译成多种语言,日语和目标语言都将即时显示在一块配有定向麦克风的透明显示屏上。IT之家获悉,该系统支持 23 种语言,有望为入境旅客或听障人士提供更加顺畅的服务。此次测试将会对所获得数据进行分析,以验证其是否可以对车站信息中常用的词语或表达方式作出响应,目标是在明年的大阪-关西世博会开幕

国产大模型群雄逐“沪”,讯飞星火如何闪耀WAIC?
7月4日,2024世界人工智能大会暨人工智能全球治理高级别会议(简称“WAIC 2024”)在上海世博中心开幕,WAIC 2024作为全球最高规格的AI产业盛会,今年共有500多家企业参展,汇聚了超1500件展品,大模型成为本届大会的“重头戏”,国内主流大模型齐聚上海滩,既包括科大讯飞星火、百度文心一言、阿里通义、腾讯元宝、华为盘古等市场热门产品,又囊括百川智能、智谱AI、Minimax、阶跃星辰等新锐实力。从今年WAIC 2024展会可以看出,大模型产业逐步由虚向实、锚定场景、深耕行业,不断发挥赋能价值。本次是讯

杉数科技重磅发布智能建模与计算新品,开启人工智能应用新篇章
7月3日,由全球数字经济大会组委会、北京市经济和信息化局、北京市朝阳区人民政府、杉数科技共同举办的“智能计算与决策技术论坛”在北京圆满落幕。论坛以“创新智能计算引擎 打造企业芯智生产力”为主题,邀请了政府相关领导、国际知名学者、高校教授、企业技术专家、投资机构等学术与产业界精英齐聚一堂,共话智能计算与决策技术前沿和产业创新,探讨如何以人工智能技术加快推进现代化产业体系建设,推动数字经济和实体经济深度融合,为我国经济高质量发展贡献力量。 大会现场

商汤科技 CEO 徐立:AI 行业很热但未到“超级时刻”,需要应用来支撑
在今日开幕的 2024 世界人工智能大会期间,商汤科技董事长兼 CEO 徐立发表演讲。徐立在演讲指出,当前 AI 行业确实很热,但“还没有到一个超级时刻”—— 因为 AI 暂未真正走进行业垂直应用,或引起广泛变化。徐立认为,当下的大模型只是一个“记忆器”,只是背下了所有的知识点,仅有的一点点智能其实是来自互联网上的数据背后带有的一个“高阶逻辑思维链”。徐立在谈到“超级时刻”时补充说,超级时刻和应用是相互成就的。“超级时刻”带来认知变化,才能推动应用。如果有应用来支撑,那么当下就是“超级时刻”。“就像 iPhone

8月正式发布,小鹏MONA M03开启全球首秀
量化之美,破风而来。7月3日下午14点,小鹏MONA M03开启全球首秀。这款为年轻用户打造的智能纯电掀背轿跑,以其独特的AI量化美学设计吸引了行业关注。小鹏汽车董事长CEO何小鹏携手造型中心副总裁胡安马·洛佩兹(JuanMa Lopez)共同出席了此次直播,深入解读了小鹏MONA M03的设计创作理念和背后的技术实力。AI量化美学设计 为年轻而来作为MONA系列的首款车型,小鹏MONA M03承载了小鹏汽车对于电动市场和用户需求的全新思考。当下,20万内的汽车市场占据了行业近乎一半的市场份额,中规中矩的A级轿车已

首个开源、原生多模态生成大模型:一键生成 「煎鸡蛋」图文菜谱
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]生成式人工智能研究实验室(GAIR,主页:)由上海交通大学刘鹏飞副教授2023年4月回国创建,是国内首个聚焦于生成式人工智能的高校研究组。汇聚了来自于CMU、复旦、交大(ACM班、IEEE

揭秘:阶跃星辰万亿MoE+多模态大模型矩阵亮相
在 2024 年世界人工智能大会的现场,很多人在一个展台前排队,只为让 AI 大模型给自己在天庭「安排」一个差事。具体流程是这样的:首先, AI 会管你要一张个人照片,并参考《大闹天宫》画风生成你在仙界的形象照。接下来,它会引导你进入一个交互式的剧情选择和交谈环节(其实是 AI 大模型自己编的剧情),然后根据你的选择和回答评估出你的 MBTI 人格类型,并根据这个类型为你在天庭「安排」一个差事。 当然,除了现场排队,你还可以在线体验(扫描下方二维码即可)。这是大模型创业公司阶跃星辰与上影合作的 AI 互动体验《AI

AI主战场,万卡是标配:国产GPU万卡万P集群来了!
Scaling Law 持续见效,让算力就快跟不上大模型的膨胀速度了。「规模越大、算力越高、效果越好」成为行业圭皋。主流大模型从百亿跨越到 1.8 万亿参数只用了1年,META、Google、微软这些巨头也从 2022 年起就在搭建 15000 卡以上的超大集群。「万卡已然成为 AI 主战场的标配。」然而在国内,全国产化的 GPU 万卡集群,则是屈指可数。有超大规模,同时还具备超强通用性的万卡集群,更是行业空白。当国产 GPU 万卡万 P 集群首次亮相时,自然就引发了行业广泛关注。7 月 3 日,摩尔线程在上海重磅
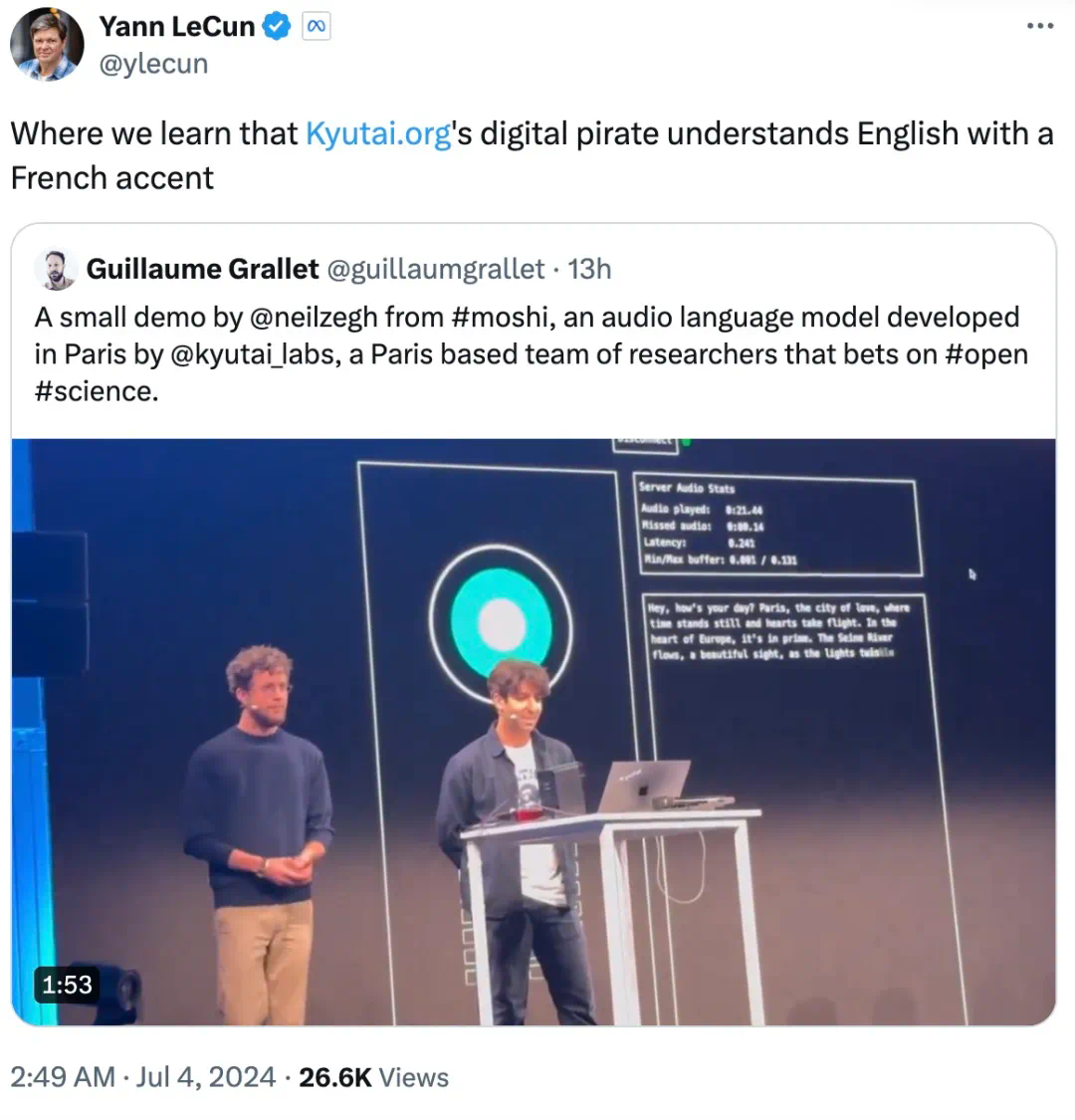
8人小团队单挑OpenAI,半年仿出GPT-4o,还开源了
最近,一个对标 GPT-4o 的开源实时语音多模态模型火了。这个开源模型来自法国一个仅有 8 人的非营利性 AI 研究机构 ——Kyutai,模型名为 Moshi,具备听、说、看的多模态功能。图灵奖得主 Yann LeCun 转发说道:「Moshi 能听懂带有法国口音的英语。」据悉,该团队开发这个模型仅用了 6 个月。的确,在研究团队演示的视频中,我们发现 Moshi 可以非常流利地回答人们提出的问题,进行日常对话交流,甚至可以猜出提问者的意图。例如,当提问者说「下个月打算去攀登珠穆朗玛峰,我在想......」,提

AI 搜索热潮背后:注定要逾越场景的门槛
在 2024 上半年并算不明朗的 AI 应用局势中,AI 搜索正成为新共识并迎来了一波热潮,短时间内涌现出了多个 AI 搜索产品。 其中,国外原生 AI 搜索工具 Perplexity AI 最新估值已经接近30 亿美元、GenSpark、You 均表现不俗;国内天工 AI 、秘塔搜索等也在打磨自身产品力。 AI 搜索不仅在产品形态上革新了传统搜索引擎的信息罗列模式以及备受诟病的竞价排名广告,还能解决聊天机器人信息滞后和幻觉问题,让传统搜索引擎的交互变得更加智能。
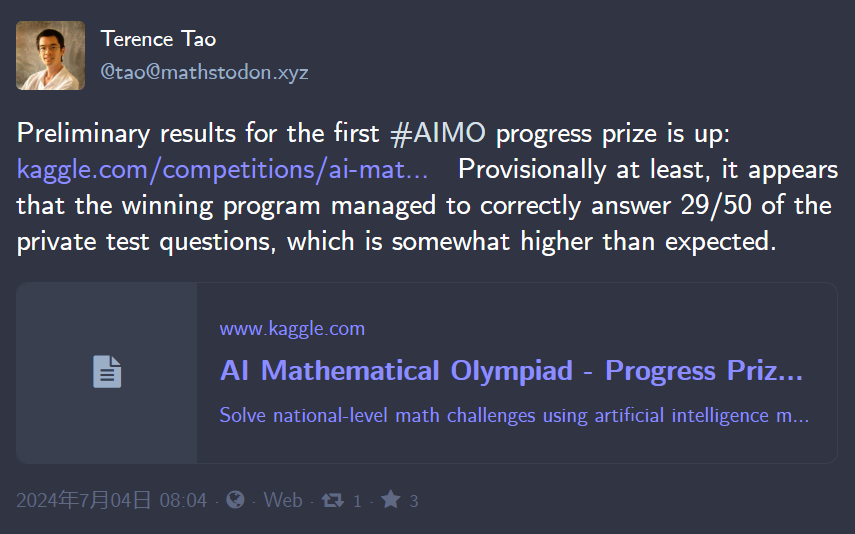
陶哲轩支持!AI数学奥林匹克竞赛进步奖公布,奖金100多万美元
大模型做数学题到底如何,不妨让它参与一下这种级别的比赛。 「AI 数学奥林匹克竞赛(AIMO 进步奖)的初步成绩已公布。根据排行榜的数据,目前看来,获胜的程序在私人测试中正确回答了 29/50 道题,这一成绩比预期的要高。」刚刚,陶哲轩在个人博客中公布了这一消息。AIMO 最初由一家搞机器学习量化交易的非银行金融机构 XTX Markets 发起,主要是让参与者使用 AI 模型解决国际数学难题,而本次进步奖的目标是创建能够解决用 LaTeX 格式编写的复杂数学问题的算法和模型。这将有助于推动人工智能模型的数学推理能

全新TextGrad框架:用GPT-4o作引擎,自动优化端到端任务
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]该文章的作者团队来自于斯坦福大学,共同第一作者团队Mert Yuksekgonul,Federico Bianchi, Joseph Boen, Sheng Liu, Zhi HuangM

央视点赞国产AI复活召唤术,兵马俑竟与宝石老舅对唱Rap?
沉睡了两千多年的兵马俑,苏醒了?一句秦腔开场,将我们带到了黄土高原。如果不是亲眼所见,很多观众可能难以想象,有生之年还能看到兵马俑和宝石 Gem 同台对唱《从军行》。「青海长云暗雪山,孤城遥望玉门关。」古调虽存音乐变,声音依旧动人情:这场表演背后的「AI 复活召唤术」,叫做 EMO,来自阿里巴巴通义实验室。仅仅一张照片、一个音频,EMO 就能让静止形象变为惟妙惟肖的唱演视频,且精准卡点音频中的跌宕起伏、抑扬顿挫。在央视《2024 中国・AI 盛典》中,同样基于 EMO 技术,北宋文学家苏轼被「复活」,与李玉刚同台合

一张照片创造 1 分钟人物视频,商汤发布首个“可控”人物视频生成大模型 Vimi
感谢商汤科技在世界人工智能大会(WAIC)上发布了首个“可控”人物视频生成大模型 Vimi,通过一张任意风格的照片就能生成和目标动作一致的人物类视频,并支持多种驱动方式,可通过已有人物视频、动画、声音、文字等多种元素进行驱动。与图片表情控制类技术只能控制头部表情动作不同,商汤称 Vimi 不但可以实现精准的人物表情控制,还可实现在半身区域内控制照片中人物的自然肢体变化,并自动生成与人物相符的头发、服饰及背景变化。同时 Vimi 可稳定生成 1 分钟的单镜头人物类视频,画面效果不会随着时间的变化而劣化或失真,满足娱乐

不到60秒就能生成3D「手办」,Meta发力3D生成,ChatGPT时刻要来了吗?
3D 生成,一直在等待它的「ChatGPT时刻」。一直以来,创作 3D 内容是设计和开发视频游戏、增强现实、虚拟现实以及影视特效中最重要的部分。然而,3D 生成具有独特而艰巨的挑战,这是图像和视频等其他生成内容所不具备的。首先,3D 内容在艺术质量、生成速度、3D 网格结构和拓扑质量、UV 贴图结构以及纹理清晰度和分辨率方面具有严格的标准;其次,与其他研究相比,可用的数据量少。虽然该领域有数十亿张图像和视频可供学习,但可用于训练的 3D 内容数量要少三到四个数量级。因此,现阶段的3D 生成还必须从非 3D 的图像和
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉