最近,小编读了一篇康奈尔大学 (科技校区) 博士生 JACK MORRIS写的博文,发现其对人工智能(AI)的进展解读挺有趣。想分享给读者。
这篇博文的核心意思是:人工智能领域的飞速发展,其核心驱动力并非源于理论的革新,而是对全新数据来源的成功利用。
1. AI进展的表象与现实
作者表示,过去十五年,人工智能取得了令人难以置信的进步,尤其是在最近五年中,这种进步的速度更是惊人。
这种持续的进步给人一种必然会发生的感觉,仿佛是历史的必然趋势。
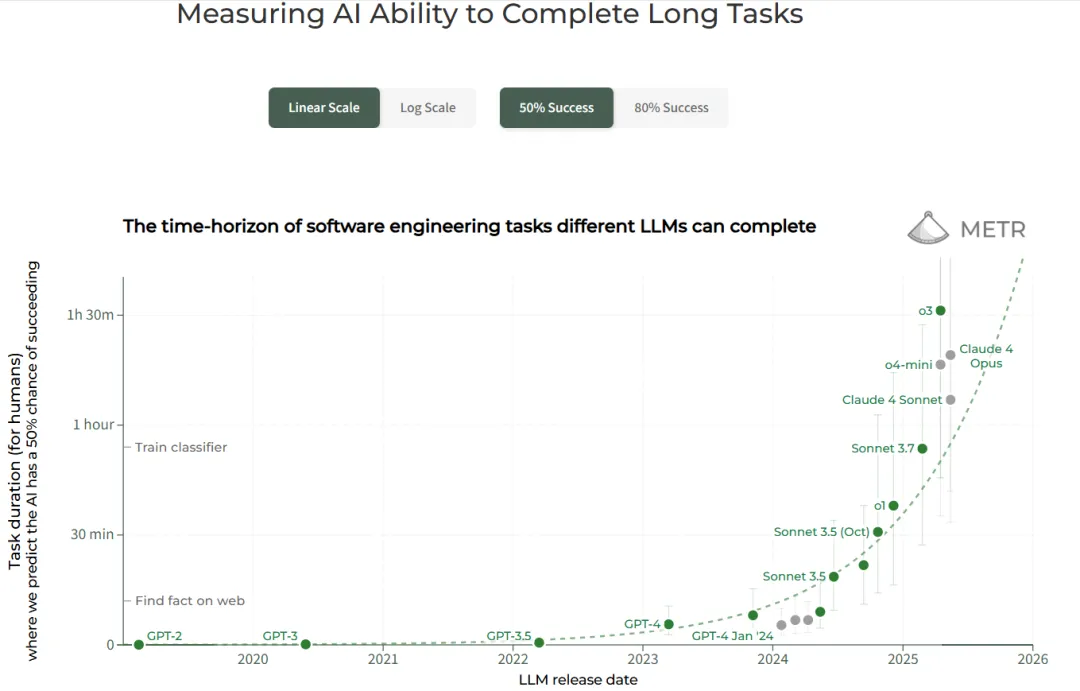
图片来源:https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
部分研究人员甚至据此提出了一个“人工智能领域的摩尔定律”的说法。
该定律指出,计算机在处理特定任务,例如某些类型的编码工作时,其能力会随着时间的推移呈现出指数级的增长。
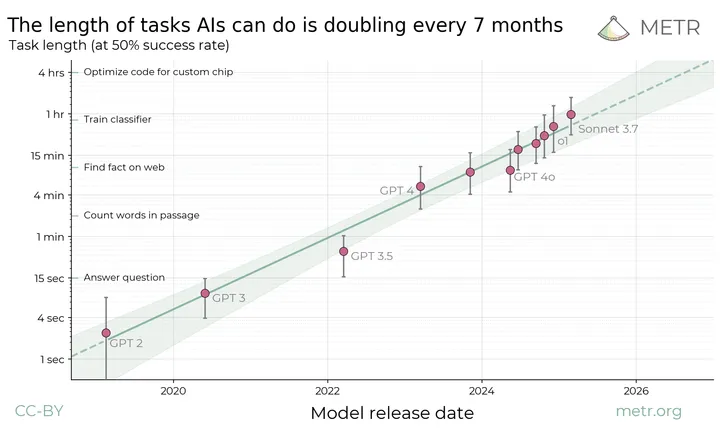
尽管作者并不完全认同这种特定的框架,但无法否认人工智能领域整体向上的发展趋势。
我们的人工智能系统每年都在变得更智能、更快速,同时成本也在不断降低,而且这种进步的势头似乎没有尽头。
大多数人认为,这种持续的进步源于学术界和工业界研究社区源源不断的思想供给。
学术界的代表主要是麻省理工学院、斯坦福大学和卡内基梅隆大学。工业界的贡献则主要来自Meta、谷歌以及少数几家实验室。
当然,还有许多我们永远不会了解到的秘密研究在其他地方同时进行。
2.技术突破与研究动态的回顾
毫无疑问,科学研究确实为我们带来了巨大的进步,尤其是在系统层面。这些系统层面的研究,是模型训练和推理成本能够持续降低的关键所在。
我们可以从过去几年中挑选出几个显著的例子来证明这一点。
2022年,斯坦福大学的研究人员提出了FlashAttention算法。这种方法能够更好地利用语言模型中的内存,现在已经被业界广泛应用。
2023年,谷歌的研究人员开发了推测解码技术。几乎所有的模型供应商都在使用这项技术来加速模型的推理过程。
据信,DeepMind也几乎在同一时间独立开发出了类似的技术。
2024年,一个由互联网爱好者组成的团队开发出了Muon优化器。它似乎是一种比传统SGD或Adam更优秀的优化器,未来可能成为训练语言模型的主流方式。
2025年,DeepSeek 发布了DeepSeek-R1。这个开源模型,其推理能力与来自谷歌和OpenAI的同类闭源模型相当。
这些例子都证明,我们确实在不断地探索和解决问题。现实情况甚至比这更酷,我们正在参与一场去中心化的全球科学实践。
另一方面,研究成果在ArXiv、学术会议和社交媒体上被公开分享,使得我们每个月都在变得更加智慧。
3.人工智能的四个关键范式转移
然而,一个矛盾的问题出现了:既然我们正在进行如此多重要的研究,为什么有些人认为进展正在放缓?
人们的抱怨之声依然不绝于耳,尤其是在模型能力提升方面。最近发布的两个备受瞩目的巨型模型,Grok 3和GPT-4.5,其能力相较于前代产品的提升非常有限。
一个尤其突出的例子是,当最新的语言模型被用于评估解答最新的国际数学奥林匹克竞赛试题时,它们只取得了5%的成绩。
这个结果表明,近期关于系统能力的宣传可能存在过度夸大的成分。如果我们尝试去梳理那些真正具有“重大突破”意义的范式转移,会发现它们的发生频率完全不同。
人工智能的发展历程,可以被四个核心的突破性节点所概括。
第一个突破是深度神经网络(DNNs)的兴起。2012年,AlexNet模型赢得了一场图像识别竞赛,标志着深度神经网络时代的开启。
第二个突破是Transformer架构与大规模语言模型(LLMs)的结合。2017年,谷歌在论文《Attention Is All You Need》中提出了Transformer架构。
这直接催生了2018年谷歌的BERT模型和OpenAI的初代GPT模型。
第三个突破是基于人类反馈的强化学习(RLHF)。据作者所知,这一概念最早由OpenAI在2022年的InstructGPT论文中正式提出。
第四个突破是模型的推理能力。2024年,OpenAI发布了O1模型,这直接启发并催生了后续的DeepSeek R1。
如果你稍微审视一下,就会发现这四个节点(DNNs → Transformer LMs → RLHF → 推理)几乎总结了人工智能领域发生的一切。
我们先是有了深度神经网络,主要用于图像识别系统。然后我们有了文本分类器,接着是聊天机器人。现在我们拥有了所谓的推理模型。
那么,第五次这样的重大突破会来自哪里?研究这四个已有的案例可能会给我们一些启示。
一个不那么疯狂的论点是,所有这些突破性进展的底层机制,在1990年代甚至更早就已经存在。
我们只是在应用相对简单的神经网络架构,并执行监督学习(对应第一和第二个突破)或强化学习(对应第三和第四个突破)。
作为预训练语言模型主要方式的、通过交叉熵进行的监督学习,其思想起源于克劳德·香农在1940年代的工作。
作为后训练语言模型主要方式的、通过RLHF和推理训练进行的强化学习,其历史要稍晚一些。
它可以追溯到1992年策略梯度方法的引入。
这些思想在1998年第一版的Sutton & Barto合著的《强化学习》教科书中就已经相当成熟。
如果我们的思想不是新的,那么新的东西究竟是什么?
这里有一个被忽略的关键环节:这四个突破中的每一个,都使我们能够从一种全新的数据源中学习。
例如,AlexNet及其后续模型解锁了ImageNet数据集。ImageNet是一个大型的、带有类别标签的图像数据库,它驱动了计算机视觉领域长达十五年的发展。
Transformer架构则解锁了对“整个互联网”文本数据的训练。这引发了一场下载、分类和解析万维网上所有文本的竞赛,而这项工作现在似乎已基本完成。
RLHF允许我们从人类的标注中学习什么是“好的文本”。这在很大程度上是一种基于感觉的判断和学习。
而推理能力的突破,似乎让我们能够从“验证器”中学习。这些验证器包括计算器、编译器等,它们可以客观地评估语言模型的输出结果是否正确。
你需要记住,每一个里程碑都标志着相应的数据源(ImageNet、网络文本、人类、验证器)首次被大规模使用。
每个里程碑之后都伴随着一阵狂热的活动。
研究人员竞相从所有可用的渠道中吸收剩余的有用数据。
同时,他们也致力于通过新的技巧来更好地利用已有数据,使系统更高效、数据需求更少。
预计在2025年的后期和2026年,我们将在推理模型中看到同样的趋势。
研究人员将竞相寻找、分类和验证一切可能被验证的东西。
那么,新思想的重要性到底有多大?
有一种观点认为,在这些案例中,我们实际的技术创新可能并没有产生决定性的影响。
我们可以做一个反事实的思考。
如果没有发明AlexNet,也许会有另一种架构出现,同样能够有效处理ImageNet。
如果我们从未发现Transformer,也许我们会满足于使用LSTM或SSM,或者找到其他完全不同的方法来学习网络上的海量文本数据。
这与一些人持有的“数据决定论”不谋而合。
一些研究人员观察到,在所有的训练技术、模型技巧和超参数调整中,真正起决定性作用的,往往是数据的改变。
一个极具说服力的例子是,一些研究人员曾致力于开发一种使用非Transformer架构的新型BERT类模型。
他们花费了大约一年的时间,用数百种不同的方式调整架构,最终成功制造出一种不同类型的模型(状态空间模型“SSM”)。
当这个SSM模型在与原始Transformer相同的数据上进行训练时,它表现出了几乎等同的性能。
这种等效性的发现意义深远。
它暗示了从一个给定的数据集中,我们所能学到的东西存在一个上限。
世界上所有的训练技巧和模型升级,都无法绕过这个冰冷的现实:一个数据集能提供的信息是有限的。

网址:http://www.incompleteideas.net/IncIdeas/BitterLesson.html
也许这种对新思想的冷漠,正是“苦涩的教训(The Bitter Lesson)”想要传达给我们的。
4.未来范式的预期
如果数据是唯一重要的事情,为什么95%的人还在研究新方法?我们下一个范式转移将来自哪里?
一个显而易见的推论是,我们的下一个范式转移不会来自对强化学习的改进,也不会来自某种花哨的新型神经网络。
它将在我们解锁一个以前从未接触过,或者尚未被正确利用的数据源时到来。
一个很多人正在努力驾驭的明显信息来源是视频。
根据网络上的一个随机站点统计,每分钟大约有500小时的视频片段被上传到YouTube。
这是一个惊人数量的数据,远远超过整个互联网上的文本总量。视频也可能是一个更丰富的信息来源。
它不仅包含文字,还包含文字背后的语调,以及无法从文本中收集到的关于物理和文化的丰富信息。
可以肯定地说,一旦我们的模型变得足够高效,或者我们的计算机变得足够强大,谷歌就会开始在YouTube上训练模型。
毕竟,他们拥有这个平台,不利用这些数据来获取优势是愚蠢的。
人工智能下一个“大范式”的另一个有力竞争者,是某种具身化的数据收集系统,用普通人的话说,就是机器人。
我们目前还无法以一种适合在GPU上训练大模型的方式,来收集和处理来自摄像头和传感器的数据。
如果我们能够构建更智能的传感器,或者将计算机的规模扩大到可以轻松处理来自机器人的海量数据涌入,我们或许就能以一种有益的方式利用这些数据。
很难说YouTube、机器人还是其他什么东西会成为人工智能的下一个大事件。
我们现在似乎深深地扎根于语言模型的阵营中,但语言数据似乎也正在被迅速耗尽。
如果我们想在人工智能领域取得进展,也许我们应该停止寻找新思想,而是开始寻找新数据。


