近年来,大语言模型在各类任务上表现出色,但幻觉、逻辑错误、推理漏洞等问题仍屡见不鲜。这促使研究者持续探索提升模型输出可靠性的新路径。现有主流范式各有优势,也存在局限。
有没有可能在不改动原始模型结构和参数的前提下,实现对推理过程的“实时自主监控”?
ICLR 2026一篇投稿论文提出了一个全新思路:单token验证(One-Token Verification,OTV),这是一种测试时扩展的新机制,让模型能“边推理,边判断自己是否推理正确”。

目前主流范式优缺点如下:
- LoRA微调:作为当前主流的参数高效微调手段,虽然无需全参数训练、便于部署,但往往依赖详细的监督数据,且仍会引发“遗忘效应”。
- RLVR(可验证奖励强化学习):仅需结果的程序可验证性即可驱动训练,节省标注成本,但整体流程复杂、计算代价高昂,难以普及。
- 后置验证器:通过对模型已生成结果进行质量筛选,可增强输出可信度,但往往滞后发生,难以及时纠偏模型的思路,且无法窥探模型的内部推理过程。
背景介绍:多线程推理的并行思考
在面对复杂推理任务时,单一路径生成往往难以稳定产出正确答案。为此,研究者们近年来提出了并行思考(Parallel Thinking)的推理框架:让语言模型同时生成多条推理路径,再通过一定机制进行甄别筛选。
OTV正是构建在这一并行思考思路之上,但它并未提出多路径生成本身,而是关注如何以更低成本、更高效率从中筛选出正确推理,从而引入“单token验证”这一新范式。
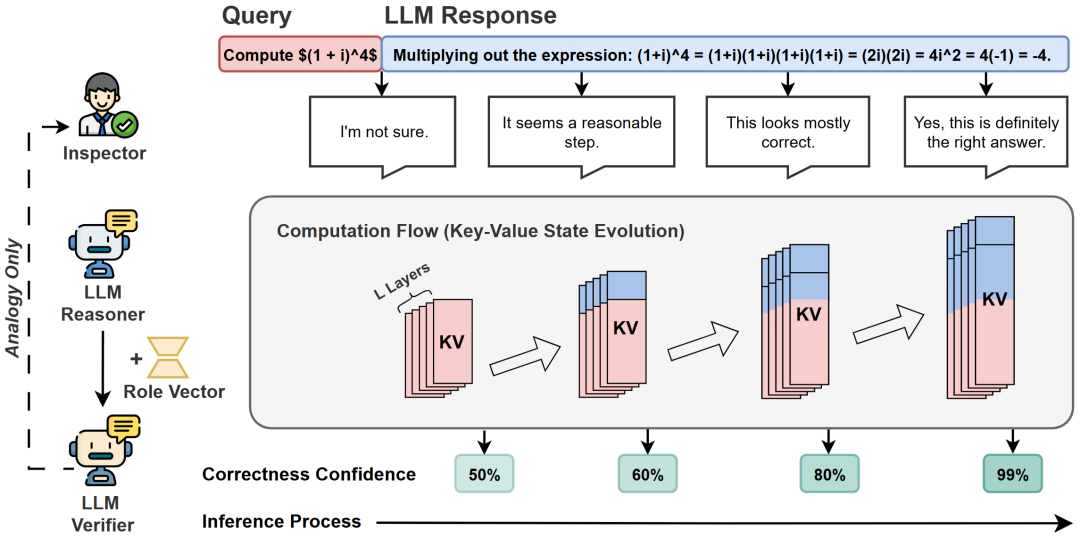
OTV机制核心:内部验证器分析推理过程
为了判断一条推理路径是否靠谱,OTV借助一个由LoRA实现的轻量角色向量作为内部验证器,与原模型并行运行。它并不干扰模型生成内容,而是在“旁观”中做出判断。
这个内部验证器的“洞察力”从何而来?答案藏在Transformer架构的核心组件——键值缓存(KV Cache)。在自回归生成过程中,模型的每一层、每一个token都会生成对应的 Key 和 Value 向量,这些向量被逐步累积并保存在 KV 缓存中。它不仅是模型运行的“中间状态”,更是完整的推理轨迹记录:跨越所有层、整段历史输入,是捕捉模型内部动态最丰富的信息源。
OTV正是利用了键值缓存。在验证阶段,它向输入中插入一个特殊token——被作者称为“ToT”(Token of Truth)。这个token的作用不同于普通生成token:
- 它的Query向量会与此前整个序列的KV缓存进行一次特殊的注意力交互;
- 这意味着它可以“回顾”整条推理路径中每一步的注意力分布与上下文关联;
- 最终它输出一个隐藏状态,传递给一个轻量级的回归头;
- 回归头再给出一个0~1区间内的评分,作为当前推理路径的正确性估计。
整个过程极其高效,因为验证一次仅相当于模型多生成一个token的计算量。
OTV如何训练:轻量结构、简明目标、并行高效
OTV的内部验证器虽然小巧,但其训练逻辑经过了精心设计:
结构上,OTV在插入LoRA角色的基础上,增加一个轻量回归头,直接输出0~1之间的连续值,表示当前推理路径的正确性评分。
训练目标上,OTV以最终答案是否正确为信号,为每个生成token分配启发式伪标签。例如,正确路径的得分从 0.5 线性递增至 1,错误路径则递减至 0,并用均方误差损失作为优化目标。
并行效率上,OTV支持在训练阶段同时计算所有位置的评分预测(原文公式5-7),整体训练流程高度并行,计算成本与传统LoRA微调相当。
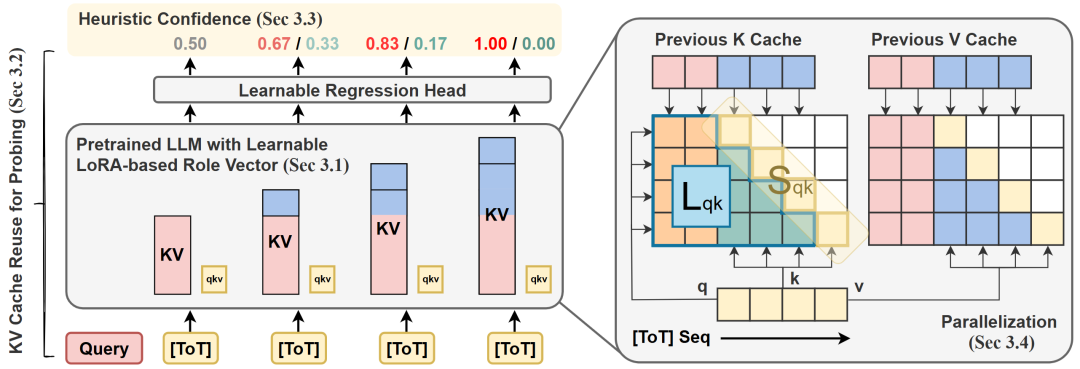
△OTV的算法框架和四个部分示意图。
OTV的实验验证
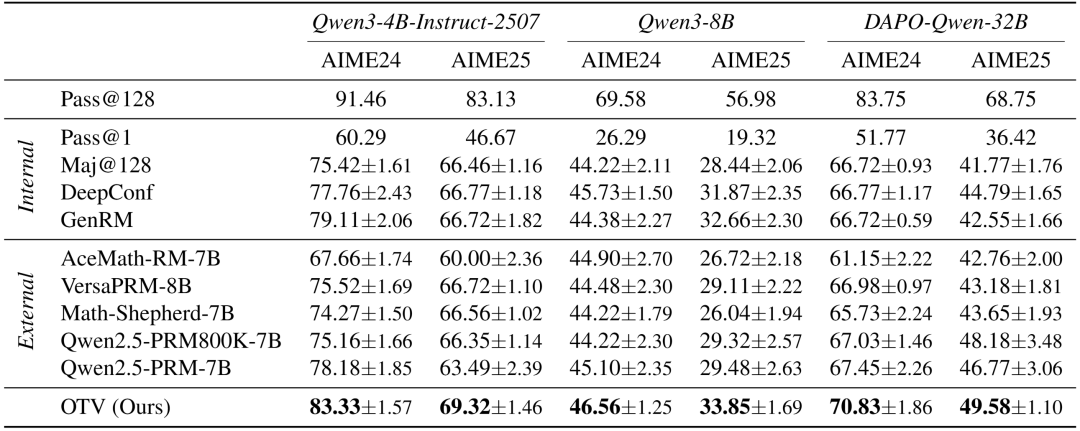
研究团队在多个规模的开源模型(如Qwen3-4B、Qwen3-8B、DAPO-Qwen-32B)上对OTV进行了系统评估,使用开源 DAPO 数据集对验证器进行校准,测试任务则基于高难度数学推理数据集AIME。结果显示,OTV不仅在准确率上全面领先,同时更倾向选择更短、更准确的推理路径。
对比的基线方法涵盖了当前主流的几类思路,包括:
- 基于模型token概率排序的无训练方案(DeepConf);
- 由模型自身生成验证文本的生成式验证器(GenRM);
- 以及一系列外部奖励模型,如 AceMath-RM、VersaPRM、Math-Shepherd 等。
实验表明,OTV作为“模型原生”的验证器,能够直接读取模型内部推理状态与输出质量之间的深层关联,其判断能力显著优于依赖输出文本的通用方法。
在标准的“加权多数投票”设置中,所有候选路径需完整生成并逐一打分,最终选择得分最高者。OTV在不同模型规模下稳定地超越所有基线。同时值得一提的是:即便在已通过 DAPO 数据集强化学习的 DAPO-Qwen-32B 上,OTV仍带来了可观的额外提升。
OTV同时赋予了模型动态控制计算开销的能力。依赖OTV实时输出的置信度分数,模型可以在推理过程中实时淘汰低质量路径,节省不必要的计算。研究者提出多种高效 Best-of-N 变体,例如“HALF 300”策略,即每生成300个 token,就淘汰当前置信度最低的50%路径,最终保留得分最高者。结果显示,与标准的 Best-of-128 策略相比,OTV高效策略在计算量减少近 90%的前提下。仍能保持最优或接近最优的准确率。
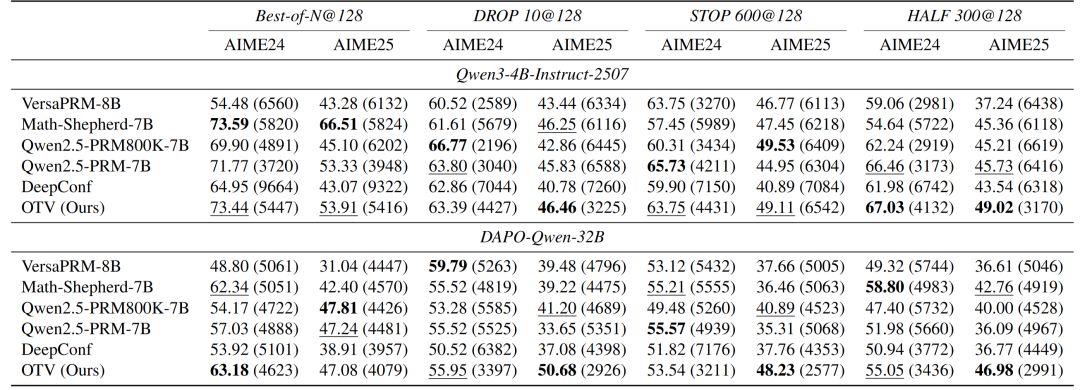
△不同方法在高效推理设置下的准确率与输出长度对比。
更直观的对比来自可视化分析。研究者展示了多个问题下,OTV与其他方法对推理路径的置信度得分评分轨迹。图中红色为最终正确路径,绿色为错误路径。
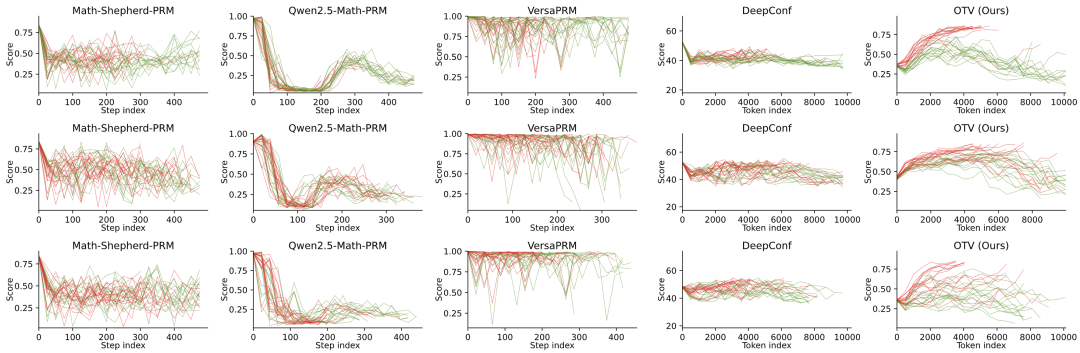
△不同方法在三个问题上多路径的得分变化轨迹。
可以清晰地看到:
- 对于传统方法(如DeepConf或外部过程奖励模型),红绿轨迹往往缠绕混杂,缺乏单调性,无法稳定区分优劣;
- 而在OTV的评分下,红色轨迹稳定上升,呈现出推理逐步走向正确的趋势,而绿色轨迹则通常被压制在低置信区间内。
这一对比直观地说明:OTV捕捉到的信号更稳定、更真实,也更具有区分度,能够反映模型内部推理过程的质量变化,从而为最终决策提供可靠依据。
此外,研究者还进行了多项消融实验,进一步验证了OTV各组件的作用与稳定性,包括仅使用回归头、调整LoRA秩、采用不同启发式监督策略等。即便在更贴近实际微调场景的 Base 模型(未经过后训练)上,OTV依然展现出稳定的性能提升,验证了其方法的通用性与鲁棒性。在附录中,作者还提供了更细粒度的推理可视化分析与文本扰动敏感性评估,为OTV在实际应用中的解释性与稳健性提供了进一步支持。
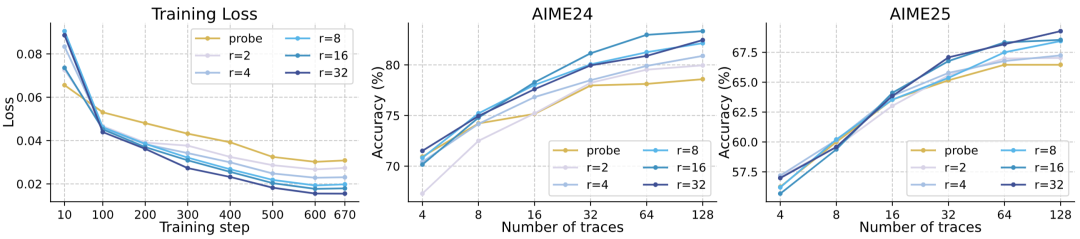
△在仅使用回归头和不同LoRA秩设置下,OTV的训练损失与性能对比分析
总结与展望
这篇论文提出的单Token验证(OTV)框架,通巧妙地重用LoRA和探测KV缓存,为大语言模型的推理质量评估提供了一个极致轻量、实时、无损且模型原生的解决方案。OTV建立在对Transformer架构深刻理解之上的“最小化、靶向性干预”的设计哲学。它向我们揭示了,通往更强大、更可靠AI的道路有时更需要的是深入模型内部,唤醒其“自知之明”的智慧。
展望未来,OTV为后续研究开辟了广阔的空间。一方面,可以探索验证器与原模型更深层次的融合机制,实现推理与评估的协同演化;另一方面,当前基于二元置信度(正确 / 错误)的设计也可扩展为引入“不确定”状态的三元系统,使模型具备选择性预测能力,在面对模糊或低信号任务时学会“谨慎作答”和主动学习。同时,OTV所提供的置信度信号也具备安全控制的潜力:当模型在生成过程中暴露出异常推理模式或高风险倾向时,验证器可实时发出预警,主动终止不安全路径的生成。
此外,未来还可以将OTV思路推广到不同架构的模型中,并结合对KV缓存结构的优化,进一步挖掘其在推理效率与表示利用方面的潜力。研究团队认为,赋予模型“自知之明”的这类探索,将成为推动下一代可信、安全、可控 AI 系统的重要基石。
论文链接:https://openreview.net/pdf?id=QewOtpenMy


