
“ PARSCALE 作为一种新型的语言模型扩展范式,通过增加并行计算次数 P,在保持参数规模几乎不变的情况下,能够显著提升模型的推理能力。”
大家好,我是肆〇柒。今天,我们来聊一项可以改变语言模型性能的技术——PARSCALE(Parallel Scaling)。如果有一种方法,能够在不显著增加模型参数的情况下,大幅提升模型的推理能力,同时还能显著降低推理成本,那将是多么令人兴奋的突破!PARSCALE 正是这样一种技术,它通过并行计算,为大型语言模型(LLM)的扩展提供了一种全新的思路。接下来,让我们一起深入了解 PARSCALE,看看它是如何在保持参数规模几乎不变的情况下,实现性能的飞跃的。
在当下,LLM 的应用场景不断拓展,为我们的生活和工作带来了前所未有的便利。然而,随着模型规模的不断扩大,LLM 在实际应用中也面临着一系列严峻的挑战。
以参数扩展为例,像 DeepSeek-V3 这样的模型,其参数规模已高达 672B,对内存提出了极为苛刻的要求。这种高内存需求使得模型在边缘设备上的部署变得极为困难。想象一下,一台智能手机或智能汽车,其内存资源相对有限,如何能够流畅运行如此庞大的模型?此外,推理时间扩展同样带来了高时间成本。例如,当模型需要生成大量推理 token 时,即使是处理一个简单的数学问题,也可能耗费数秒甚至数十秒的时间。这种延迟对于实时性要求较高的应用场景来说,无疑是致命的。
这些问题严重限制了 LLM 在实际场景中的广泛应用,尤其是在智能手机、智能汽车和机器人等低资源边缘设备上。例如,苹果的 iPhone 14 系列手机,其内存仅为 4GB 至 6GB,而运行一个 672B 参数的模型需要的内存远超此限制。同样,特斯拉的 Autopilot 系统在处理实时驾驶决策时,无法承受高延迟的推理过程。模型的高性能与设备的低资源之间存在着巨大的矛盾,我们需要一种创新的解决方案。
PARSCALE 的价值与创新
在这样的背景下,PARSCALE(Parallel Scaling)应运而生。作为一种全新的语言模型扩展范式,PARSCALE 以其独特的方式,为 LLM 的发展带来了新的希望。
PARSCALE 的核心思想是在保持参数规模几乎不变的情况下,通过增加并行计算来提升模型的推理能力。具体而言,它对输入进行 P 种不同的可学习变换,然后并行地执行模型的前向传播,最后动态聚合这 P 个输出。这种方法不仅能够显著增强模型的推理能力,还能有效降低推理成本。
与传统的参数扩展和推理时间扩展相比,PARSCALE 在推理效率、训练成本和适用场景等方面展现出独特的优势。例如,对于一个 1.6B 参数的模型,当扩展到 P = 8 时,PARSCALE 仅需增加 22 倍的内存,而参数扩展则需要增加 6 倍的内存,并且在推理延迟方面,PARSCALE 也表现出色。这种高效性使得 LLM 在资源受限环境中的部署成为可能,为模型的实际应用开辟了新的道路。
PARSCALE 的优势不仅体现在推理效率和成本上,还在于其对模型泛化能力的潜在提升。通过增加并行流数量 P,模型能够在训练和推理过程中接触到更多样的输入变换和输出聚合方式,这有助于模型学习到更广泛、更鲁棒的特征表示,从而在面对不同领域和风格的数据时表现得更加出色。
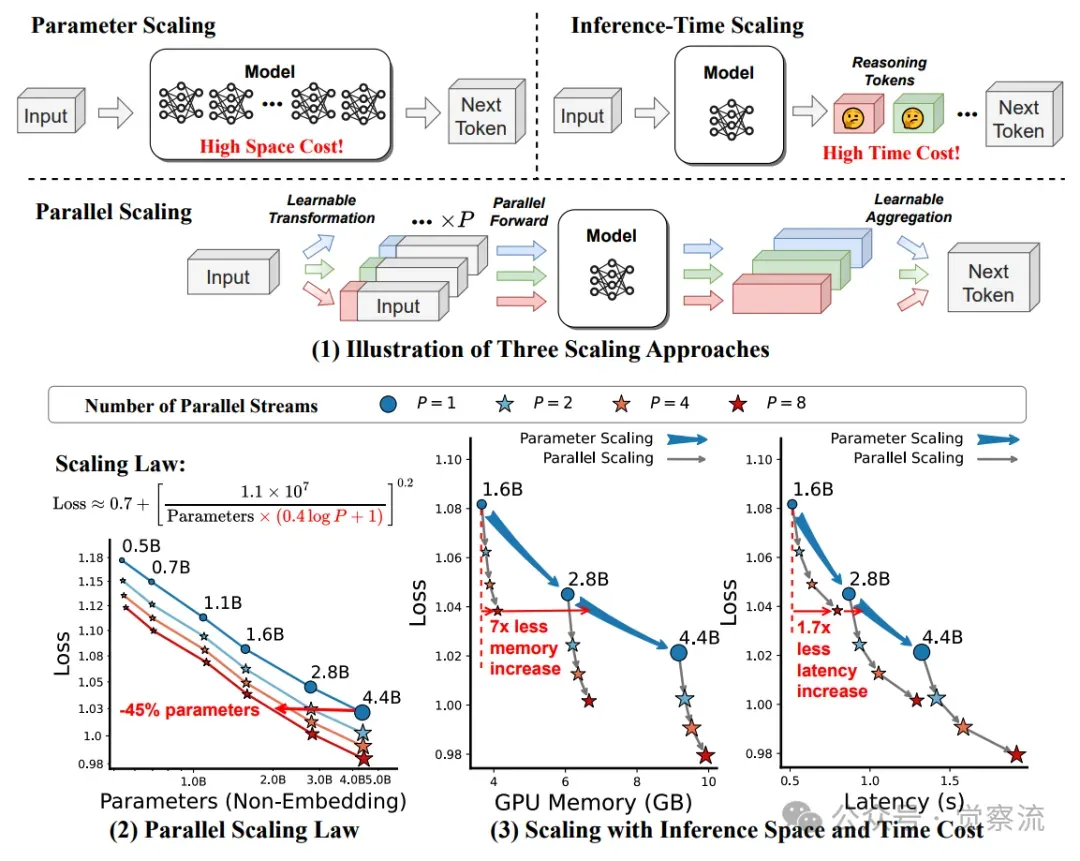
(1) 本文提出的并行扩展方法(PAR SCALE)的示意图。(2) 在Stack-V2(Python子集)的420亿个tokens上进行预训练模型的并行扩展法则。(3) 损失扩展曲线与推理成本的关系。结果是基于批量大小为{1, 2, 4, 8}和输入+输出tokens数为{128, 256, 512, 1024}的平均值。
如上图所示,PARSCALE 通过增加并行流数量 P,在保持参数规模几乎不变的情况下,显著提升了模型的推理能力。上图(1)展示了 PARSCALE 的工作原理,包括输入变换、并行前向传播和动态输出聚合的过程。上图(2)展示了在 Stack-V2 数据集上,不同参数规模和并行流数量 P 下的预训练模型的 scaling law。上图(3)则展示了推理成本与损失的曲线关系,表明 PARSCALE 在推理效率方面的优势。
PARSCALE 核心概念
灵感来源与技术设想
PARSCALE 的灵感源于分类器自由引导(Classifier-free Guidance,CFG),这是一种在扩散模型中广泛应用的技术。在扩散模型中,CFG 通过两次前向传播来提升模型性能。它首先对输入 x 进行正常前向传播,得到第一个输出;然后对输入进行扰动(例如去除条件信息),得到第二个输出;最后根据预设的对比规则,将这两个输出进行聚合。这种两次计算的方式,使得模型能够在推理阶段获得比单次前向传播更优的性能。

其中, w是一个预设的超参数,用于控制条件信息的影响程度。这种对比规则的设计使得模型能够在条件化和无条件化的输出之间找到平衡,从而提升生成结果的质量。
PARSCALE 借鉴了 CFG 的核心思想,并进行了创新性的扩展。它不再局限于两次前向传播,而是通过 P 种不同的可学习变换对输入进行处理,生成 P 个不同的输入版本。这些变换后的输入被并行地送入模型进行前向传播,得到 P 个输出。随后,通过一个动态加权平均的方法,将这 P 个输出聚合为一个最终输出。这个动态加权平均的过程,利用一个多层感知机(MLP)将多个输出转换为聚合权重,从而实现对不同输出的动态融合。

这种动态加权平均机制使得模型能够根据不同输入和任务的需求,自适应地调整各个并行流的权重,从而实现更优的推理性能。
与传统扩展策略对比
为了更清晰地展示 PARSCALE 的优势,我们可以将其与传统的参数扩展和推理时间扩展策略进行对比。
传统参数扩展策略,如密集参数扩展(Dense Scaling)和专家混合扩展(MoE Scaling),虽然能够通过增加模型参数来提升性能,但却伴随着高内存需求。例如,Dense Scaling 随着参数的增加,内存占用呈线性增长,这对于边缘设备来说是难以承受的。而 MoE Scaling 虽然在一定程度上降低了内存需求,但仍面临着高内存占用的问题,且训练成本相对较高。
推理时间扩展策略则通过增加推理时间来提升模型的推理能力。例如,OpenAI 探索的推理时间扩展方法,通过扩增推理 token 数量来增强模型的推理能力,但这种方法通常需要大量的特定训练数据,并且会显著增加推理延迟。对于实时性要求较高的应用场景,这种高延迟是难以接受的。
相比之下,PARSCALE 在推理时间、推理空间和训练成本等方面展现出独特的优势。PARSCALE 的推理时间随着 P 的增加而适度增长,但在小批量场景下,其延迟增加幅度远低于参数扩展策略。在推理空间方面,PARSCALE 的内存占用仅略有增加,远低于参数扩展策略。此外,PARSCALE 的训练成本相对较低,且不需要依赖特定的训练数据或策略,具有更广泛的适用性。
这些优势的背后,源于 PARSCALE 对计算资源的高效利用和对模型结构的创新设计。通过并行计算,PARSCALE 能够在相同的计算资源下完成更多的推理任务,从而提升了推理效率。同时,由于参数规模没有显著增加,模型的内存占用和训练成本得以有效控制,使其在资源受限的环境中更具优势。

主流大语言模型扩展策略的比较
上表对比了主流的 LLM 扩展策略,包括传统的参数扩展(Dense Scaling 和 MoE Scaling)、推理时间扩展和 PARSCALE。从表中可以看出,PARSCALE 在推理时间和推理空间上的表现优于参数扩展,且训练成本较低,适用场景更广泛。
理论基础与 scaling law
理论推导
PARSCALE 的理论基础源于对 Chinchilla scaling law 的扩展和深化。Chinchilla scaling law 描述了语言模型的损失 L 与其参数数量 N 之间的关系,表明在模型收敛后,损失 L 可以表示为:

在推导 PARSCALE 的损失函数表达式时,基于以下数学原理和步骤:

通过这些步骤,可以得出 PARSCALE 的损失函数表达式,为后续的实验验证提供了理论基础。
参数解释与影响分析

为了直观地展示这些参数对模型性能的影响,研究者绘制了参数变化与模型性能关系图。例如,在 Stack-V2 数据集上,随着 P 的增加,模型的损失逐渐降低,且在较小的 P 值范围内,损失降低幅度较大。这表明在实际应用中,适当增加 值能够显著提升模型性能,但当 P 值增大到一定程度后,性能提升的幅度会逐渐减小。因此,在设计模型时,需要根据具体的应用场景和资源限制,合理选择 P 值以达到性能和成本的平衡。
实验验证与结果分析
实验设计与设置
为了验证 PARSCALE 的有效性,研究员在 Stack-V2(Python 子集)和 Pile 语料库上进行了大规模预训练实验。实验中,模型参数范围从 5 亿到 44 亿不等,同时并行流数量 P 从 1 变化到 8。训练数据规模固定为 420 亿 tokens,以确保实验结果的可比性。
选择 Stack-V2(Python 子集)和 Pile 语料库作为实验数据集的原因在于它们的多样性和代表性。Stack-V2(Python 子集)主要包含代码相关的内容,能够有效评估模型在代码理解和生成任务上的性能。而 Pile 语料库则涵盖了多种领域的文本数据,适用于评估模型在通用语言任务上的表现。通过在这两个数据集上的实验,我们可以全面评估 PARSCALE 在不同任务类型上的性能。
在训练过程中,采用了批量大小为 1024 和序列长度为 2048 的设置,训练步数总计 20K 步。对于 P>1 的模型,在输入变换和输出聚合部分引入了额外的参数,而 P=1 的模型则保持与现有架构一致,以确保实验的公平性。所有实验均使用 Qwen-2.5 的密集架构和分词器,以统一实验条件。
这些精心设计的实验设置,目的是全面评估 PARSCALE 在不同参数规模和并行流数量下的性能表现,为后续的分析提供可靠的数据支持。
实验结果呈现
实验结果通过图表和表格的形式直观地展示出来,揭示了不同参数组合下的训练损失、验证损失以及下游任务性能指标。
在 Stack-V2-Python 数据集上,随着 P 的增加,模型的损失逐渐降低。例如,对于 1.6B 参数的模型,当 P 从 1 增加到 8 时,损失从 1.0817 降低到 1.0383,性能提升显著。同样,在 Pile 数据集上,P 的增加也带来了类似的损失降低趋势。这表明 PARSCALE 能够有效地利用并行计算来提升模型性能。
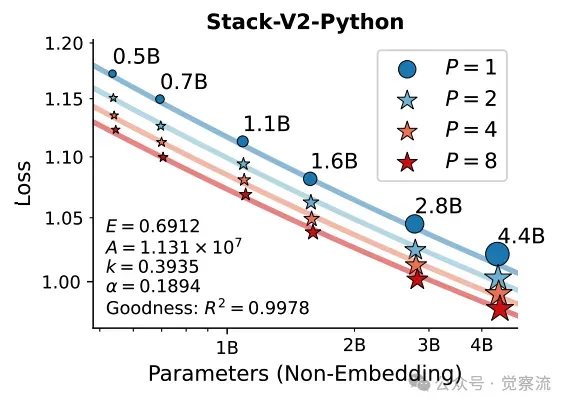
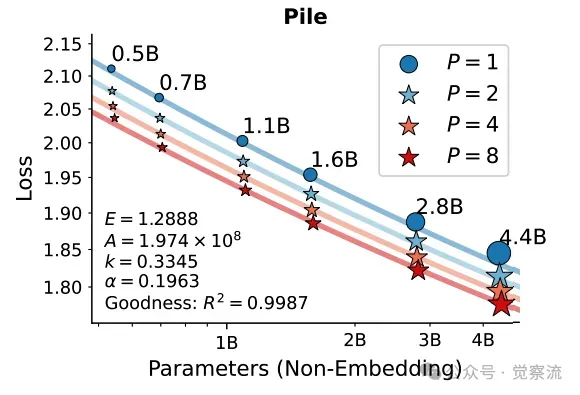
在420亿个 tokens上训练的、按参数规模和并行流数量P进行扩展的大型语言模型的损失
上图展示了在 Stack-V2(Python 子集)和 Pile 语料库上,不同参数规模和并行流数量 P 的模型的训练损失。通过拟合的 scaling law 曲线,可以观察到 PARSCALE 的损失与参数扩展之间的关系,验证了理论推导的正确性。
在下游任务性能方面,PARSCALE 同样表现出色。以代码生成任务为例,在 HumanEval 和 MBPP 数据集上,随着 P 的增加,模型的 Pass@1 和 Pass@10 指标均呈现出明显的提升趋势。例如,在 HumanEval 数据集上,1.6B 参数的模型在 P=8 时的 Pass@1 达到 18.3%,相比 P=1 时的 18.3% 保持稳定,而在 MBPP 数据集上,P=8 时的 Pass@1 达到 45.5%,相比 P=1 时的 36.0% 提升了近 10 个百分点。这表明 PARSCALE 在代码生成任务上具有显著的优势。
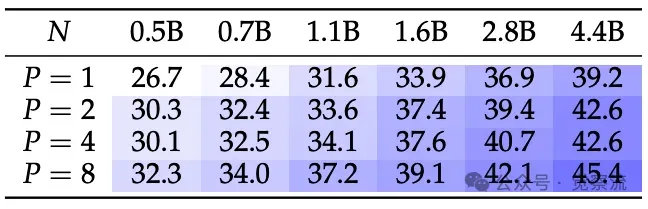
在使用 Stack-V2-Python 数据集进行预训练后,两个代码生成任务 HumanEval(+) 和 MBPP(+) 的平均性能(%)
上表展示了在 Stack-V2-Python 数据集上预训练后的代码生成任务性能。随着 P 的增加,模型在 HumanEval 和 MBPP 数据集上的性能显著提升,验证了 PARSCALE 在代码生成任务上的优势。
对于通用任务,如 MMLU 数据集,PARSCALE 也展现出了良好的性能提升。例如,4.4B 参数的模型在 P = 8 时的平均性能达到 59.6%,相比$ P = 1 ¥时的 57.2% 提升了 2.4 个百分点。这些结果表明,PARSCALE 不仅在代码生成任务上表现出色,还能在通用任务上带来显著的性能提升。
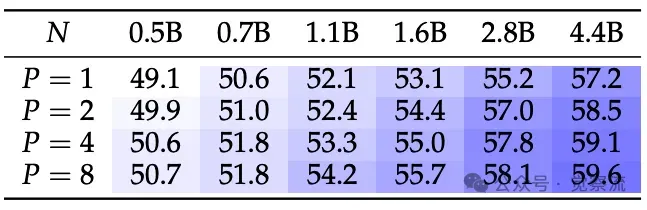
在Pile数据集上预训练后,六个通用lm-evaluation-harness任务的平均表现(%)
上表展示了在 Pile 数据集上预训练后的通用任务性能。随着 的增加,模型在 MMLU 等任务上的性能显著提升,进一步验证了 PARSCALE 的有效性。
通过这些实验结果,我们可以清晰地看到 PARSCALE 在不同实验条件下的性能优势和特点。无论是训练损失、验证损失还是下游任务性能指标,PARSCALE 都展现出了随着 P 增加而性能提升的趋势,验证了其理论基础的正确性和有效性。
推理成本分析
在推理成本方面,PARSCALE 与参数扩展策略相比,展现出显著的优势。从内存占用的角度来看,PARSCALE 在不同批量大小下的内存占用远低于参数扩展策略。例如,对于 1.6B 参数的模型,当扩展到 时,PARSCALE 的内存增加仅为参数扩展策略的 1/22。这意味着在相同的内存条件下,PARSCALE 能够支持更多的模型部署,或者在更低的硬件成本下实现相近的性能。
在延迟方面,PARSCALE 在小批量场景下表现出色。由于其并行计算的特性,PARSCALE 能够充分利用 GPU 的计算资源,将内存瓶颈转化为计算瓶颈。因此,在小批量场景下,PARSCALE 的延迟增加幅度远低于参数扩展策略。例如,在批量大小为 1 时,PARSCALE 的延迟增加仅为参数扩展策略的 1/6。这种低延迟特性使得 PARSCALE 在对实时性要求较高的应用场景中具有巨大的优势,如智能手机和智能汽车等边缘设备上的实时交互应用。
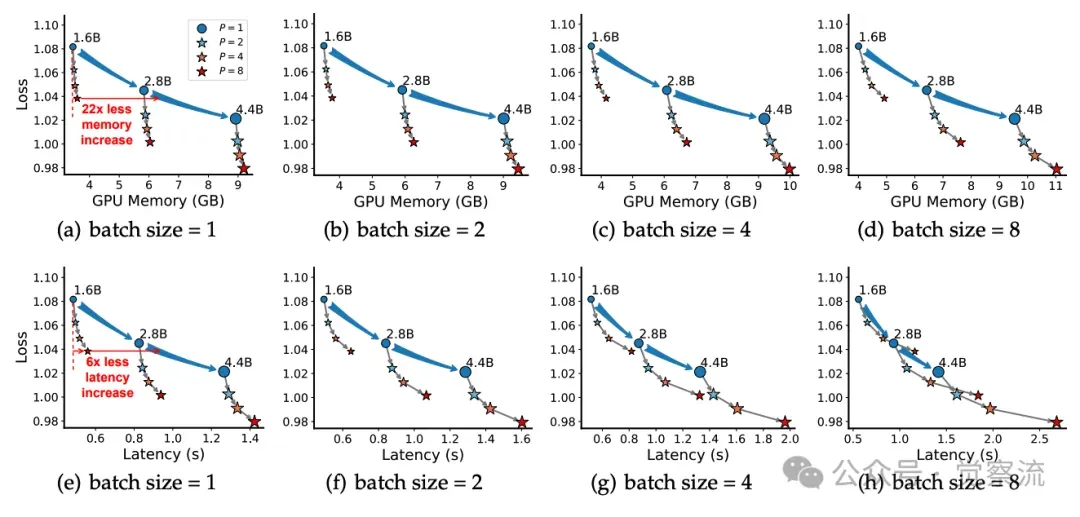
模型容量(通过损失值表示)与推理时空成本成比例关系,涉及三个参数(16亿、28亿和44亿)以及批量大小 ∈ {1, 2, 4, 8}
上图展示了模型容量(以损失表示)在推理空间时间成本上的变化,涵盖了三种参数规模(1.6B、2.8B 和 4.4B)和四种批量大小(1、2、4、8)。蓝色箭头表示参数扩展,灰色箭头表示并行扩展。结果表明,PARSCALE 在推理效率方面具有显著优势,尤其是在小批量场景下。
通过与实际应用场景相结合,我们可以进一步强调 PARSCALE 在低资源边缘部署场景中的巨大潜力和实际应用价值。它不仅能够有效降低模型的推理成本,还能在资源受限的环境中实现高性能的推理服务,为 LLM 的广泛应用提供了新的可能性。
生产级训练验证
两阶段训练策略
为了降低训练成本并验证 PARSCALE 在大规模数据训练中的有效性,研究者提出了一种两阶段训练策略。
在第一阶段,采用传统的预训练方法,使用 1T tokens 的数据进行训练。这一阶段的目标是利用大量的数据为模型提供基础的语言理解和生成能力。训练过程中,使用 Warmup Stable Decay(WSD)学习率调度策略,初始学习率为 3e-4,经过 2K 步的热身阶段后,保持学习率稳定,以确保模型能够充分学习数据中的知识。
在第二阶段,引入 PARSCALE 技术,仅使用 20B tokens 的数据进行训练。这一阶段的重点是通过并行计算来进一步提升模型的性能。降低了学习率,从 3e-4 线性衰减到 1e-5,以避免对模型参数造成过大的扰动。同时,在这一阶段引入了 种不同的可学习变换,并动态聚合输出,以增强模型的推理能力。
两阶段训练策略中各阶段的训练数据构成和学习率调度的具体方法如下:
- 第一阶段 :
训练数据 :使用 1T tokens 的通用数据,包括 370B 一般文本数据、80B 数学数据和 50B 代码数据。
学习率调度 :采用 WSD 策略,初始学习率为 3e-4,经过 2K 步热身阶段后,保持学习率稳定。
超参数设置 :批量大小为 1024,序列长度为 2048。
- 第二阶段 :
训练数据 :使用 20B tokens 的数据,增加数学和代码数据的比例,最终包括 7B 一般文本数据、7B 数学数据和 7B Stack-Python-Edu 数据。
学习率调度 :学习率从 3e-4 线性衰减到 1e-5。
超参数设置 :批量大小为 1024,序列长度为 2048。
通过展示损失曲线图,我们可以清晰地看到两阶段训练策略的效果。在第二阶段的初始阶段,由于引入了随机初始化的参数,P > 1 的模型损失略高于 P = 1 的模型。然而,随着训练的进行,模型迅速适应了这些新参数,并在处理少量数据后(约 0.0002T tokens),损失趋于稳定并逐渐降低。这表明两阶段训练策略能够快速提升模型性能,并且具有较强的适应性。
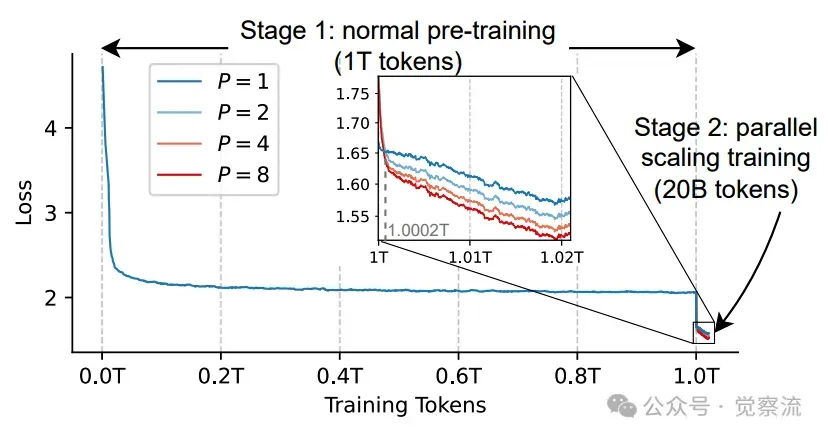
两阶段训练的损失,使用权重为0.95的指数移动平均进行平滑
上图展示了两阶段训练策略的损失曲线,使用 0.95 的指数移动平均进行平滑处理。从图中可以看出,第二阶段训练初期,P >1 的模型损失略高于 P=1 的模型,但随着训练的进行,损失迅速降低并趋于稳定,验证了两阶段训练策略的有效性。
此外,研究员还发现,在训练后期,P 较大的模型(如 P=8)能够逐渐拉开与 P 较小的模型(如 P=4 )之间的差距。这进一步证明了 PARSCALE 在大规模数据训练中的有效性,以及其随着 P 增加而性能提升的趋势。
下游任务性能表现
以 1.8B 模型为例,两阶段训练后在多个下游任务上的性能表现显著提升。
在 7 个通用任务中,随着 P 的增加,模型的平均性能呈现出稳步提升的趋势。例如,在 MMLU 任务上,P=8 时的性能达到 58.1%,相比 p=1 时的 55.0% 提升了 3.1 个百分点。在 3 个数学任务中,PARSCALE 的优势更为明显。以 GSM8K 任务为例,P=8 时的性能达到 34% 的相对提升,相比 P=1 时的 28.7% 提升了 5.3 个百分点。这表明 PARSCALE 在数学推理任务上具有显著的优势,能够有效提升模型的推理能力。
在 8 个编码任务中,PARSCALE 同样展现出了良好的性能提升。例如,在 HumanEval 任务上,P=8 时的 Pass@1 达到 18.9%,相比 p=1 时的 12.8% 提升了 6.1 个百分点。这些结果表明,PARSCALE 在编码任务上能够显著提升模型的性能,为代码生成等应用场景提供了更强的支持。
特别是对于推理密集型任务,如 GSM8K 等,PARSCALE 的性能提升更为显著。例如,在 GSM8K 任务上,P=8 时的性能达到 38.4%,相比 P=1 时的 28.7% 提升了 9.7 个百分点。这表明 PARSCALE 在处理复杂的推理任务时,能够充分发挥其并行计算的优势,显著提升模型的推理能力和任务性能。
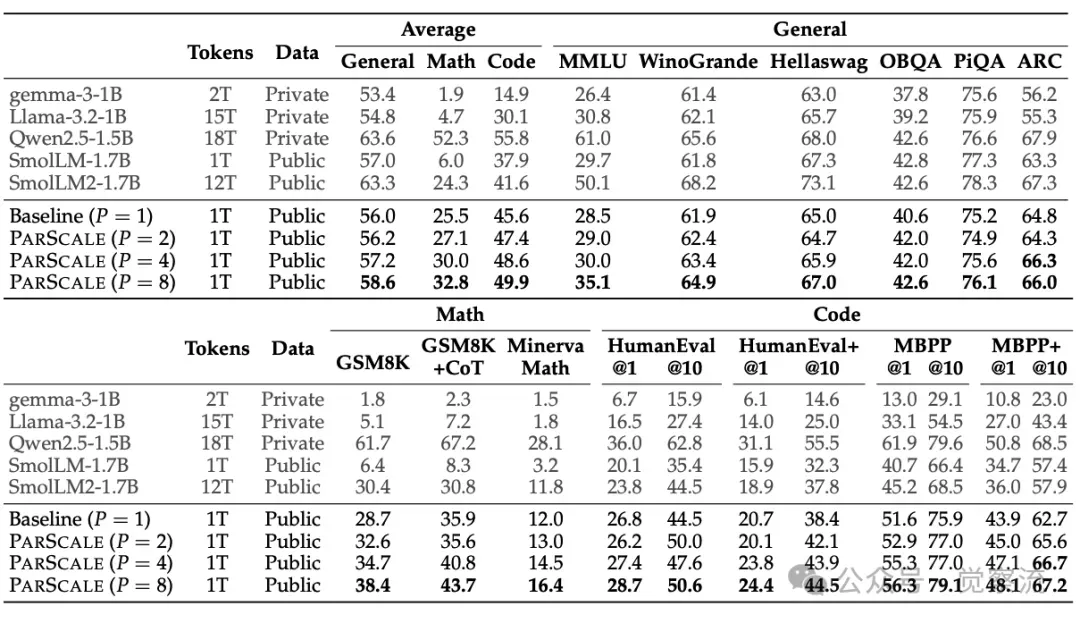
在使用两阶段策略从零开始训练1T tokens后,1.8B模型的性能对比
上表展示了使用两阶段策略从头开始训练的 1.8B 模型的性能比较。结果表明,随着 P 的增加,模型在多个下游任务上的性能显著提升,验证了两阶段训练策略的有效性。
指令调优与应用
对两阶段训练得到的模型进一步进行指令调优,PARSCALE 在指令遵循任务中的表现也得到了显著提升。
以 IFEval 基准测试为例,随着 P 的增加,模型的性能呈现出明显的提升趋势。例如,P=8 时的性能达到 59.5%,相比 P=1 时的 54.1% 提升了 5.4 个百分点。这表明 PARSCALE 在指令遵循任务中具有显著的优势,能够有效提升模型对指令的理解和执行能力。
在调优过程中,发现 PARSCALE 的动态加权平均机制能够根据不同的任务和输入,灵活地调整各个并行流的权重。这种自适应的调整能力使得模型能够在不同的任务中充分发挥各个并行流的优势,从而实现性能的全面提升。此外,PARSCALE 的并行计算特性使得模型在处理指令任务时能够更高效地利用计算资源,进一步提升了推理效率。
通过这些实验结果,我们可以看到 PARSCALE 在指令调优中的显著优势。它不仅能够提升模型的性能,还能在实际应用中提供更高效、更准确的服务,为指令遵循任务的发展提供了新的技术支持。
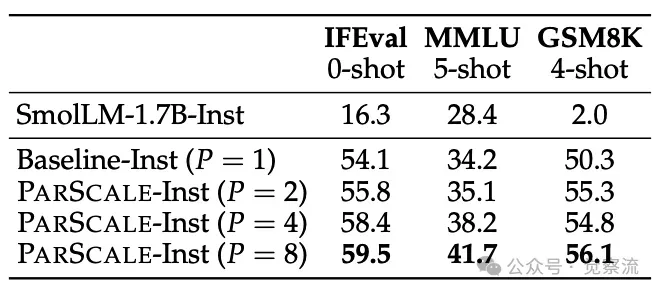
不同指令模型性能的比较,其中少样本示例被视为多轮对话
上表展示了不同指令模型的性能比较,其中将少量样本示例视为多轮对话。结果表明,PARSCALE 在指令遵循任务中表现优异,随着 P 的增加,模型性能显著提升。
在现成预训练模型中的应用验证
持续预训练与参数高效微调
为了验证 PARSCALE 在现成预训练模型中的有效性,以 Qwen-2.5(3B)模型为例,进行了持续预训练和参数高效微调(PEFT)实验。
在持续预训练方面,在 Stack-V2(Python)和 Pile 数据集上对 Qwen-2.5 模型进行了进一步训练。通过引入 PARSCALE 的并行计算机制,模型在这些数据集上的性能得到了显著提升。例如,在 Stack-V2(Python)数据集上,经过持续预训练后,模型的训练损失显著降低,表明其在代码理解和生成方面的能力得到了增强。
在参数高效微调(PEFT)方面,仅对 PARSCALE 引入的参数进行微调,而冻结了模型的主体权重。实验结果表明,即使在冻结主体权重的情况下,PARSCALE 仍然能够显著提升模型的性能。例如,在 Stack-V2(Python)数据集上,经过 PEFT 后,模型在代码生成任务上的性能提升了 8.5 个百分点。这表明 PARSCALE 的并行计算机制能够有效地利用少量的训练数据来提升模型的性能,具有很强的适应性和灵活性。
此外,动态并行扩展的灵活性和潜力也得到了充分展示。在不同应用场景中,我们可以灵活切换并行流数量 P,以适应不同的吞吐量和模型能力需求。例如,在高吞吐量的场景中,我们可以增加 P 值以提升模型的推理能力;而在低资源的场景中,我们可以减少 P 值以降低内存占用和推理延迟。这种灵活性使得 PARSCALE 能够在多种应用场景中发挥其优势,为模型的实际部署提供了更多的选择。
实验结果对比
在持续预训练和 PEFT 实验中,研究员通过训练损失图和代码生成性能指标对 PARSCALE 的效果进行了对比分析。
在持续预训练过程中,训练损失图显示,随着训练的进行,PARSCALE 模型的损失逐渐降低,并且在相同的训练数据量下,P 较大的模型损失更低。这表明 PARSCALE 能够更有效地利用训练数据来提升模型性能。
在代码生成性能方面,经过 PEFT 后,PARSCALE 模型在 HumanEval 和 MBPP 等基准测试中的表现显著提升。例如,在 HumanEval 数据集上,P = 8 时的 Pass@1 达到 25.0%,相比 P = 1 时的 18.9% 提升了 6.1 个百分点。这些结果表明,PARSCALE 在现成预训练模型中的应用是有效的,能够显著提升模型的代码生成能力。
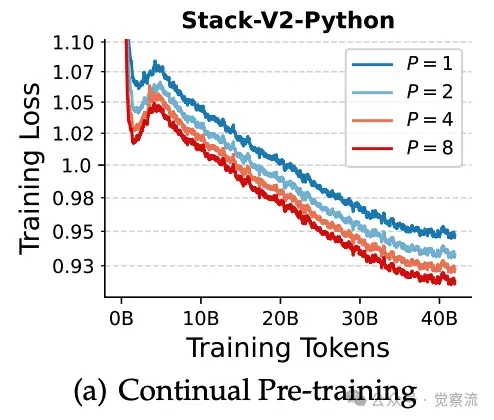
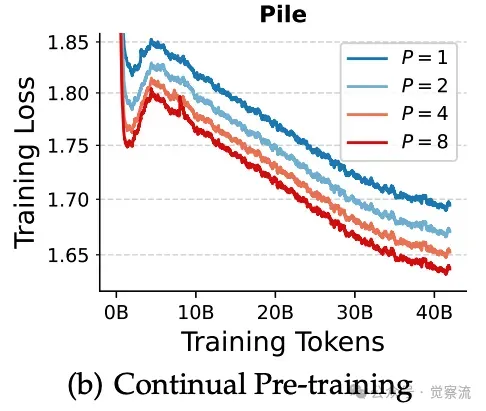
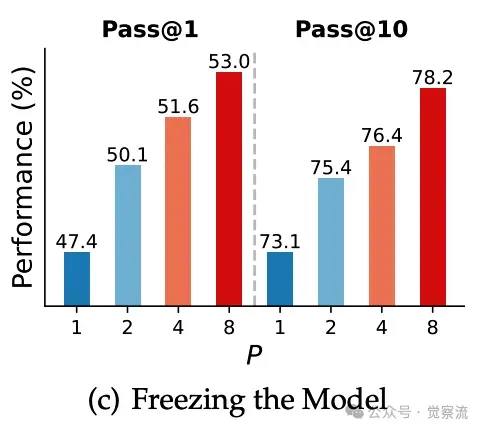
(a)(b) 在两个数据集上对Qwen-2.5-3B模型进行持续预训练的损失情况。 (c) 在Stack-V2(Python)上微调后的代码生成性能。
上图(a)和(b)展示了在 Stack-V2(Python)和 Pile 数据集上持续预训练 Qwen-2.5-3B 模型的损失曲线。图 6(c)则展示了在 Stack-V2(Python)数据集上进行参数高效微调后的代码生成性能。这些图表验证了 PARSCALE 在现成预训练模型中的有效性。
通过这些实验结果,我们可以看到 PARSCALE 在现成预训练模型中的巨大潜力。它不仅能够提升模型的性能,还能在实际应用中提供更灵活的部署方案,为模型的广泛应用提供了有力支持。
相关工作、讨论、总结
与推理时间扩展和模型集成的关系
PARSCALE 与推理时间扩展和模型集成等领域的联系与区别,进一步凸显了其独特价值。
推理时间扩展策略主要通过增加推理时间来提升模型的推理能力。例如,OpenAI 的推理时间扩展方法通过扩增推理 token 数量,让模型在推理阶段进行更多的计算,从而提升推理性能。然而,这种方法通常需要大量的特定训练数据,并且会显著增加推理延迟。相比之下,PARSCALE 在推理阶段的延迟增加幅度较小,且不需要依赖特定的训练数据,具有更广泛的适用性和更高的推理效率。
模型集成是一种通过结合多个模型的预测结果来提升性能的方法。传统的模型集成方法通常不共享参数,或者仅部分共享参数。例如,Monte Carlo dropout 通过在推理阶段应用不同的随机 dropout 遮罩来生成多个预测结果,然后进行集成。而 PARSCALE 则是在保持参数规模几乎不变的情况下,通过并行计算来实现模型集成的效果。它利用 P 种不同的可学习变换和动态加权平均机制,使得各个并行流之间既共享大部分参数,又能保持一定的差异性。这种设计不仅降低了模型集成的内存占用和训练成本,还提升了推理效率。
PARSCALE 与推理时间扩展和模型集成之间也存在协同作用的可能性。例如,可以将 PARSCALE 与推理时间扩展相结合,在推理阶段同时利用并行计算和序列计算来进一步提升模型性能。或者,可以将 PARSCALE 与其他模型集成方法相结合,构建更具鲁棒性和性能的模型系统。这些协同作用的探索将进一步拓展 PARSCALE 的研究视野和应用前景。
对模型容量本质的思考
PARSCALE 的研究成果引发了我们对模型容量本质的深入思考。传统上,模型容量通常被认为是参数数量和计算量的综合体现。然而,PARSCALE 的研究表明,模型容量可能更多地取决于计算量,而非单纯的参数数量。
在 PARSCALE 中,通过增加并行计算次数 P,在几乎不增加参数数量的情况下,显著提升了模型的性能。例如,在 Stack-V2 数据集上,当 P 从 1 增加到 8 时,1.6B 参数的模型性能与 4.4B 参数的模型相当。这说明,通过合理的计算扩展,即使在参数规模较小的情况下,模型也能够达到较高的性能水平。
这种对模型容量的新理解,为我们未来的模型设计和扩展策略提供了有益的启示。它提醒我们在追求更大参数规模的同时,不应忽视计算量对模型性能的提升作用。通过优化计算结构和提升计算效率,我们可以在有限的资源下实现更强大的模型性能,为 AI 技术的发展注入新的动力。
总结关键发现
PARSCALE 作为一种新型的语言模型扩展范式,在多个方面展现出了显著的优势和巨大的潜力。
- 性能提升 :通过增加并行计算次数 P,PARSCALE 能够显著提升模型在各种任务上的性能。例如,在代码生成任务上,P = 8 时的性能相比 P = 1 时提升了近 10 个百分点;在数学推理任务上,性能提升幅度更是高达 34%。
- 推理效率 :PARSCALE 在推理效率方面表现出色。与参数扩展策略相比,PARSCALE 在内存占用和推理延迟方面均具有显著优势。在小批量场景下,其延迟增加幅度仅为参数扩展策略的 1/6,内存占用增加幅度仅为 1/22。
- 训练成本 :PARSCALE 的训练成本相对较低。通过两阶段训练策略,我们能够在处理少量训练数据的情况下,快速提升模型性能,降低了训练成本。
- 适用场景广泛 :PARSCALE 适用于多种应用场景,从代码生成到通用任务,从数学推理到指令遵循任务,均展现出了良好的性能提升。其动态并行扩展的灵活性使得模型能够适应不同的吞吐量和资源限制需求。
这些关键发现表明,PARSCALE 不仅能够有效解决当前 LLM 面临的性能瓶颈和资源限制问题,还为未来智能模型的发展提供了一种全新的思路和技术途径。
参考资料
- Parallel Scaling Law for Language Models.https://arxiv.org/pdf/2505.10475
- Training compute-optimal large language modelshttps://arxiv.org/abs/2203.15556
- Scaling laws for neural language models.https://arxiv.org/abs/2001.08361
- Qwen2.5 technical report.https://arxiv.org/abs/2412.15115
- The pile: An 800gb dataset of diverse text for language modeling.https://arxiv.org/abs/2101.00027


