
本文第一作者郝一鸣,香港中文大学(深圳)GAP-Lab 在读博士生。本文共同第一作者为许牧天,于香港中文大学(深圳)取得博士学位。导师韩晓光教授,为本文通讯作者。
在个性化视觉生成的实际应用中,通用视觉基础模型的表现往往难以满足精准需求。为实现高度定制化的生成效果,通常需对大模型进行针对性的自适应微调,但当前以 LoRA 为代表的主流方法,仍受限于定制化数据收集与冗长的优化流程,耗时耗力,难以在真实场景中广泛应用。
为此,港中大(深圳)GAP-Lab 提出全新框架 LoFA,从上重塑个性化视觉生成的技术路径。该框架能够在数秒内根据用户指令前馈式直出对应的 LoRA 参数,使大模型快速适配到个性化任务中 —— 无需漫长优化,效果却媲美甚至超越传统 LoRA,真正推动大模型适配进入 “即时获取” 的新时代。

论文名称:LoFA: Learning to Predict Personalized Priors for Fast Adaptation of Visual Generative Models
论文链接:https://arxiv.org/abs/2512.08785
项目主页:https://jaeger416.github.io/lofa/
开源代码:https://github.com/GAP-LAB-CUHK-SZ/LoFA
 背景与挑战
背景与挑战

图 1. LoFA 概念图:与传统 LoRA 的对比
近年来,创意媒体和视觉内容的需求持续增长,这推动了功能强大的视觉生成基础模型的发展。这类模型通过大规模图像或视频数据集训练,展现出丰富的能力与通用的先验知识。然而,面对用户的个性化需求 —— 尤其是涉及细粒度指令时,模型往往难以生成完全符合用户期望的结果(如图 1 “WAN” 所示,文本到视频基础模型 WAN 在理解 “一名男子正在做功夫侧踢” 这类具体动作指令时表现不佳)。
为解决这一问题,早期研究通常采用 parameter-efficient fine-tuning (PEFT) 技术,通过融入个性化先验知识来调整模型。但这些方法需要为每个个性化任务单独优化适配器(例如 LoRA),不仅依赖特定任务数据,还需大量优化时间(见图 1 “Classical LoRA” 示例),难以满足实际应用中用户对快速响应新需求的要求。
为实现快速适配,近期少量研究尝试在测试阶段直接预测 LoRA 权重。例如,HyperDreamBooth 提出了基于 hypernetwork 的方法,但仍需额外的后优化步骤;DiffLoRA 则在此基础上完全取消了后优化过程。然而,这一研究方向面临一个根本性挑战:模型必须学习从低维细粒度用户指令到高维复杂 LoRA 参数分布的复杂映射关系。
正因如此,现有方法目前仅在图像生成中针对主体身份个性化这类相对受限的场景中得到验证。这一局限可能源于这些方法将 LoRA 权重压缩至低维空间作为超网络输出,不可避免地造成信息损失并限制模型表达能力。因此,如何实现能够有效处理细粒度用户指令或高维复杂 LoRA 权重的快速模型适配方法 —— 这对面向用户的实际应用至关重要 —— 仍然是视觉生成领域一个亟待探索的研究难题。
为弥补这一空白,本论文提出了 LoFA—— 一种通用的学习框架,能够从多样化或细粒度的用户指令中直接预测个性化 LoRA 参数,实现视觉生成模型的快速适配(见图 1 “LoFA” 部分)。
核心方法介绍

图 2. LoRA 响应图谱的可视化:独特的结构化分布
LoFA 的核心思路是在 hypernetwork 的设计中嵌入一种新型引导机制,使其能够直接从用户指令中预测完整且未经压缩的 LoRA 权重,而无需依赖有损压缩技术。为实现这一目标,作者首先发现了 LoRA 的一个关键特性 —— 响应图谱。该图谱呈现为个性化 LoRA 权重与原始模型参数间相对变化所形成的独特结构化模式,能够有效捕捉用户指令的核心影响(可视化结果见图 2,具体分析见论文)。
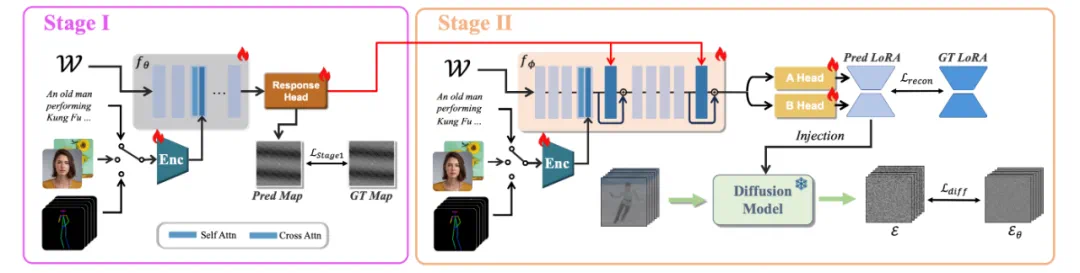
图 3. LoFA 的流程:响应图谱引导的两阶段学习框架
基于这一发现,论文设计了一种全新架构(如图 3),摒弃了直接进行 “指令 - LoRA 权重” 的暴力映射方式。该架构以原始基础模型权重作为输入,通过交叉注意力机制融合用户指令,从而学习相对适配关系。整个学习过程进一步划分为两个阶段:网络首先预测响应图谱(其维度远低于 LoRA 权重且结构更简单),随后运用习得的响应知识引导最终的 LoRA 权重预测,使其能够识别并聚焦关键适配区域,从而简化学习过程并提升稳定性。
通过这种结构化响应引导的设计,网络能够学习基础模型与目标 LoRA 之间的相对适配关系,同时预测具备完整表达能力的、未经压缩的 LoRA 权重。
实验分析
论文通过系统性的实验评估 LoFA 框架在视频与图像生成任务中的有效性。为全面验证其处理多样化指令条件的泛化能力,论文在三个关键应用场景中测试了多种输入模态:
在视频生成任务中,以 WAN2.1-1.3B 为基础模型,重点评估两方面应用:
(1)基于文本或运动姿态的个性化人体动作视频生成,该任务针对视频数据的核心属性 —— 动态运动的个性化建模,具有显著挑战性;
(2)以风格图像为参考的文本到视频风格化,此为视频编辑领域的经典任务。
在图像生成任务中,采用 Stable Diffusion XL 作为基础模型,评估(3)ID 个性化图像生成 —— 这也是先前相关研究唯一支持的应用场景。
LoFA 不仅在性能上显著超越基线方案,更达到了与独立优化的 LoRA 模型相媲美 —— 且在多类场景中表现更优的效果,这证明了快速模型适配在实际应用中的可行性。所有结果如下:

图 4. 基于文本的个性化人体动作视频生成结果对比

图 5. 基于运动姿态的个性化人体动作视频生成结果对比

图 6. 以风格图像为参考的文本到视频风格化
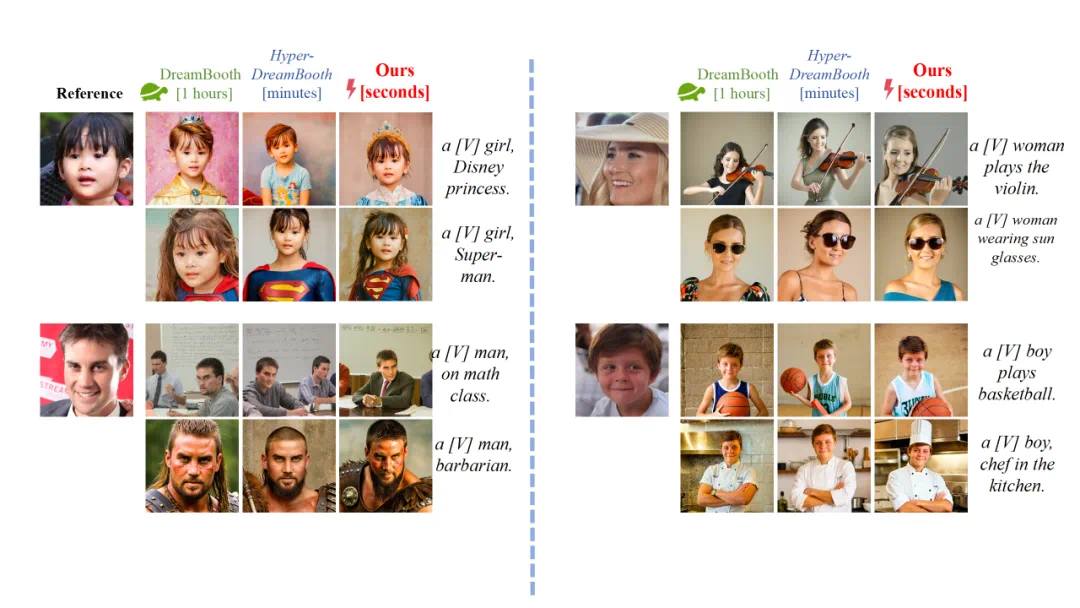
图 7. ID 个性化的图像生成
总结与展望
LoFA 突破了现有个性化技术的关键局限 —— 在保持高质量生成结果的同时,彻底消除了冗长的优化过程。大量实验表明,LoFA 取得了与逐例优化的 LoRA 模型相当甚至更优的性能,同时将适配时间从数小时缩短至秒级。这一进展为高效模型适配确立了新的范式,有望推动各类实时个性化应用的发展。然而,当前 LoFA 仍需要针对不同领域的特定指令(如人体动作指令、身份特征指令或艺术风格指令)分别训练独立网络。理想的解决方案应是构建具备强大 zero-shot 能力的 unified hypernetwork。通过扩大训练数据的规模与多样性,这一目标未来将有望实现。


