本科经典算法Dijkstra,被清华团队超越了!
这个被用来解决最短路径问题的经典算法,去年才被图灵奖得主Tarjan团队证明具有普遍最优性。
但现在,来自清华的段然团队将这一格局彻底打破——
运行速度比任何Dijkstra及其改进算法都快,关键是它彻底解决了困扰研究人员四十多年来的“排序障碍”。因为它压根就不进行排序。

该算法改进了图灵奖得主Tarjan提出的O(m + nlogn)算法,后者在1984年将Dijkstra原始算法探索到了速度极限。
而更快的最短路径算法,不管是在理论上和实际应用中都有很大意义,参考Dijkstra算法就知道了。Dijkstra算法广泛地应用于我们的日常生活中,例如地图APP,被用来计算从用户当前位置到目的地的最优路线。而在计算机网络中也被广泛应用于路由协议中。
这一进展被曝光,一时间引发了不少关注。

也有人不吝赞美:这是一个重要的里程碑。
但也有人认为,对大模型来说可能是个挫折,尤其在GPT-5发布之际,因为我们总是期待AI能发现这些突破性进展。
GPT-5已经准备好编码了。
找到最佳路线的最快方法
找到从网络中特定起点到其他每个点的最短路径。有科学家曾形容这是个标志性问题,最短路径是一个世界上任何人都能理解的美丽问题。
从数学角度来分析问题,研究人员更倾向于用节点组成的网络,通过线段连接起来,然后找到通往每个节点的最短路径。
但过去一直以来,任何遵循这种方法的算法都有一个基本的速度限制:你的速度不可能比排序所需的时间更快。
因为如果你想解决一个棘手的问题,整理思路通常很有帮助。比如,你可以把问题分解成几个部分,先解决最简单的部分。但这种整理是有代价的。你可能会花费太多时间去整理这些碎片。
这就像你每次搬家时可能需要思考从新家到工作地点、健身房和超市的最佳路线。
最经典的最短路径算法就是Dijkstra。这是计算机专业本科生都在学的算法,它的思路是从源头开始,逐步向外推进——
通过扫描该区域的 “边界”, 来决定下一步要去哪里。这最初并不需要花费太多时间,但随着算法的推进,速度会变得越来越慢。

△图源:Quantamagzine
过去一直有人在这个算法上进行改进,但都达到了速度限制。于是乎,这项研究停止了很长时间,很多人认为没有更好的方法。没想到的是,这个问题困住了研究员们接近半世纪。
去年,图灵奖得主Robert Tarjan及合作者发表的论文证明了Dijkstra算法对于“最短路径排序问题”的普遍最优性,获得了FOCS 2024的最佳论文奖。
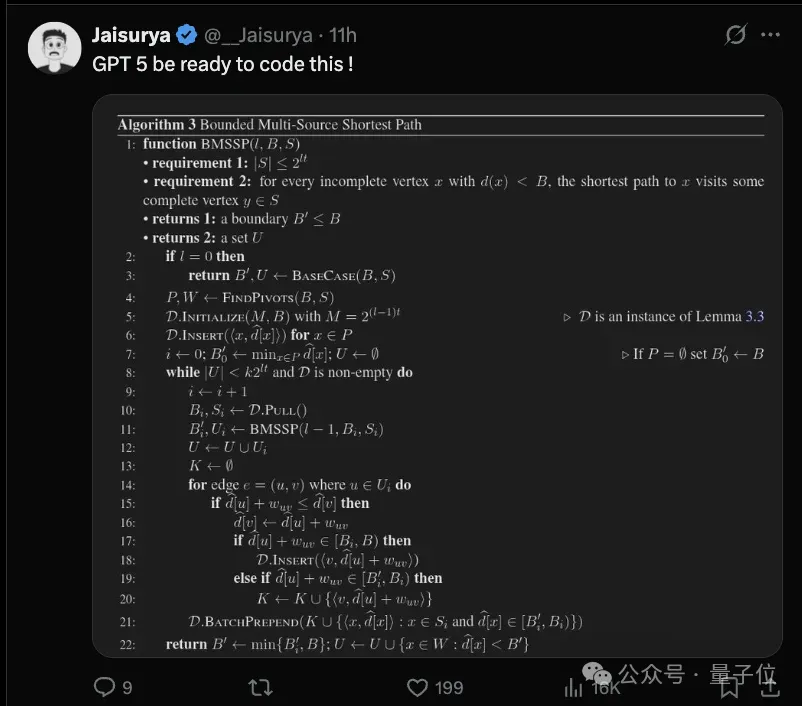
直到现在清华大学段然团队的新算法打破了这一局面,新算法避免了整体排序,得到了比Dijkstra算法更快的最短路径问题的算法。
他设想将边界上相邻的节点分组成簇。然后,他只考虑每个簇中的一个节点。由于需要筛选的节点更少,搜索在每一步都可以更快。算法也可能最终到达最近节点以外的地方,因此排序障碍不再适用。
但是,确保这种基于簇的方法实际上使算法更快而不是更慢将是一个挑战。
2022年秋天,他找了三位研究生来帮助解决细节问题,几个月后得到部分解决方案:新算法可以打破任何权重的排序障碍,但仅限于无向图。
时间来到2023年夏天,段然教授在加州某一会议上分享无向图算法时遇到了毛啸,两人相谈甚欢,随后继续展开了探索。
他们从另一个著名的最短路径问题算法中汲取了灵感,这就是Bellman-Ford算法,它不产生有序列表。
乍看之下,Bellman-Ford算法比Dijkstra的算法慢得多,似乎不具备参考价值。但在他们的尝试下,只运行几步就能避免Bellman-Ford算法的缓慢问题。这样一来,他们就接着往后续步骤进行探索。
2024年3月,毛啸设计了一种用无需随机性的新方法来解决最短路径问题。随后正式加入了团队。后来段然意识到他们可以借鉴2018年设计的一个算法。它适用于不同的图问题。也许可以突破排序瓶颈。

这一技术正是他们所需的最后一块拼图,使算法在有向图和无向图上的运行速度均快于Dijkstra算法。
最终这一算法,将图切分成多层,然后同Dijkstra算法一样从从源头向外扩展。
但它不是在每一步都处理整个边界,而是使用Bellman-Ford算法来精确定位有影响力的节点。
从这些节点出发,向前移动,找到通往其他节点的最短路径,然后再返回到其他边界节点。
它并不总是按照距离递增的顺序在每一层中找到节点,因此排序障碍并不适用。如果你以正确的方式切分图,它的运行速度会比Dijkstra算法的最佳版本略快。
它的算法要复杂得多,依赖于许多需要完美组合的片段。但奇怪的是,这些片段都没有使用复杂的数学原理。
段然和他的团队计划探索简化该算法的可能性,使其运行速度更快。
随着排序障碍的消除,新算法的运行时间已接近计算机科学家所知的任何基本极限。
有人表示,这玩意儿或许50年前就被发现了,也正因此,这一结果才显得令人印象深刻。
图灵奖得主普林斯顿大学Tarjan教授就放话了:
作为一个乐观主义者,如果这方法能更进一步简化和提效,我不会感到惊讶。我绝对不认为这是这个过程的最后一步。
清华段然团队
这篇论文在理论计算机国际顶级会议STOC 2025上获得最佳论文奖。
清华大学交叉信息院副教授段然为论文通讯作者,研究方向包括图论算法、数据结构、计算理论。

他本科毕业于清华计算机系,随后前往密歇根大学攻读博士学位。毕业后又在马克斯普朗克信息学研究所做博士后研究。
他对排序障碍的兴趣可以追溯到近20年前他在密歇根大学攻读研究生期间,当时他的导师是那些在特定情况下破解该障碍的研究人员之一。
其他作者包括姚班2019届本科毕业生束欣凯,以及姚班毕业生、交叉信息院2022级博士生毛嘉怡和2021级博士生尹龙晖。
此外斯坦福大学2022级博士生毛啸也作出了贡献。


