
现有 RAG 系统在处理复杂查询时力不从心。一方面,它们依赖扁平的数据表示,无法有效捕捉实体间的复杂关系;另一方面,缺乏上下文感知能力,导致生成的回答碎片化,难以形成连贯的逻辑。例如,当用户询问 “电动汽车的兴起如何影响城市空气质量和公共交通基础设施?”,传统 RAG 可能只是分别检索相关信息,却无法将这些内容有机整合,给出全面且有逻辑的答案。
来自北京邮电大学和香港大学的团队提出 LightRAG,通过引入基于图结构的文本索引和双层检索范式,显著提升 RAG 系统的性能。
项目地址:https://github.com/HKUDS/LightRAG
1、LightRAG
为了确保RAG系统的效率和效果,LightRAG主要关注以下三个方面:
- 全面的信息检索:索引函数
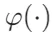 必须擅长提取全局信息,这对于提高模型回答查询的能力至关重要。
必须擅长提取全局信息,这对于提高模型回答查询的能力至关重要。 - 高效低成本的检索:索引的数据结构
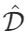 必须支持快速且成本效益高的检索操作,以便能够有效地处理大量查询。
必须支持快速且成本效益高的检索操作,以便能够有效地处理大量查询。 - 快速适应数据变化:系统应该有能力迅速调整其内部结构以包含新的信息,这保证了系统能够在不断变化的信息环境中保持最新和相关性。
基于上述目标,LightRAG通过引入图结构和双层检索范式来增强检索增强生成,框架图如下所示:
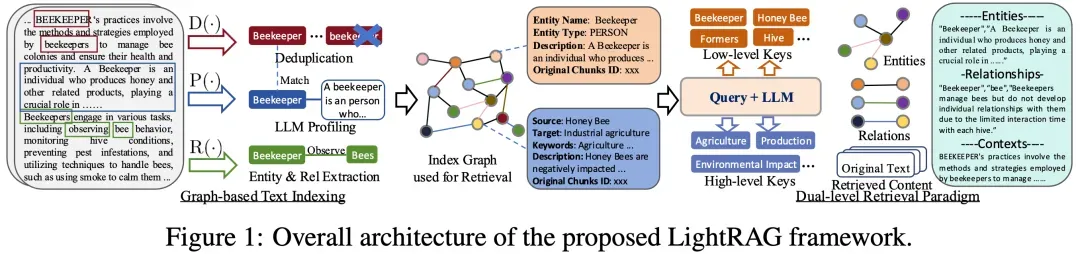
下面来看看LightRAG的核心模块:
基于图的文本索引
LightRAG 的第一个关键创新是基于图的文本索引机制,主要包括图增强实体与关系抽取和快速适应增量知识库:
1. 图增强实体与关系抽取
LightRAG通过将文档分割成更小、更易管理的部分来提升检索系统的效率。这种方法允许快速定位和访问相关信息而无需分析整个文档。然后利用大语言模型(LLMs)识别并提取各种实体(如名称、日期、地点和事件)及其之间的关系。这些信息用于创建一个全面的知识图谱,它强调了跨所有文档集合的连接和洞察。
具体实现:
- 实体和关系抽取:利用一个提示驱动的LLM从文本数据中识别出节点(实体)和边(关系)。例如,给定句子 "心脏病学家评估症状以识别潜在的心脏问题",它可以提取“心脏病学家”和“心脏病”作为实体,以及两者间的关系 "诊断"。
- LLM配置文件生成:利用LLM为每个实体节点和关系边生成键值对,其中键是便于检索的单词或短语,值是总结相关片段的文本段落,有助于后续文本生成。
- 去重优化图操作:最后一步是对来自不同文本片段的相同实体和关系进行合并,以减少图操作的开销,从而提高数据处理效率。
2. 快速适应增量知识库
当有新的文档加入时,LightRAG能够通过增量更新算法高效地将其整合进现有的知识图谱中,而无需重新处理整个数据库。新文档经过相同的图基索引步骤后产生新的图数据,然后将其与原图数据结合,即取节点集以及边集的并集。这种方法保证了新旧信息的一致性,并减少了计算资源的消耗。
基于图的文本索引,LightRAG获得了两个主要的优势:
- 全面的信息理解:构建的图结构允许从多跳子图中提取全局信息,增强了LightRAG处理涉及多个文档片段的复杂查询的能力。
- 增强的检索性能:由图衍生的关键字数据结构被优化用于快速且精确的检索,提供了一个比现有方法(如嵌入匹配或块遍历技术)更为优越的选择。
双层检索范式
传统的检索增强型生成(RAG)系统通常依赖于将文档分割成小块(chunks),并通过向量嵌入的方式检索与用户查询最相似的文本块。然而,这种方法存在局限性:
- 缺乏语义关联性:无法有效捕捉实体之间的复杂关系。
- 难以处理复杂查询:对于涉及多个实体和关系的查询,难以提供连贯的答案。
为了解决这些问题,LightRAG提出了双层检索范式,通过结合低层次和高层次的检索策略,同时满足对具体信息和抽象概念的需求。
- 低层次检索(Low-Level Retrieval)低层次检索专注于检索与用户查询相关的具体实体及其属性或关系。其目标是提供精确的信息,适用于以下类型的查询:低层次检索的优势在于能够深入探索特定实体的细节,但可能缺乏对全局信息的把握,因此需要与高层次检索相结合。
具体查询:例如,“谁写了《傲慢与偏见》?”这类查询需要检索特定的实体(如作者)及其相关属性。
检索方式:通过知识图谱中的节点(实体)和边(关系)进行精确匹配,提取与查询直接相关的详细信息。
- 高层次检索(High-Level Retrieval)高层次检索则关注更广泛的主题和概念,而不是具体的实体。它通过聚合多个相关实体和关系的信息,提供对更高层次概念和总结的理解。其目标是:高层次检索的优势在于能够提供更广泛的视角,但可能缺乏对具体细节的深入分析,因此需要与低层次检索互补。
处理抽象查询:例如,“人工智能如何影响现代教育?”这类查询需要从多个相关实体和关系中提取信息,以提供对主题的全面理解。
检索方式:通过知识图谱中的全局关键词和主题进行检索,提取与查询相关的多个实体和关系的总结信息,而不是具体的细节。
双层检索的实现机制
为了实现双层检索,LightRAG采用了以下技术策略:
- 查询关键词提取:对于给定的查询q,算法首先会从中抽取本地查询关键词
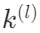 和全局查询关键词
和全局查询关键词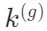 。本地关键词通常是描述具体实体的术语,而全局关键词则涵盖了更广泛的上下文。
。本地关键词通常是描述具体实体的术语,而全局关键词则涵盖了更广泛的上下文。 - 关键词匹配:使用高效的向量数据库来匹配本地查询关键词与候选实体,以及全局查询关键词与由全局关键词链接的关系。这一步骤利用了预先构建的知识图谱中的结构化信息,使得匹配过程更为准确。
- 融入高阶相关性:为了增强查询的高阶相关性,LightRAG还会收集已检索图元素局部子图内的邻近节点。这意味着不仅考虑直接匹配的结果,还包括与之紧密相连的一级邻居节点和边,从而扩大了检索范围并增强了答案的深度和广度。
通过上述机制,双层检索范式不仅实现了相关实体和关系的高效检索,而且通过集成来自构建的知识图谱的相关结构信息,大大提升了检索结果的全面性和准确性。这种方法确保了无论面对具体还是抽象的查询,LightRAG都能有效地为用户提供所需的信息。
检索增强答案生成
在检索到相关信息后,LightRAG 利用通用的 LLM 生成答案。它将检索到的实体和关系的拼接值作为输入,生成与用户查询一致的答案。这种方法不仅简化了回答生成的过程,还保持了上下文和查询的一致性。
2、实验结果
数据集
基于 UltraDomain 基准测试集中的四个数据集,这些数据集来源于428本大学教科书,涵盖了18个不同的领域,包括农业、计算机科学(CS)、法律和混合内容。每个数据集包含60万到500万个标记。
评估
通过整合数据集文本、利用大语言模型生成问题:
将每个数据集所有文本整合为上下文,借助大语言模型生成 5 个虚拟用户,每个用户对应 5 个任务。针对每个用户任务组合,由大语言模型生成 5 个需理解整个语料库的问题,每个数据集最终产生 125 个问题。
评估分为四个维度:
- 完整性(Comprehensiveness):回答是否全面地解决了问题的所有方面和细节。
- 多样性(Diversity):回答是否提供了不同视角和见解,丰富多样。
- 赋能性(Empowerment):回答是否有效地帮助读者理解话题并作出明智判断。
- 总体表现(Overall):综合前三个维度的表现,确定最佳的整体回答。
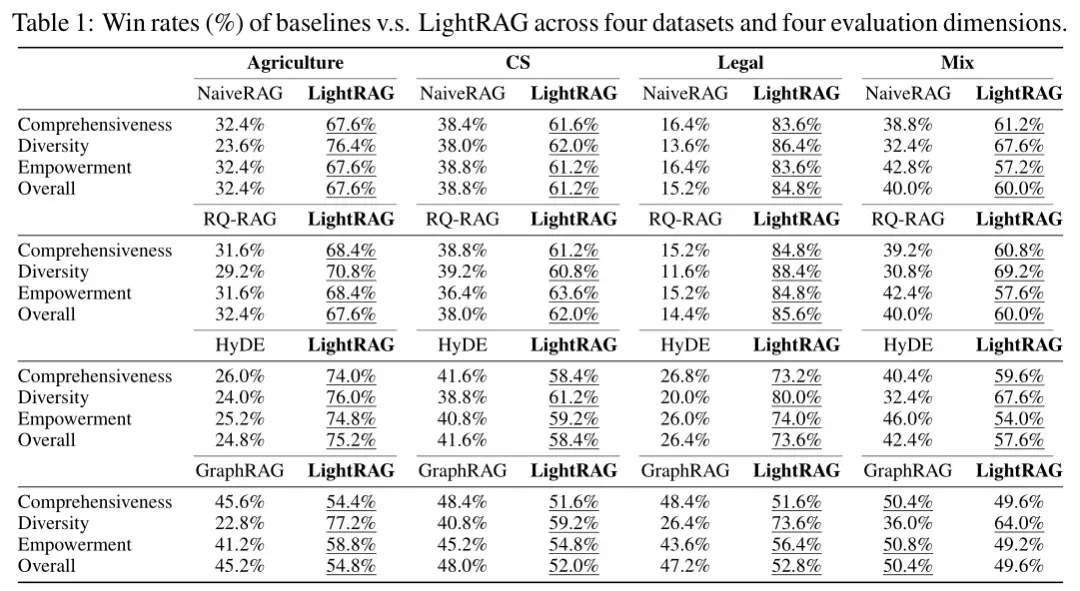
LightRAG与其他RAG方法的比较
- 图增强RAG系统的优越性:在处理大规模数据集和复杂查询时,基于图的RAG系统(如LightRAG和GraphRAG)显著优于基于文本块的检索方法(如Naive RAG、HyDE和RQ-RAG)。
- LightRAG在多样性上的优势:LightRAG在“多样性”指标上表现出色,尤其是在法律数据集上。这归功于其双层检索范式,能够从低层次和高层次同时检索信息,从而提供更丰富的回答。
- LightRAG优于GraphRAG:在农业、计算机科学和法律数据集上,LightRAG显著优于GraphRAG。LightRAG在处理复杂语言环境时表现出更强的全面信息理解能力。
双层检索和图基索引的效果
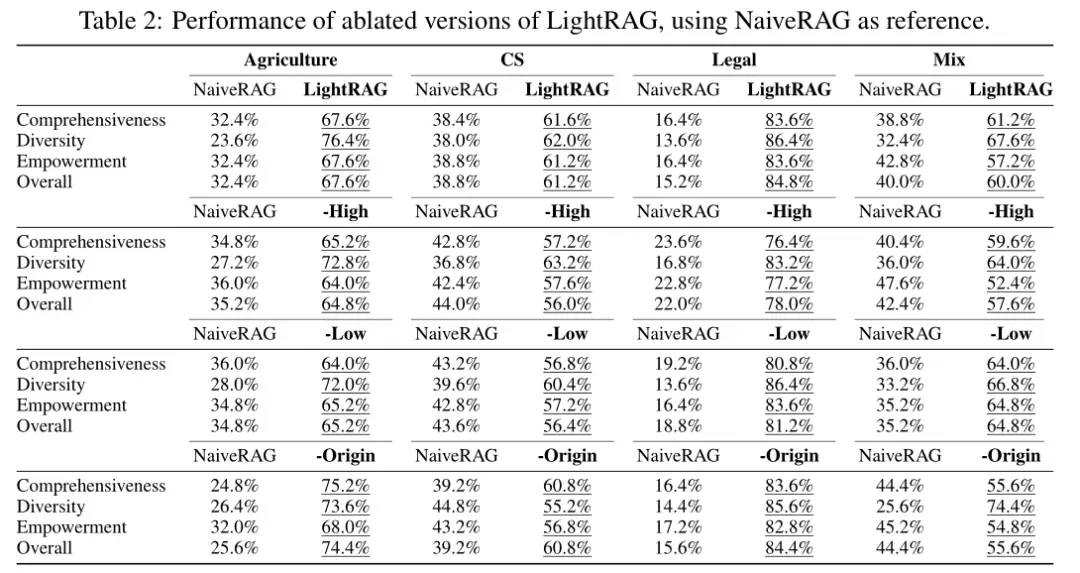
- 低层次检索的影响:仅使用低层次检索(去除高层次检索)会导致性能显著下降,尤其是在需要全面理解的复杂查询上。低层次检索更适合提供具体信息,但对于需要综合多个实体和关系的查询效果不佳。
- 高层次检索的影响:仅使用高层次检索(去除低层次检索)能够提供更广泛的信息,但在细节上不够深入。高层次检索更适合处理抽象查询,但在具体信息的深度上有所欠缺。
- 双层检索的综合优势:结合低层次和高层次检索的完整LightRAG模型在所有维度上表现最佳。
- 基于图的索引的有效性:即使不使用原始文本,仅依赖图结构进行检索,LightRAG的性能也没有显著下降。表明基于图的索引能够有效提取关键信息,减少噪声。
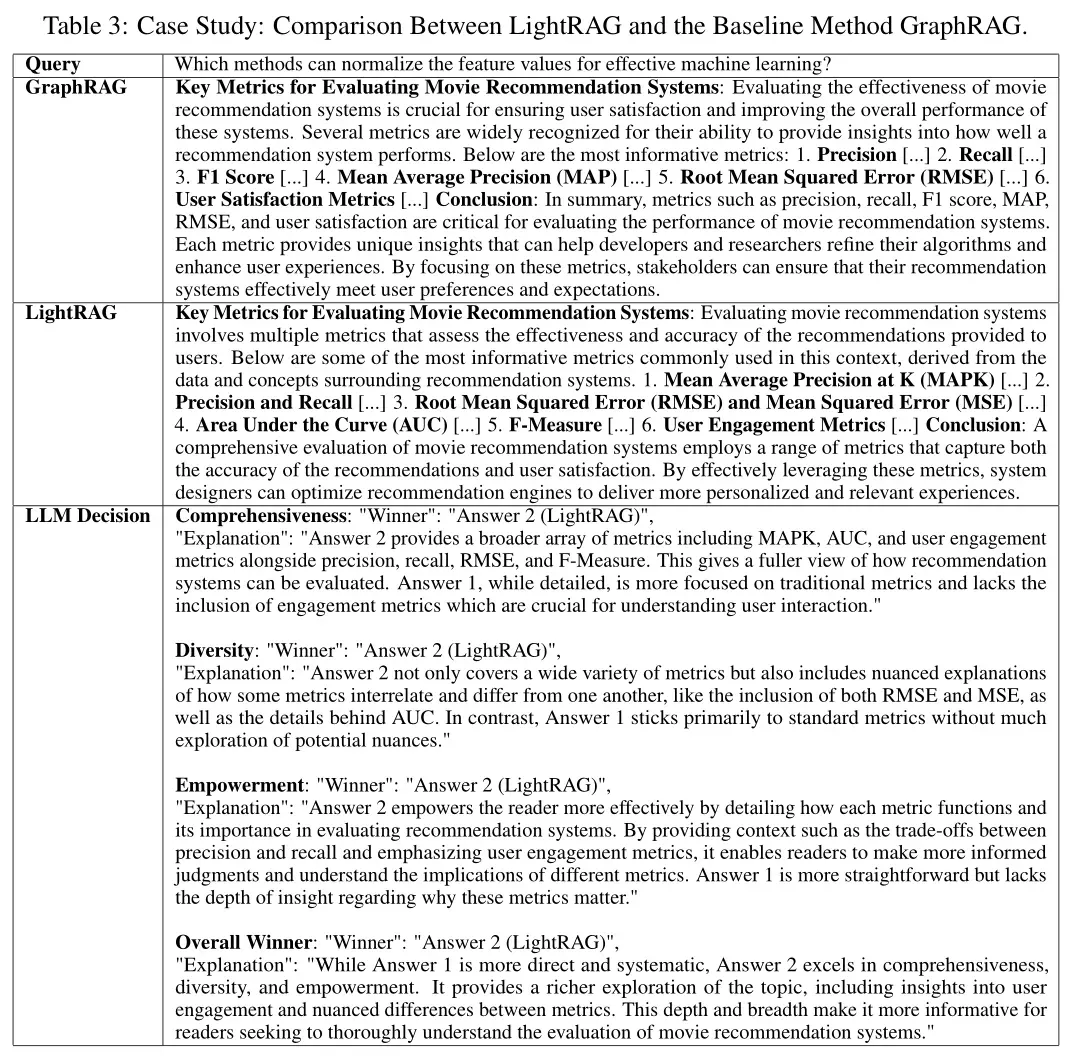
案例分析
通过对不同场景的具体案例进行分析,可以发现LightRAG在处理复杂查询时具有明显的优势。例如,在回答涉及多个领域交叉的问题时,LightRAG能够更好地整合相关信息,给出更为全面的答案。
成本与适应性
- 检索阶段:GraphRAG需要处理约610,000个token,并且需要多次API调用。LightRAG仅需使用少于100个token进行检索,且仅需一次API调用。LightRAG在检索效率上显著优于GraphRAG。
- 增量更新阶段:GraphRAG需要重新构建整个社区结构,导致更新开销约为1,399 × 2 × 5,000个token。LightRAG通过增量更新机制,仅需处理新数据,显著减少了更新开销。LightRAG在处理动态数据更新时表现出更高的效率和成本效益。

3、总结
LightRAG 通过引入基于图的文本索引和双层检索范式,在处理复杂查询和生成高质量答案方面展现了显著优势,尤其在捕捉文本块间联系和综合信息生成连贯回答方面表现出色。然而,实际应用中暴露出运行速度慢、回答精度不稳定以及实验评估方式局限等问题。未来可从优化运行效率、改进关键词提取算法、引入语义匹配技术以及完善量化评估指标等方面入手,进一步提升 LightRAG 的性能和实用性,使其在自然语言处理领域发挥更大价值。


