本文由 PLM 团队撰写,PLM 团队是由香港科技大学(广州)的校长倪明选教授,伦敦大学学院(UCL)AI 中心汪军教授,香港科技大学(广州)信息枢纽院长陈雷教授联合指导。第一作者邓程是香港科技大学(广州)的研究助理,研究方向为端侧大模型和高效模型推理;参与成员包括中科院自动化所的孙罗洋博士,曾勇程博士,姜纪文硕士,UCL 吴昕键,港科大广州的博士生肖庆发和赵文欣,港科大的博士后王嘉川以及香港理工的助理教授(研究)李昊洋。通讯作者为邓程博士,陈雷教授和汪军教授。
在大模型「卷参数」的浪潮中,一个亟待解决的课题始终存在:如何让百亿级能力的 AI 跑进手机、嵌入设备、实现万物互联?内存墙、算力墙、I/O 墙这三座边缘设备的「大山」令许多大模型铩羽而归。
近日,香港科技大学(广州)倪明选校长和陈雷教授联合 UCL 汪军教授团队以及中科院自动化所团队联合提出 PLM(Peripheral Language Model),通过算法 - 系统协同设计,选择了适合边缘设备的模型架构。
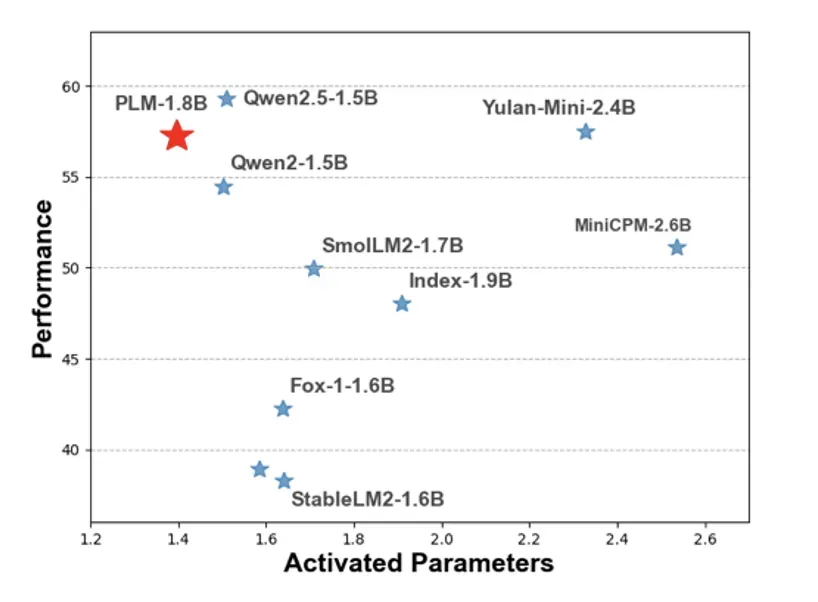
PLM 是首个结合 MLA 注意力机制与 ReLU2 激活 FFN 的架构。评估结果表明,PLM 的表现优于现有在公开数据上训练的小型语言模型,性能接近利用 18T tokens 训练的 Qwen2.5-1.5B 模型,同时保持最低激活参数数量。
其中,PLM 在通用知识理解(ARC)、数学(GSM8K)任务中表现出色,在代码能力评测(HumanEval)基准上更是以 64.6 分位居榜首。

项目论文:https://arxiv.org/abs/2503.12167
项目网站:https://www.project-plm.com
项目地址:https://github.com/plm-team/PLM
模型地址:Hugging Face: https://huggingface.co/PLM-Team
团队还将模型适配至多种边缘设备,在 Snapdragon 等芯片上展现出优于同层数模型的吞吐优势。PLM 团队不仅开源模型权重,还提供了从架构设计到部署的完整技术报告,并计划逐步开源训练数据集及相关代码脚本。

剖析 PLM:1+1 能否大于 2?
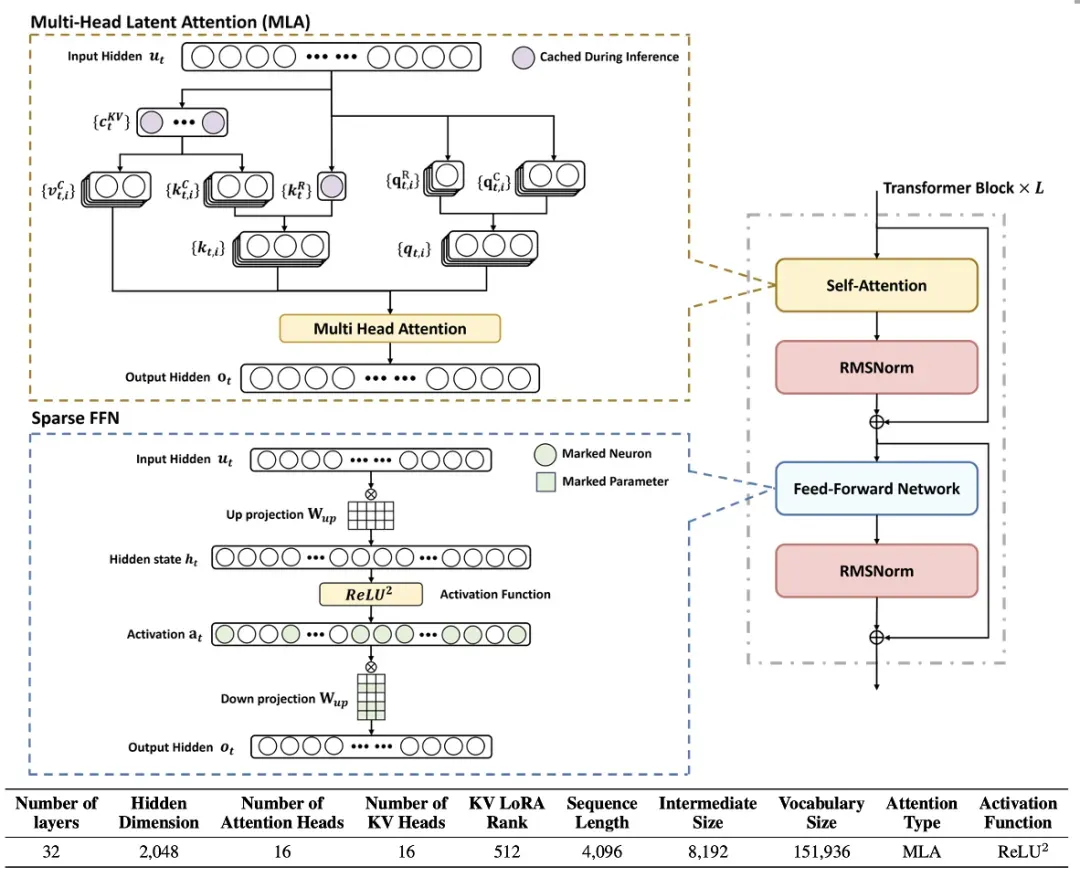
核心模块一:Multi-head Latent Attention(MLA)—— 把 KV 缓存压缩到极致
PLM 采用了 Deepseek 提出的 MLA(Multi-Head Latent Attention)注意力机制,并首次将其应用于 2B 参数以下的模型中。为适应端侧系统的需求,PLM 对 Deepseek 的 MLA 进行了适度优化,去除了训练阶段用于降低成本的 Q 矩阵压缩过程,同时保留了 KV 矩阵的 512 维度。此外,PLM 通过解耦的位置编码机制,确保了模型对长程依赖信息的有效捕捉。
核心模块二:平方 ReLU 激活 —— 让计算「稀疏化」
PLM 通过去除门控机制简化了前馈神经网络,从而有效降低了计算复杂度和内存消耗。传统 SwiGLU 激活函数导致 MLP 层计算密集,而 PLM 采用了 ReLU² 作为替代。ReLU² 是一种在性能和稀疏性之间实现最优平衡的激活函数,特别适合稀疏计算场景。其定义如下:
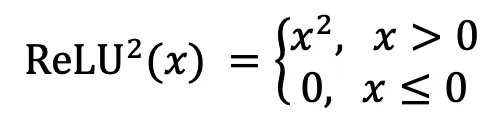
这个设计使得 MLP 层激活稀疏度达到 90.9%,整体计算量减少 26%。此外,从硬件角度出发,零值激活能够触发指令级优化。这一设计理念成功地将模型与系统的联合优化整合到大语言模型架构中。
训练策略:充分利用开源数据
三阶段锻造 PLM-1.8B
PLM 团队精心设计了一条训练流水线,仅使用未精细设计与配比的 2.48B 预训练数据,PLM 性能就达到企业级水平。所有训练数据均来自开源社区。
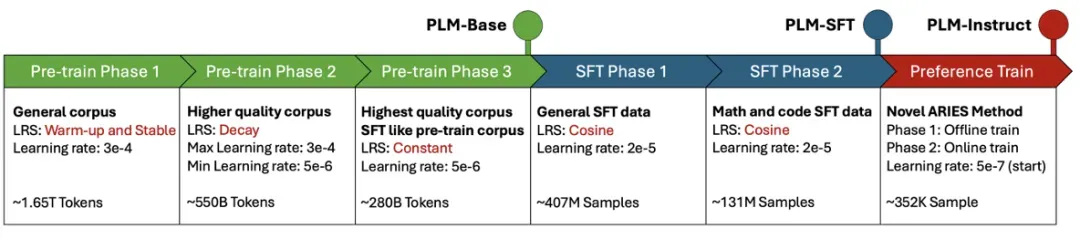
预训练
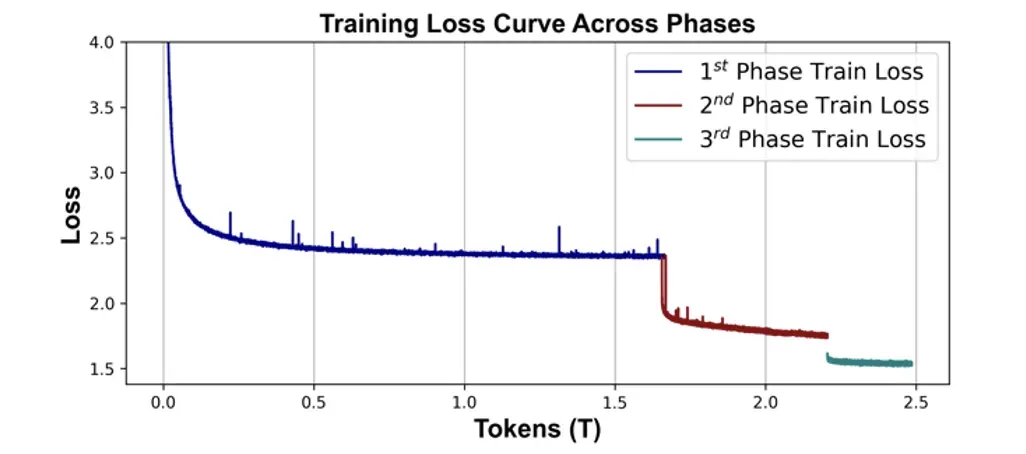
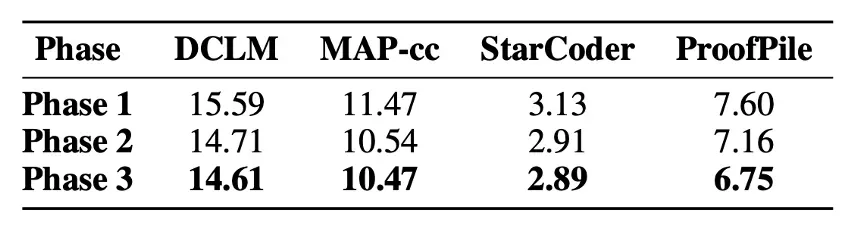
第一阶段累计约 1.65T 的 Token。这个阶段中,学习率是属于预热和稳定的阶段,模型的 Loss 也在 2.3 附近有收敛趋势。第二阶段累计约 550B 的 Token。在这个阶段,模型的 Loss 随着学习的衰减快速下降。第三阶段累计约 280B 的 Token。
这个阶段里,保持第二阶段的最小学习率训练,模型进行最后的高质量知识吸收,直到 loss 逐渐收敛。整个预训练中,始终保持中英数据比例 5:2。
SFT 阶段
监督微调数据遵循「由浅入深」的数据准备方法,以渐进的方式进行监督微调过程。PLM 的 SFT 训练分为基本指令微调和高难度指令微调。下面是各个阶段的提升效果。

强化学习阶段
PLM 在偏好训练阶段沿用了团队先前提出的 ARIES 训练方法,以解决经过一般的对齐学习会经多轮自我改进后,性能会显著下降的问题。

性能实测:真的可以
PLM 采用独特的模型架构,对比的基线模型涵盖了当前最先进的 2B 参数量级模型,具体对比如下。
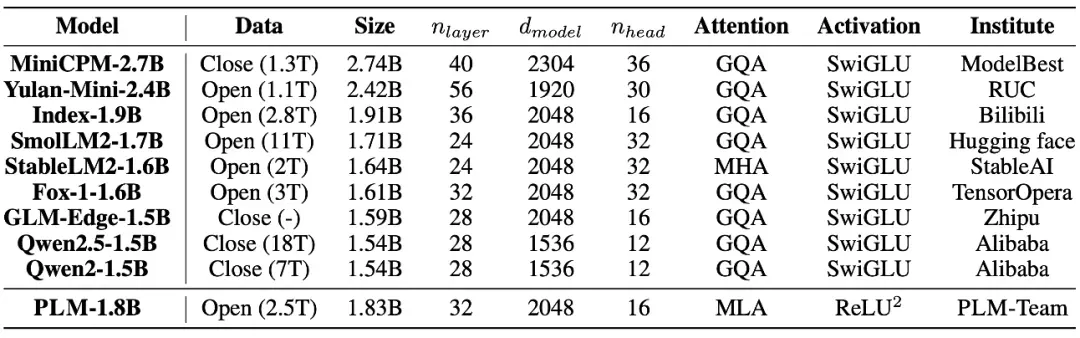
实验表明,PLM 表现颇具竞争力,平均分(57.29)位列第三,仅次于 Qwen2.5-1.5B(59.25)和 Yulan-Mini-2.4B(57.51)。PLM-1.8B 在 HumanEval 中获得了所有模型中的最高分,在 ARC-C、ARC-E、MBPP 和 BoolQ 中排名第二,略逊于行业领先的 Qwen2.5-1.5B,需指出的是,Qwen 系列使用了 18T 闭源语料库。
另一方面,与 Yulan-Mini-2.4B 相比,PLM-1.8B 在编码和逻辑推理任务中旗鼓相当。此外,PLM 仅包含 1.8B 参数和 32 层(Yulan-Mini 为 56 层),推理延迟会较低。综上所述,PLM-1.8B 在基本知识理解、编码和简单推理任务中表现强劲且可靠,是一款值得关注的模型。
场景实测:从服务器到树莓派,全场景通吃
除了基本的模型能力评估,PLM 团队还在在 5 类硬件平台完成部署验证,并给出了实际的吞吐量数据。
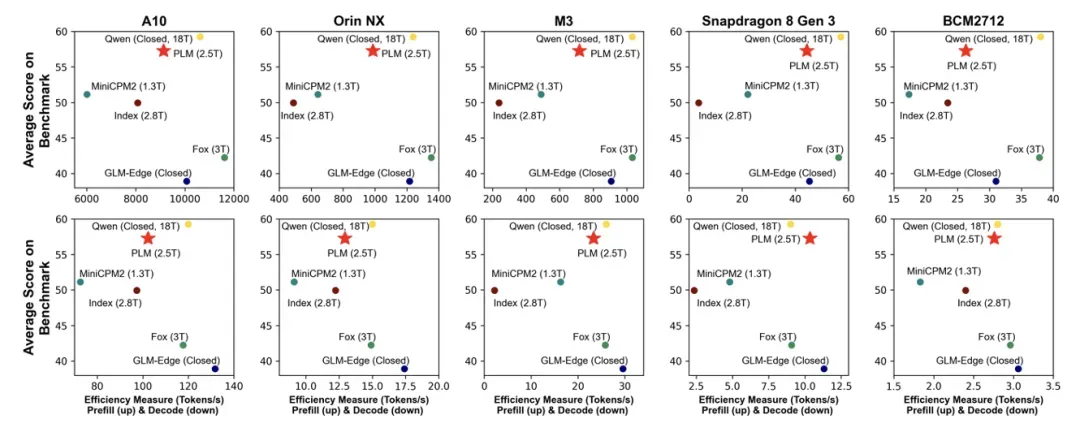
文章全面评估了不同硬件平台和量化级别的各种边缘大小 LLM 的推理延迟,包括高性能 GPU(NVIDIA A10、Orin NX)、Apple 的 M3 芯片、Qualcomm 的 Snapdragon 8 Gen 3 和 BCM2712 等嵌入式系统。
评估数据揭示了几个显著特征:MLA 的确增加了计算量,ReLU2 的确可以提升模型推理速度,模型层数会显著影响端侧设备上推理的速度。
PLM 团队的实验表明,这些关键点恰好触及了端侧计算中最需要关注的内存、算力和 I/O 三个核心维度。PLM 团队通过模型与硬件的协同设计,在这一领域展现了其独特的优势。
算法层面,PLM 做到了稀疏性与低秩的平衡:MLA 压缩 KV 缓存,ReLU² 激活削减计算,二者互补突破内存 - 算力瓶颈。系统层面,PLM 深度适配 TVM、llama.cpp 等框架,实现高效的量化与编译优化。
理解 PLM 的 MLA 和稀疏激活
在实际探索中,MLA 的引入会显著增加计算量。然而,PLM 通过舍弃 Q 矩阵的低秩压缩来降低推理计算复杂度,并结合稀疏激活函数,成功避免了 MiniCPM3 在预填充或解码阶段的低效问题,从而在特定场景中展现出明显优势。

PLM 团队在较长文本序列上评估了其模型性能,结果表明,当序列长度达到一定阈值后,PLM 的表现优于同深度的 GQA 模型 Fox。
因此,尽管 MLA 增加了计算负载,其对缓存利用率、推理效率和内存消耗的优化,使得 PLM 在边缘设备上展现出高效、低延迟的性能,为实际应用提供了显著优势。
再来看 PLM 的稀疏化设计,在边缘模型中展现出了更高的普适性与高效性。从系统角度来看,零计算已被高度优化,使得稀疏化在边缘设备上的部署带来显著性能提升。
此外,由于边缘设备的计算资源有限,模型通常无法完全加载到 GPU 或 RAM,需要 OffLoad 到缓存甚至存储中。在此情况下,深度学习模型可采用分层加载,将当前所需参数调入计算单元。
因此,最小化每层计算量至关重要。PLM 通过 KV 缓存存储与稀疏激活减少计算开销,有效缓解该问题。
PLM 团队实验验证了推理所需的最小参数量。他们对所有模型进行相同稀疏化(即将激活函数后的最小值设为 0),并测试保持建模性能(困惑度下降 1)所需的最少参数量(如下图)。
具体而言,PLM 团队绘制了稀疏率(0~1)与困惑度差异的关系图,以分析神经激活减少的性能成本。不同模型的曲线揭示了各自对稀疏度的敏感性。理论上的「理想点」—— 完全稀疏且困惑度不增加 —— 是无法实现的,因为 MLP 层完全停用将损害模型质量。
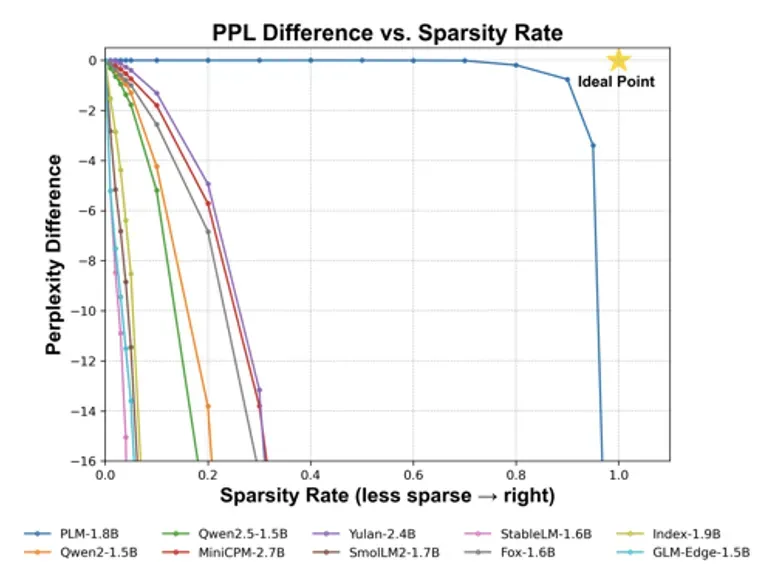
在此背景下,PLM 展现出显著优势,仅需激活 74.3% 参数,MLP 稀疏率达 90.9%,远低于同等规模模型,推理所需参数量最低。
PLM 团队已全面开放资源,为社区提供了一个小型且易于使用的 MLA 模型,使科研工作者能够在消费级显卡上开展对 MLA 的研究。同时,PLM 为端侧应用厂商提供了一个高性能的端侧模型,拓宽了选择范围,并支持基于 PLM 稀疏激活架构的高效模型部署与开发。
结语
学术界在大规模模型结构实验方面面临诸多挑战,而坚持从头预训练的团队更是少之又少。PLM 团队在计算资源有限和数据质量参差不齐的情况下,始终坚信开源社区提供的数据和技术能够为学术界的持续探索提供强大支持。
未来,PLM 团队将继续致力于探索适用于边缘设备的大模型,训练更具创新性的架构,并实现更高效的边缘设备部署。PLM 团队认为,未来的语言模型不应仅仅是参数的堆砌,而应是效率与智能的精密平衡。PLM的探索,正是向着这一理想迈出的关键一步。


