 近年来,大语言模型的能力突飞猛进,但随之而来的却是愈发棘手的双重用途风险(dual-use risks)。当模型在海量公开互联网数据中学习时,它不仅掌握语言与推理能力,也不可避免地接触到 CBRN(化学、生物、放射、核)危险制造、软件漏洞利用等高敏感度、潜在危险的知识领域。
近年来,大语言模型的能力突飞猛进,但随之而来的却是愈发棘手的双重用途风险(dual-use risks)。当模型在海量公开互联网数据中学习时,它不仅掌握语言与推理能力,也不可避免地接触到 CBRN(化学、生物、放射、核)危险制造、软件漏洞利用等高敏感度、潜在危险的知识领域。
为此,研究者通常会在后训练加入拒答机制等安全措施,希望阻断这些能力的滥用。然而事实证明:面对刻意规避的攻击者,这些防线并不牢固。模型的强大让它在被保护与被绕过之间处于微妙而脆弱的平衡。
这促使研究者开始探索在预训练阶段进行干预,从根源上防止模型获得危险能力。
目前的标准做法是数据过滤:在训练前识别并移除有害内容。然而,这一方法存在多项挑战:
标注成本高且不完美:要在数十亿文档中准确识别所有 CBRN 相关内容,既昂贵又容易出错。
有害内容常混杂在良性文档中:例如一本化学教材大部分是有益的教育内容,但其中也可能包含可被滥用的知识。
双重用途知识高度纠缠:许多概念本身具有益处与风险并存的特性,无法做到完全干净的分离。
模型的样本效率提升:最新研究表明,随着模型规模扩大,即使极少量的危险数据也可能显著提升模型在相关危险任务上的能力。
这些挑战导致一个不可避免的取舍:要么接受危险内容,要么因为过度清洗而损失大量有价值的通用知识。
为此,Anthropic 提出了 SGTM(Selective Gradient Masking),用一种全然不同的范式来应对这些挑战:它不再试图在训练前完美分类并剔除危险数据,而是在训练过程中将危险知识定位进模型中专门的参数区域。

论文地址:https://arxiv.org/pdf/2512.05648
代码地址:https://github.com/safety-research/selective-gradient-masking
论文标题:BEYOND DATA FILTERING: KNOWLEDGE LOCALIZATION FOR CAPABILITY REMOVAL IN LLMS
其核心洞察在于:一旦模型开始根据带标签的示例将危险知识存储到指定参数中,一个自我强化的过程就会出现,即使是未标注的危险内容,也会自然地聚集到同一组参数里。
这种吸附效应(absorption effect)的结果是:即便存在标注错误或漏标,危险知识仍会落入可移除的参数部分,从而实现传统数据过滤无法达到的对标注噪声的鲁棒性。
在训练结束后,只需将这部分指定参数置零,即可移除危险知识,同时保留模型的通用能力完好无损。
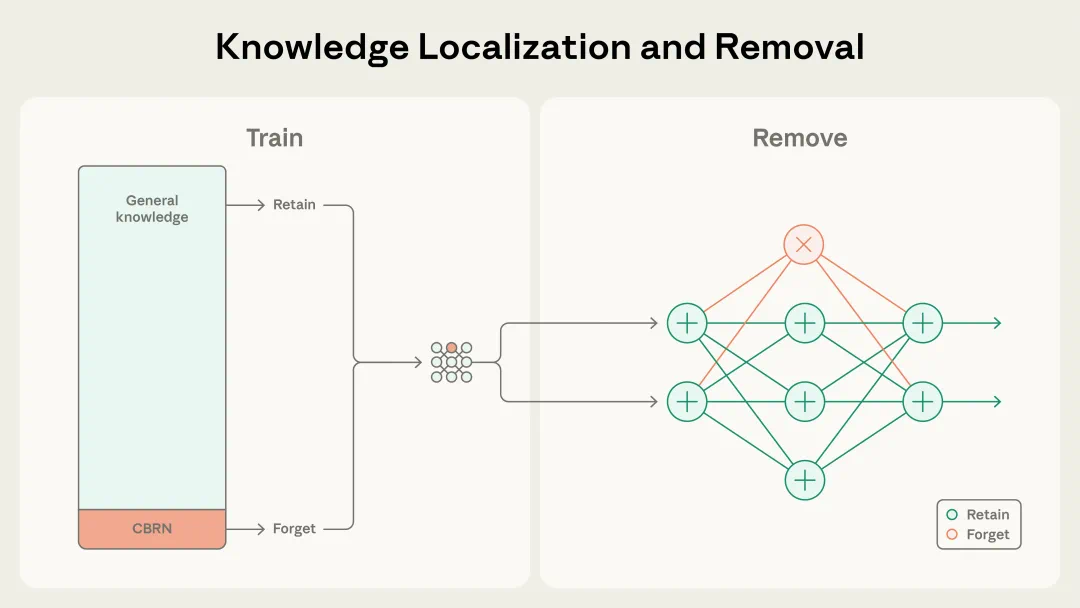
SGTM 在训练过程中将目标知识(如 CBRN 信息)聚焦到模型的特定参数中,训练完成后只需移除这些参数即可消除危险能力,同时保留模型的通用知识。
方法介绍
SGTM 基于 Gradient Routing(梯度路由)框架:它在训练过程中将危险知识集中到特定的模型参数中,随后可以通过移除这些参数来删除相关能力。
SGTM 的核心做法是:通过选择性掩码梯度来调整训练期间梯度的作用方式,从而控制不同类型的知识被存储到哪些参数中。
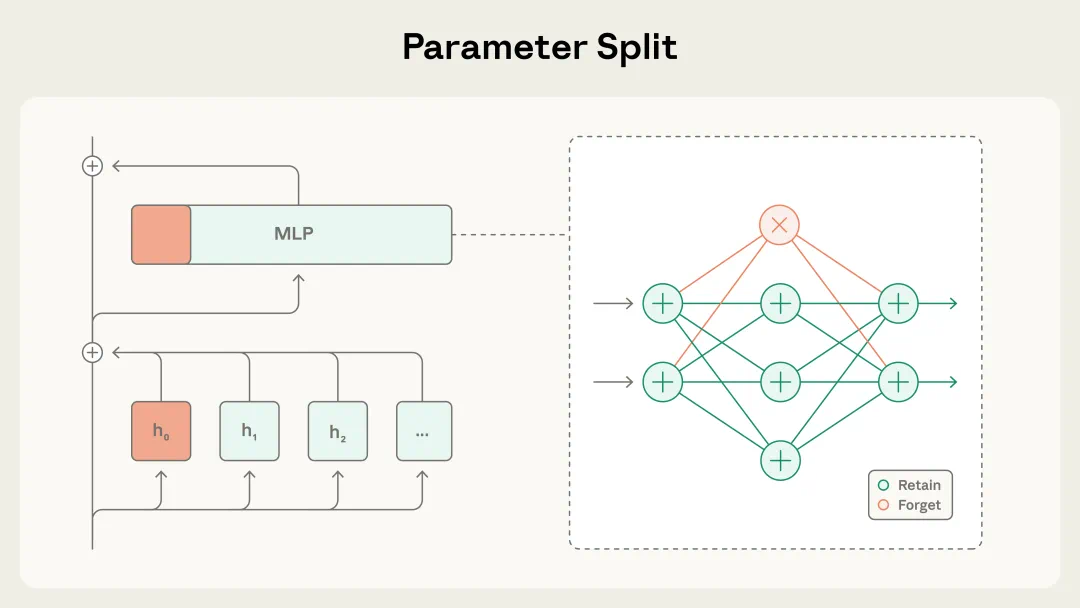
SGTM 将模型参数划分为忘却(forget,橙色)和保留(retain,蓝色)两部分。在每个 Transformer block 中,部分注意力头和 MLP 神经元被指定用于存储危险知识,其余部分则用于存储通用知识。
SGTM 的工作机制如下:
参数指定:在每个 Transformer block 中,将特定的注意力头和 MLP 神经元指定为忘却参数,负责存储危险知识;其余参数则作为保留参数,用于存储通用知识。
选择性梯度掩码:在训练过程中,当模型看到被标注为危险的数据(如 CBRN 相关内容)时,会掩码非忘却参数的梯度,使得只有忘却参数被更新。这样可以确保危险知识只能流入预设的参数区域。
消融:在训练结束后,永久性地将忘却参数置零,从而移除危险知识,同时保留模型的整体能力。
这种方法的关键在于 SGTM 对未标注数据(即不确定其是否危险)采取允许其更新所有参数的方式。但由于模型在带标注数据中已学习到危险知识应当被存储的位置,这会产生一个自我强化过程(absorption 吸附效应),未标注的危险内容也会自然地倾向聚集到忘却参数中。
从基于维基百科训练的模型中隔离并移除生物学知识
为了验证 SGTM 的有效性,Anthropic 在英文维基百科上训练了一个 2.54 亿参数的模型,目标是在移除生物学知识的同时保留其他能力。他们使用维基百科的内容分类体系为文章打标签,将其中的生物学类文章(占所有 token 的 3.7%)视为需要遗忘的数据,以便在模型中移除。
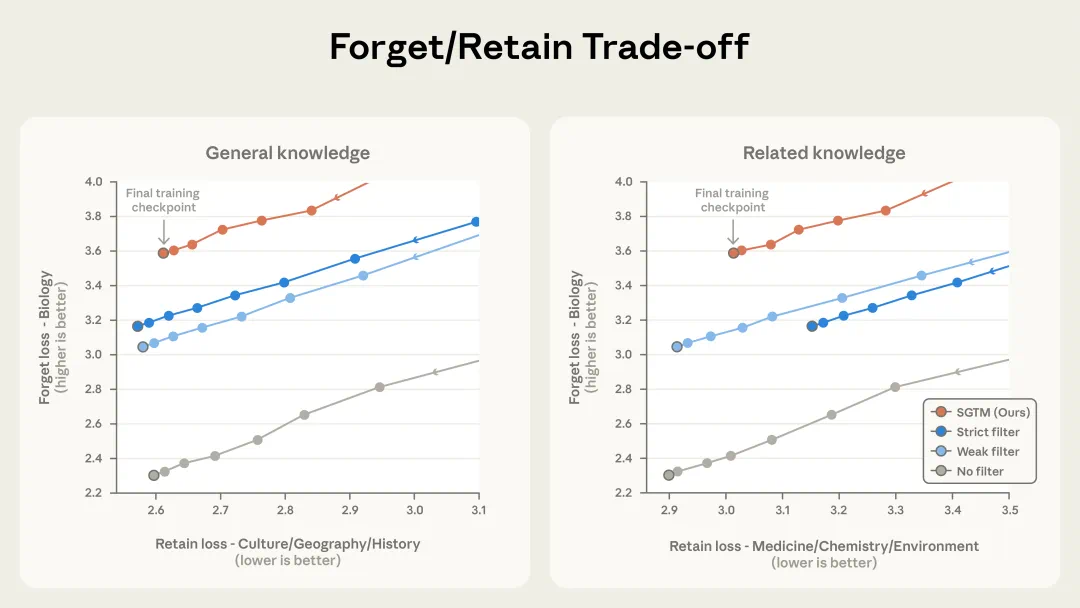
SGTM 在保持通用能力的前提下,实现了比数据过滤更好的知识移除效果。图中每条曲线代表一次训练过程。
Anthropic 将 SGTM 与两种数据过滤基线方法进行了对比。弱过滤:仅移除生物学类文章;强过滤:移除生物学 + 医学 + 化学 + 环境类文章。
结果表明:对于任意固定的 retain loss(通用能力保留程度),SGTM 都能获得更高的 forget loss(生物学知识移除强度),即在保留 — 遗忘权衡上明显优于两种过滤方案。
这种优势源于文章级标注的局限性:非生物学类文章中仍可能含有大量嵌入式生物学内容。数据过滤必须对整篇文章作二元判断,要么保留、要么移除;但 SGTM 能够从任何来源中将生物学知识局部化到 forget 参数中。
因此,SGTM 能够:
捕获弱过滤中漏掉的生物学信息
避免强过滤中对邻近学科(如医学、化学)的误伤
相比强过滤,SGTM 保留了更多与生物学相邻领域的知识;相比弱过滤,SGTM 又能移除更多生物学知识。此外,SGTM 的计算成本略有提升:在达到与标准训练相同 retain loss 的前提下,SGTM 会增加约 5% 的计算开销。
SGTM 对对抗式微调具有鲁棒性
对于任何知识移除技术,一个关键问题是:知识是否真的被移除,而非仅仅被压制?
为此,Anthropic 进行了测试:通过对模型进行对抗式微调,尝试用 50/50 混合比例的生物学数据与通用数据重新灌输生物学知识,观察其是否能够恢复。
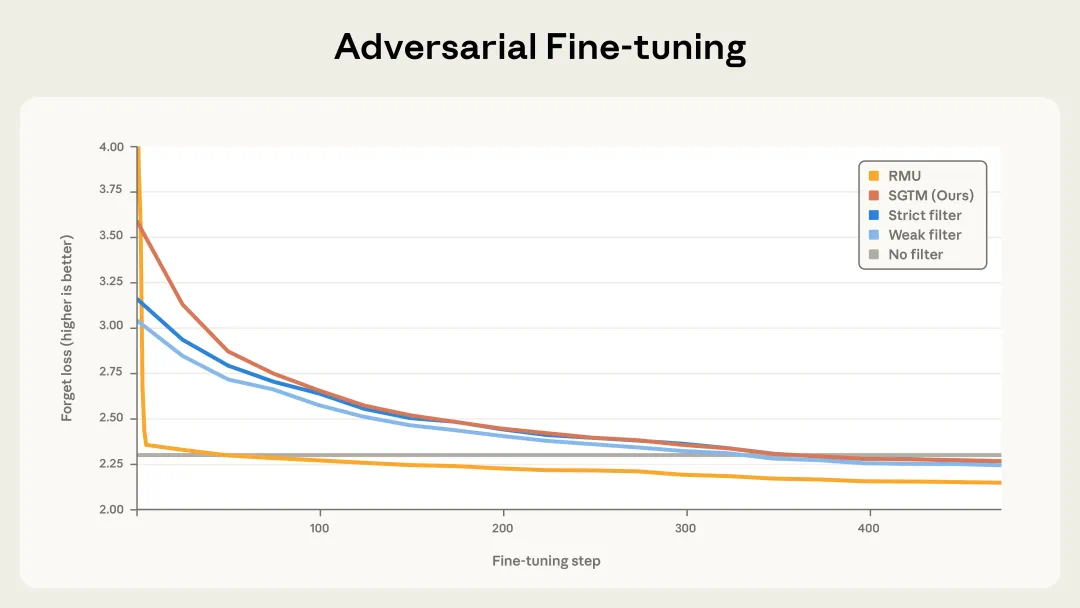
SGTM 的知识移除在对抗式微调下表现出极强的鲁棒性。相比之下,标准的后训练遗忘方法(RMU)会很快恢复被移除的知识,而 SGTM 需要 7 倍以上的微调量才能回到基线性能,其抗恢复能力与完美数据过滤训练的模型相当。
实验结果显示:
传统的后训练遗忘方法(RMU)抗压性极弱:仅需 50 个微调步骤(1300 万 tokens),模型就完全恢复了原本的生物学能力;
SGTM 则需要 350 个步骤(9200 万 tokens) 才能恢复到基线性能,抗恢复能力是 RMU 的 7 倍;
SGTM 的鲁棒性与严格的数据过滤方法相当,这表明它实现的是真正的知识移除,而非表层抑制。
机制层面的理解
为了理解 SGTM 的工作原理,本文使用双语 TinyStories 数据(将英语视为保留知识、将西班牙语视为遗忘知识)进行了受控实验,从而研究 SGTM 如何实现知识的局部化。他们在处理未标注数据时分析了其梯度范数,即将所有样本视为标签未知、且不应用任何梯度掩码,以观察不同类型的数据自然会更新哪些参数。
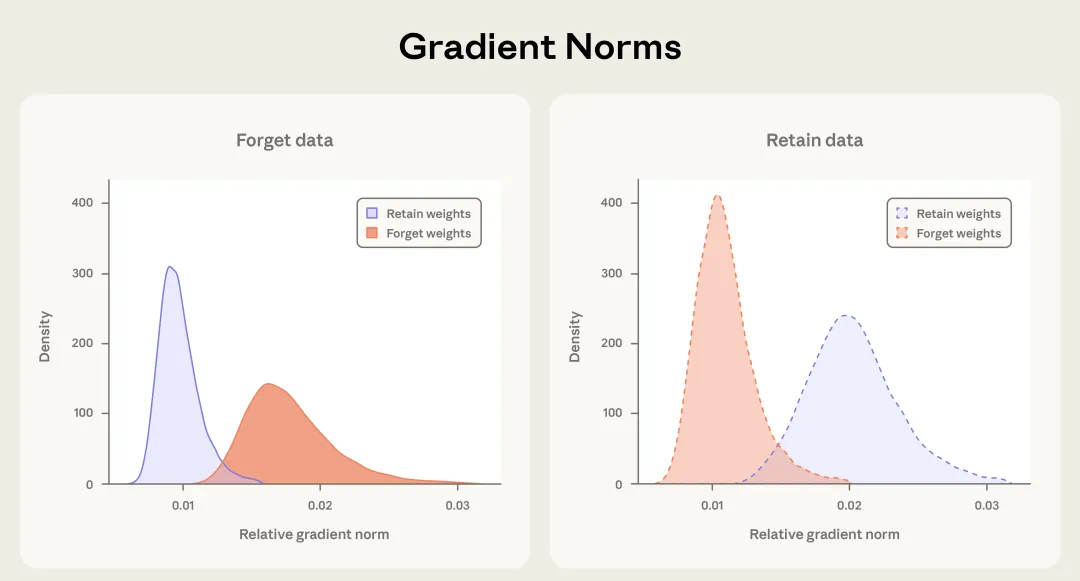
对未标注数据的梯度范数分析揭示了一个自我强化的知识局部化机制。当模型处理遗忘数据(如西班牙语)时,遗忘参数呈现更高的梯度范数;相反,当模型处理保留数据(如英语)时,保留参数的梯度范数更高。
这种吸附(absorption)机制解释了 SGTM 面对标签噪声仍具鲁棒性的原因,即使是未标注的危险内容,也会自然流向被设计用于移除的参数中。
分析显示,SGTM 的自强化机制包含以下过程:
初始阶段:带标签的遗忘样本由于梯度掩码,只会更新遗忘参数。
路径形成:模型因此在内部为遗忘领域内容建立了专门的处理路径。
自然而然的路由倾向:随后,即便是未标注的遗忘样本,也会自然通过这些路径,主要更新遗忘参数。
吸附效应:这意味着即使危险内容被错误标注或遗漏,它也会被吸附到可移除的参数中。
Anthropic 还发现,这种局部化效应会随模型规模增大而增强。在 8M 到 64M 参数规模的模型中,大模型在遗忘知识向保留参数泄漏方面表现出更低的程度,这表明 SGTM 在更大模型上效果更佳。
参考链接:
https://alignment.anthropic.com/2025/selective-gradient-masking/


