一群机械臂手忙脚乱地自己干活,彼此配合、互不碰撞。
科幻大片场景真的走入现实了。优雅,实在是优雅。

△视频中为4个机械臂,在仿真环境下4个安装在桌子上,另外4个安装在天花板上。
这就是发表在Science子刊Science Robotics上,由DeepMind、Intrinsic AI和UCL等研究机构共同提出的最新成果——RoboBallet(机器芭蕾)。

RoboBallet创新性地将图神经网络(GNN)用于强化学习,作为其策略网络和状态-动作价值估计,以解决多机器人(机械臂)协作运动规划中的复杂问题。
这一方法最多可以同时控制8个机械臂,协调多达56个自由度的配置空间,并处理多达40个共享任务, 每一步规划仅需0.3毫秒,且任务分配和调度完全不受约束。
值得一提的是,这篇论文的通讯作者——Matthew Lai,可谓是谷歌DeepMind的资深研究员。自2016年加入谷歌DeepMind以来,他曾参与过AlphaGo、AlphaZero等明星项目。

利用图神经网络与强化学习
总的来说,RoboBallet的核心是把图神经网络与强化学习结合起来,采用图神经网络(GNN)作为策略网络和状态-动作价值估计,解决了大规模多机器人任务分配、调度和运动规划的联合问题,实现了在计算上高效、可扩展且能零样本泛化的高质量轨迹规划。
具体来说,在现代自动化制造中,核心挑战在于如何让多个机器人在共享的、充满障碍物的空间中无碰撞地高效协作,以完成大量任务(如焊接、装配等)。
这涉及到三个高度复杂的子问题:
- 任务分配(Task Allocation):决定哪个机器人执行哪个任务,以最小化总执行时间。
- 任务调度(Task Scheduling):决定任务的执行顺序。
- 运动规划(Motion Planning):在关节空间中寻找一条无碰撞路径,使机器人末端执行器移动到目标姿态。
这三个子问题一组合,复杂度急剧增加,传统算法在真实场景中往往难以计算可行解,工业界目前主要依赖耗时且劳动密集的人工规划。
因此,为了应对这种高维复杂性,RoboBallet就被用来在随机生成的环境中进行任务和运动规划,其能够为与训练期间所见环境不同的环境(具有任意障碍物几何形状、任务姿态和机器人位置)规划多臂抓取轨迹。
为了实现这一点,RoboBallet在数据表示层面,创新性地将整个场景建模为图结构。
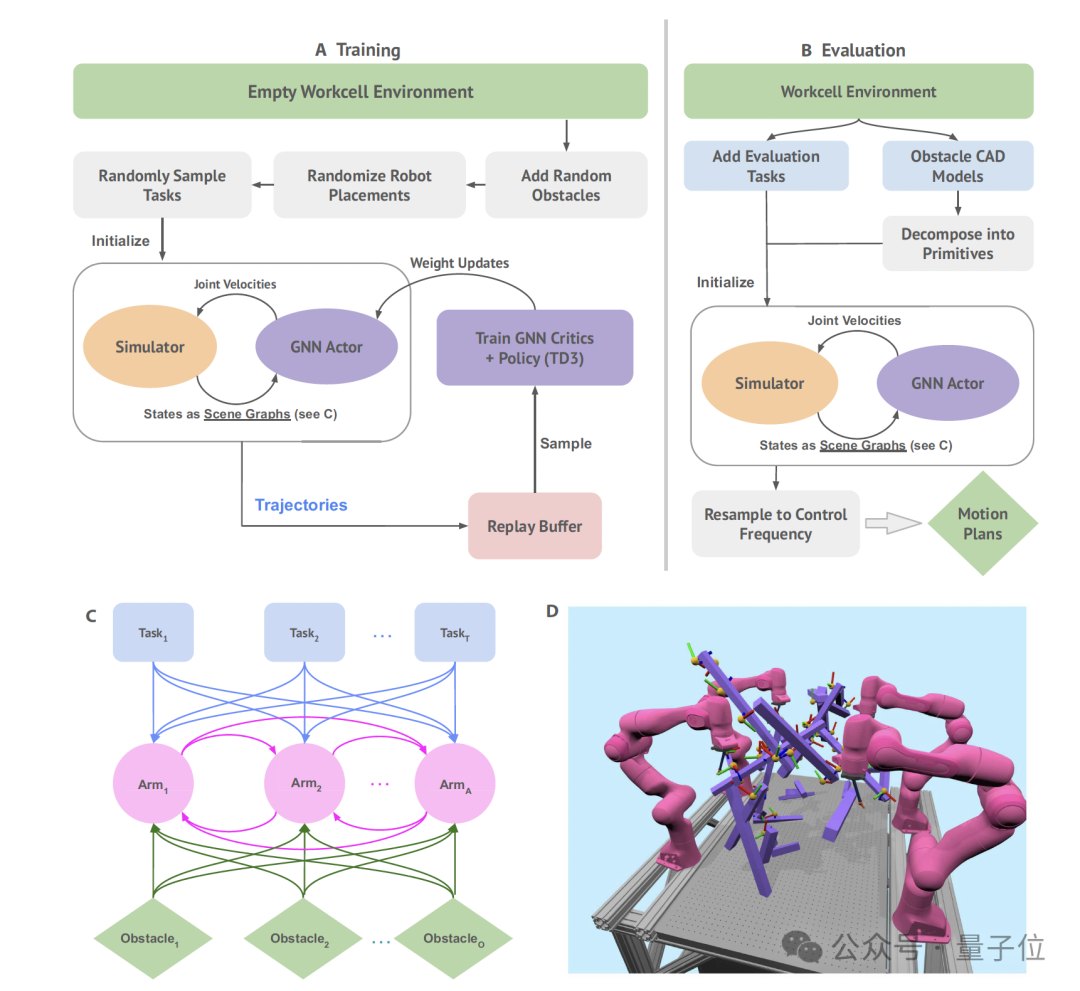
其中,图中的节点代表场景中的核心实体,包括机器人、任务和障碍物,而边(Edge)则表示这些实体之间的关系(例如,相对姿态)。
机器人节点之间存在双向边,以支持相互协调和避碰。而任务节点和障碍物节点到机器人节点则存在单向边,用于向机器人传递规划所需的环境信息(如图c)
接下来,RoboBallet使用图神经网络(GNN)作为策略网络,通过权重共享来处理不断变化的图大小。其以观测图作为输入,并在每个时间步为所有机器人生成指令关节速度。这使得机械臂能够在只接收原始状态作为输入的情况下,进行关系和组合推理。
而在具体的策略学习和评估阶段,RoboBallet通过微调TD3(Twin-Delayed Deep Deterministic Policy Gradient)算法来训练策略网络,使模型能够生成多机械臂轨迹,同时解决任务分配、调度和运动规划等子问题,使得昂贵的在线计算转移到了离线训练阶段。
(注:在此任务中,机械臂因成功解决任务和避免碰撞而获得奖励)
同时,为了解决稀疏奖励的问题,RoboBallet还采用了Hindsight Experience Replay方法,使模型能够在没有人工设计的奖励函数的情况下高效学习。
在具体的部署方面,RoboBallet使用Franka Panda的七自由度机械臂、在随机障碍物和任务的模拟环境进行训练。

为了验证性能,研究团队在一个包含4(8)个机器人、40个任务和30个障碍物的模拟工作单元中进行测试,并与RRT-Connect方法进行比较。值得一提的是,这一切都只需在一块 GPU(图形处理单元)上完成,无论是真实的还是模拟的多臂工作单元。
实验表明,RoboBallet在多个关键指标上表现出色:
在训练时间的扩展性方面,即使任务数量增加四倍,RoboBallet收敛所需的训练步数也只是略有增加。
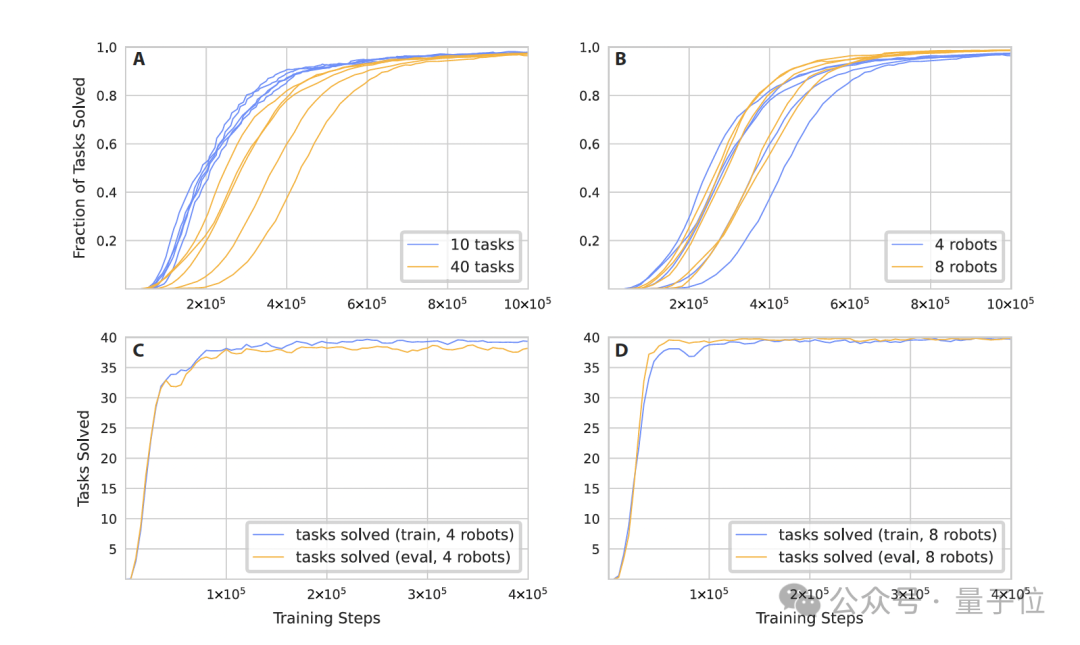
在规划速度方面。实验表明,在推理阶段,即便是包含8个机器人和40个任务的最大场景,每个规划步在NVIDIA A100上只需约0.3毫秒,能够实现10 Hz时间步下超过300倍的实时规划速度。
在单个Intel Cascade Lake CPU核心上,每个步长大约需要30毫秒,在10Hz时间步下仍比实时快约3倍。每个规划步骤包括对整个场景进行一次推理和一次碰撞检测。
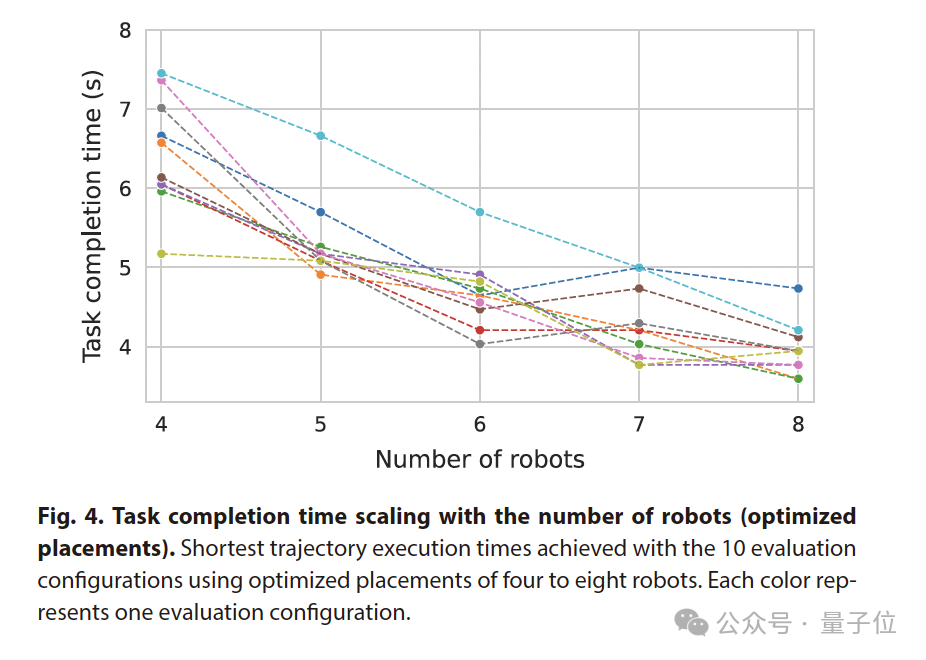
在多智能体协同方面,随着机器人数量从4个增加到8个 ,平均执行时间减少了约60%。
而在泛化性方面,模型在随机生成的环境中训练后,无需额外训练即可零样本迁移(zero-shot)到具有不同机器人位置、障碍物几何形状和任务姿态的新环境中。
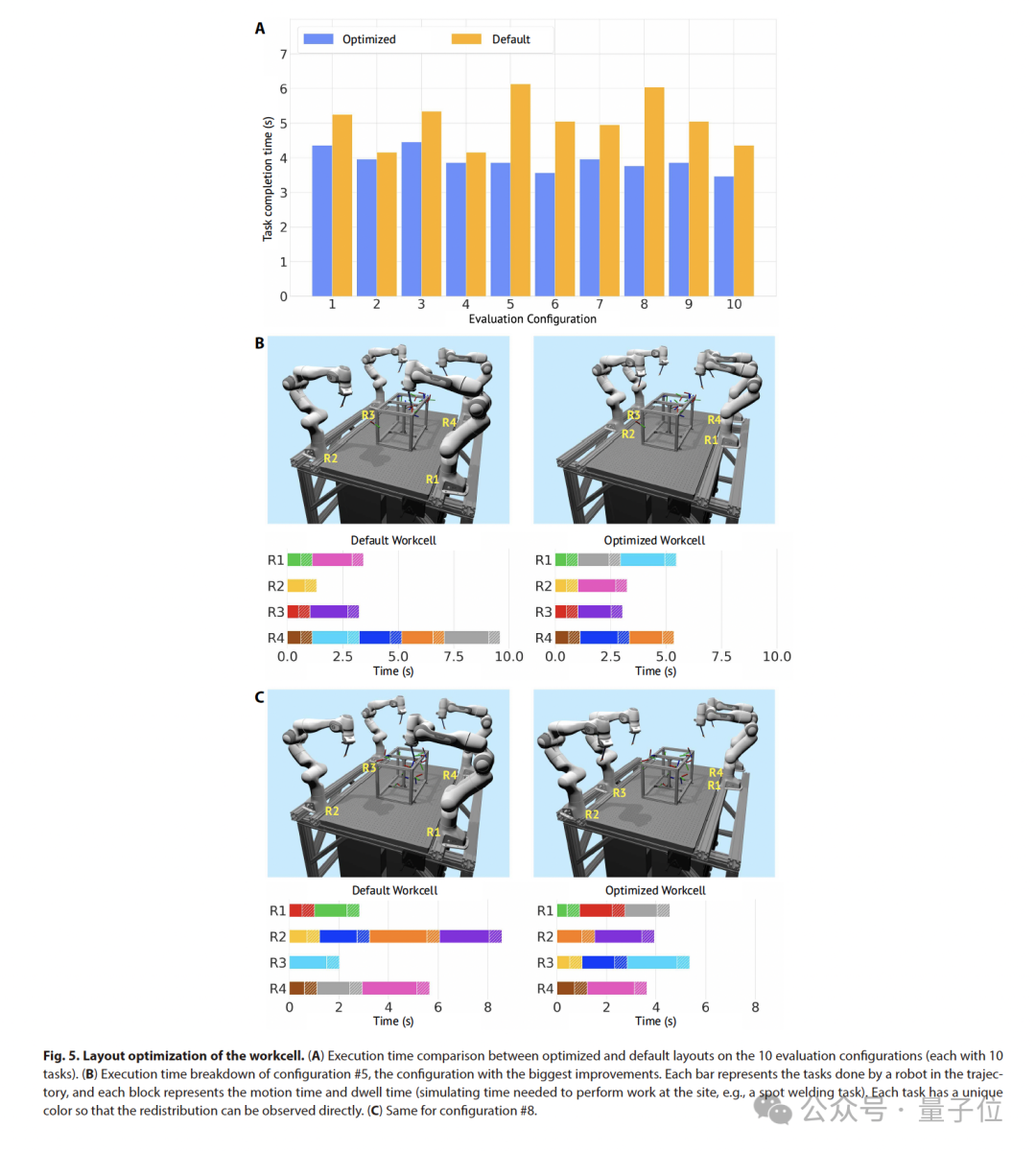
最后,RoboBallet 的高速和可扩展性使其能够应用于工作单元布局优化(将任务执行时间缩短了33%)、容错规划和基于在线感知的重新规划等新能力。