本文共同第一作者为张均瑜与董润沛,分别为伊利诺伊大学厄巴纳-香槟分校计算机科学研究生与博士生;该研究工作在伊利诺伊大学厄巴纳-香槟分校张欢教授与 Saurabh Gupta 教授,加州大学伯克利分校 Jitendra Malik 教授的指导下完成。
「The most effortful forms of slow thinking are those that require you to think fast.」 ——Daniel Kahneman,Thinking,Fast and Slow(2011)

在思维节奏这件事上,人类早已形成一种独特而复杂的模式。
我们习惯让 AI 模仿人类思维方式:先依赖直觉快速反应(System 1),再慢慢进入逻辑推理(System 2);答题时先给出初步判断,再自我反思逐步修正……模仿人类的推理节奏,已经成为语言模型推理策略的默认路径。
最近,一项来自 UIUC 与 UC Berkeley 的新研究提出:也许模型不该再走这条「人类范式」的老路。
他们提出了一种新的测试时推理调控框架——AlphaOne,主张让模型反其道而行:先慢速思考,再快速推理。

- 论文标题: AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
- 项目主页:https://alphaone-project.github.io/
- 论文地址:https://arxiv.org/pdf/2505.24863
- 代码地址:https://github.com/ASTRAL-Group/AlphaOne
令人意外的是,这一策略不依赖任何额外训练,仅需在测试阶段引入一个全局推理调控超参数 α,即可显著提升模型的推理准确率,同时让生成过程更加高效紧凑。或许,是时候重新思考:AI 真的需要「像人类」那样思考吗?
看似聪明的推理,其实是不懂停下来的错觉
近年的大型推理模型(LRMs),如 OpenAI o1 和 DeepSeek-R1,在复杂推理任务上取得显著进展,逐渐具备类似人类的 System-2 能力,能够在测试阶段主动慢思考,从而处理需要高阶认知的难题。
这些模型通过强化学习训练出的「慢思考」策略,让它们在面对复杂问题时能够自动放缓推理节奏,从而取得更好的表现。但这种自动「慢下来」的能力真的可靠吗?
与人类不同的是,大模型在推理过程中很难像我们那样灵活切换快慢节奏。心理学中描述的 System-1 与 System-2 转换,是一种受控、动态的思维过程——我们先快速判断,再在困难时激活深度思考,从而在效率与准确之间找到平衡。
相比之下,现有模型往往要么陷入过度思考(overthinking),生成冗长无用的推理链;要么思考不足(underthinking),在问题真正展开前就草率收场。
这背后的根源在于:模型缺乏对推理节奏的主动调控能力,无法准确找到「该慢下来」的最佳时机。
无需训练的全局推理调控,AlphaOne 只做了一件事
AlphaOne 的核心,是引入统一的调控点 α-moment:α-moment 之前通过 Bernoulli 过程插入「慢思考」标记,之后用终止标记切换为快思考,实现无需训练的连续推理调控。
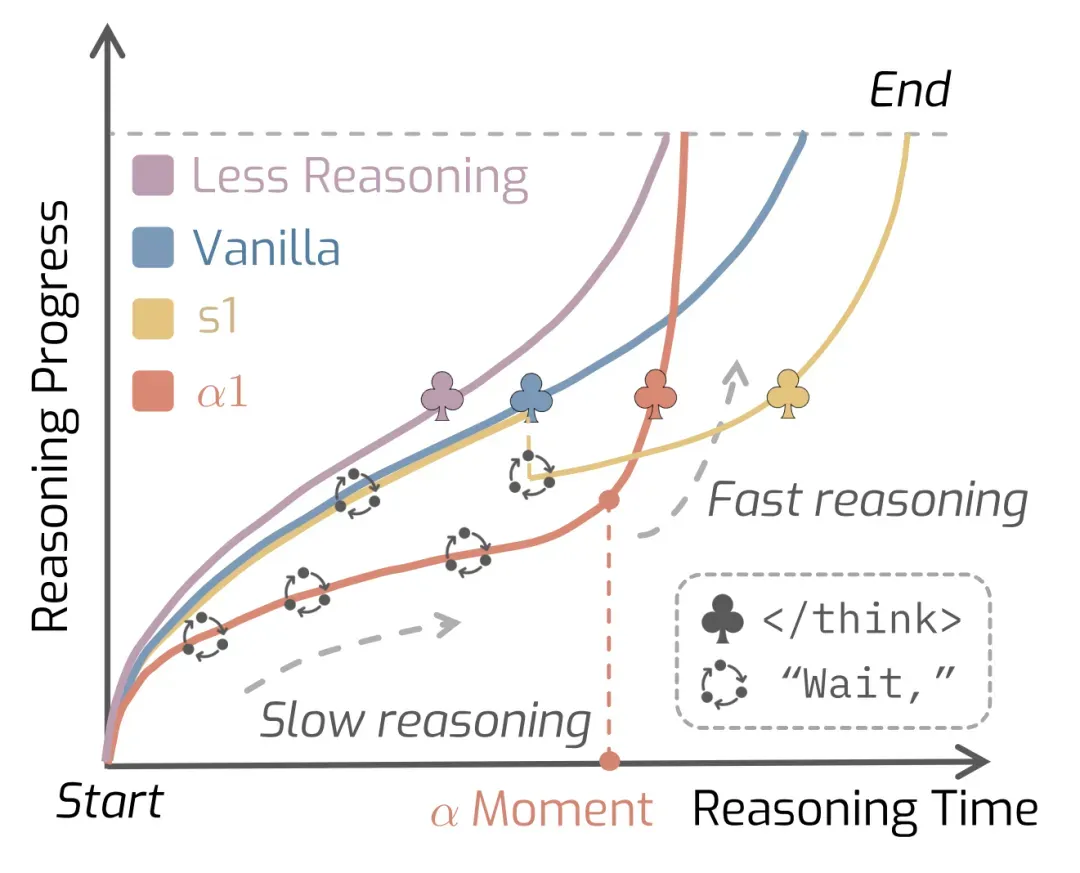
图 1: 不同推理调控方法在推理过程中的表现对比。α1(红色)采用由 α 控制的「先慢后快」推理策略,相比之下,α1 的推理效率优于单调延长思考型方法 s1(黄色),并在整体表现上普遍优于单调压缩推理型方法(紫色)。
什么是 α-moment?
目前多数现有方法要么采用固定的慢思考机制(如在末尾强制延长思考),或者采用单调压缩推理生成策略。然而,这类设计通常缺乏对推理阶段整体结构的统一建模。我们是否可以在无需训练的前提下,统一调控整个推理过程的演进方式,并设计出更高效的「慢思考转化策略」?
AlphaOne 对此提出了解答:通过引入 α-moment——一个统一的调控节点,即推理阶段达到平均思考长度 α 倍的位置。在此之前引导深度思考,在此之后转入快速推进。它不依赖固定阈值或启发式规则,而是提供了一个可调、可迁移的推理控制接口。
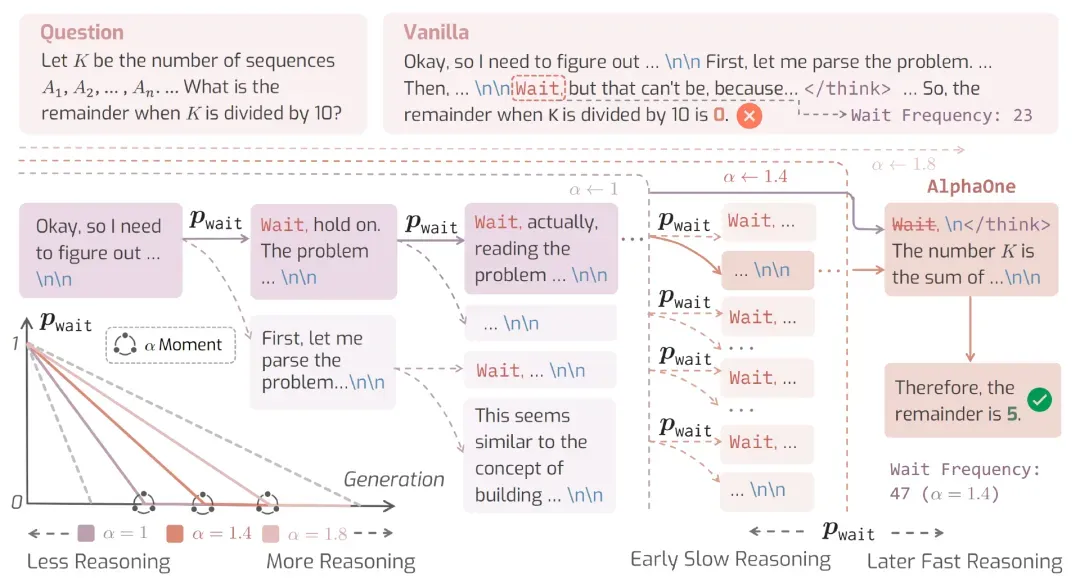
图 2: AlphaOne(α1)整体流程示意图。在 α-moment 之前,模型按照用户设定的策略,以 Bernoulli 过程插入 wait,引导深度推理;α-moment 之后,wait 会被替换为 </think>,以促进快思考。α 的数值决定这一转换的时机,例如将 α 从 1.4 降至 1.0,会提前结束慢思考,并加快 pwait 的衰减速度。
α-moment 前:慢思考调控机制
在 α-moment 之前,α1 通过一种概率驱动的调控策略,逐步引导模型进入深度推理状态。
具体来说,当模型生成结构性停顿(如 \n\n)时,会以一定概率插入 wait——这是一种慢思考过渡标记(slow-reasoning transition token),用于显式地触发模型的慢思考行为。这种插入并不是固定次数,而是基于一个 Bernoulli 采样过程,其概率 pwait 由用户设定的调度函数 S(t) 控制。
调度函数可以是线性下降(先慢后快)、线性上升(先快后慢)、指数衰减等多种形式。AlphaOne 默认采用线性衰减策略——在推理初期更频繁地引导慢思考,后期逐步减少干预,避免过度拖延。
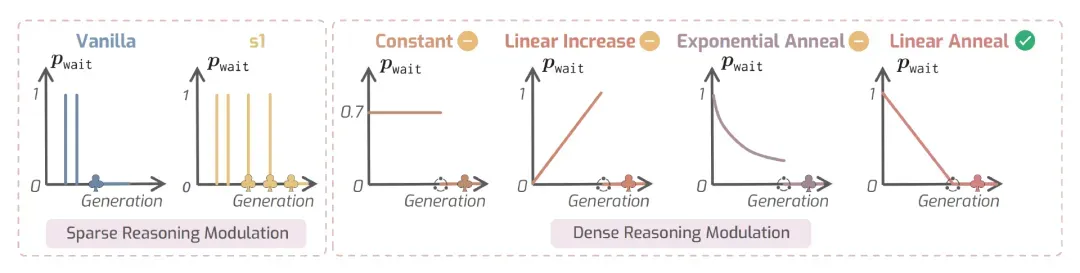
图 3: 不同调度函数的可视化
α-moment 后:快思考引导机制
但另一个挑战随之而来:如果持续插入 wait,模型可能会陷入「慢思考惯性」,迟迟无法回归高效推理。
为了解决这个问题,AlphaOne 在 α-moment 之后显式终止慢思考: 一旦生成节点超过 α-moment,所有后续的 wait(即慢思考过渡标记)将被统一替换为 </think>——这是一个思考终止标记(end-of-thinking token),用于打断延续中的慢思考链。
值得注意的是,</think> 并不代表模型立即开始作答。由于慢思考惯性,模型往往无法直接切换到答案生成阶段。因此,</think> 实际上起到的是快思考触发信号的作用,用于提醒模型当前应结束反复推理、转向高效推进。这种机制被称为确定性推理终止,它让模型能够自然地从「深度反思」切换到「快速收敛」,避免低效的推理拖延。
从数学到科学问答,AlphaOne 的策略胜在哪里?
研究团队在六大推理任务中进行了系统实验,涵盖数学题解、代码生成、科学问题理解等多种类型。
实验总结
- 准确率全面领先:无论在小模型(1.5B)还是大模型(32B)上,α1 都比原始模型和现有推理调控方法(如 s1 和 CoD)更准确。
- 以 1.5B 模型为例,α1 提升准确率达 +6.15%。
- 推理效率显著优化:尽管采用了慢思考机制,α1 在 1.5B 模型中平均生成 token 数却减少了 14%,展现出高效慢思考的非直觉优势。
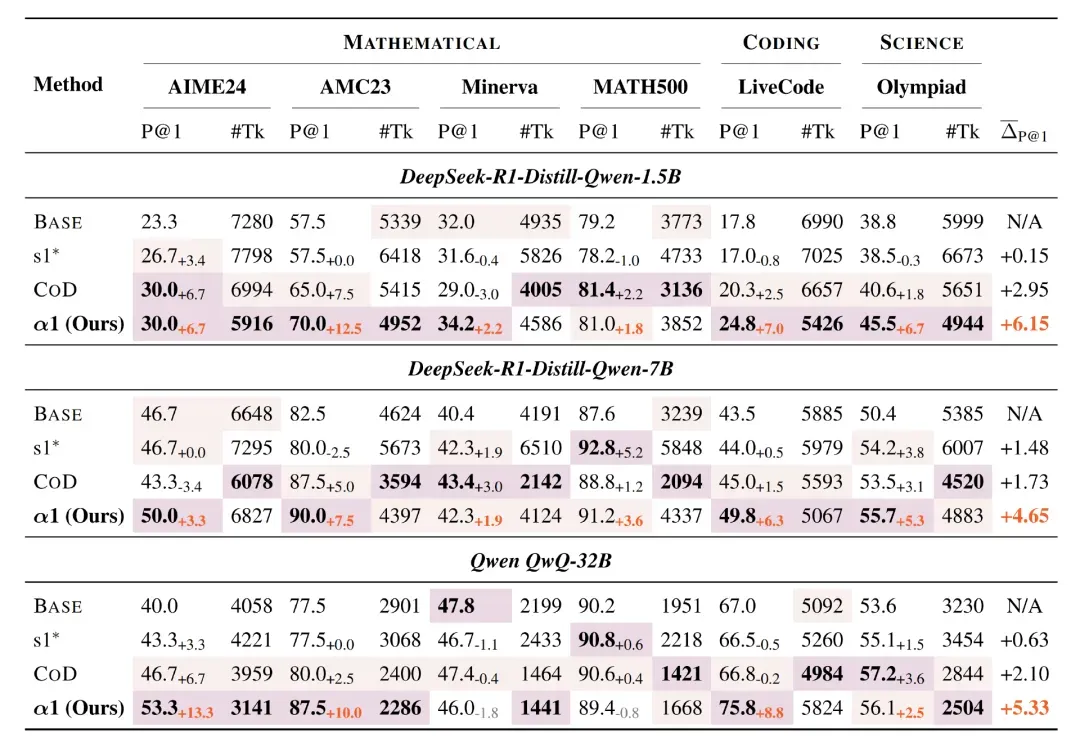
表 1:α1 与基线方法在数学、代码与科学推理任务中的系统性能比较
关键问题分析
- 哪种「慢思考调度」最有效?
对比四种调度策略(常数调度、线性递增、线性衰减、指数衰减)后发现,线性衰减在多个任务上均取得最优表现,验证了 α1 所采用的「先慢思、后加速」式推理调控方式在实践中更加有效和稳定。
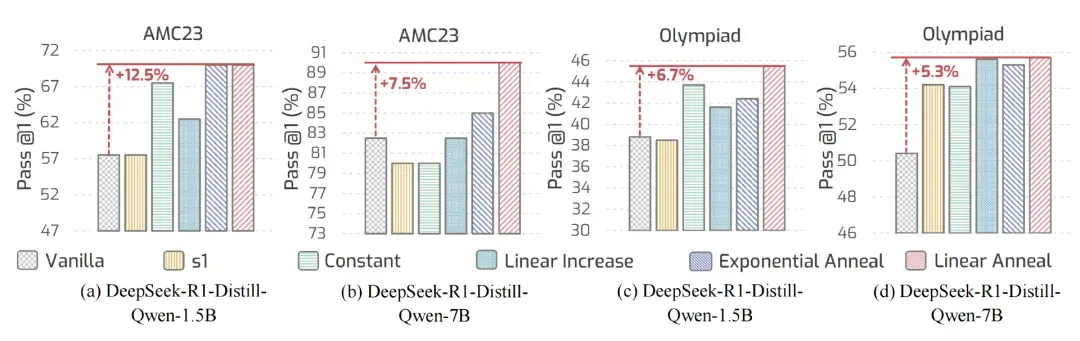
图 4: 不同调度策略在 AMC23 和 OlympiadBench 上的推理准确率
- α-moment 能否灵活调控「思考预算」?
实验结果表明,调节 α 值可以有效扩展或压缩模型的「思考阶段」长度。随着 α 增大,模型插入的 wait 标记数量相应增加,平均思考 token 数也随之增长,体现出 α-moment 对思考预算具有良好的可伸缩性(scalability)。
尽管如此,推理准确率并非随 α 增大而持续提升,存在一个性能最优的 α 区间,而 α1 在较宽的 α 调控范围内始终优于原模型,体现出良好的鲁棒性和泛化能力。
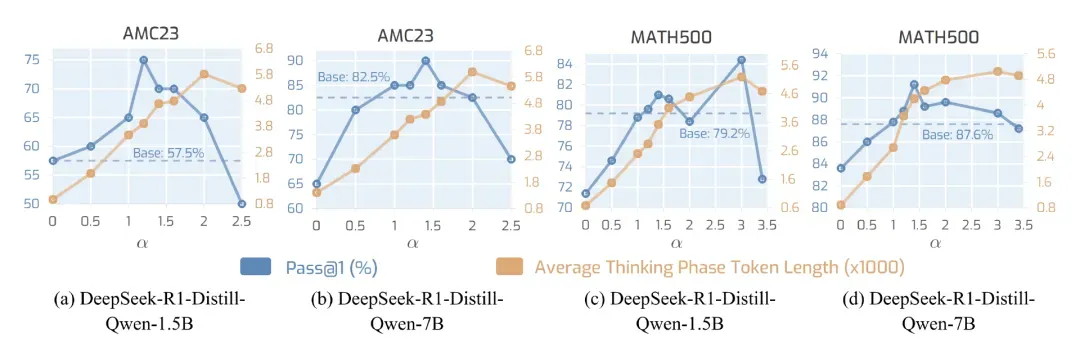
图 5:α 的缩放特性分析
- α1 推理效率真的更高吗?
使用 REP(Reasoning Efficiency–Performance)指标系统评估后发现,α1 在多个任务中更高效率下的更优推理准确率,优于 s1 和 CoD 等基线方法。
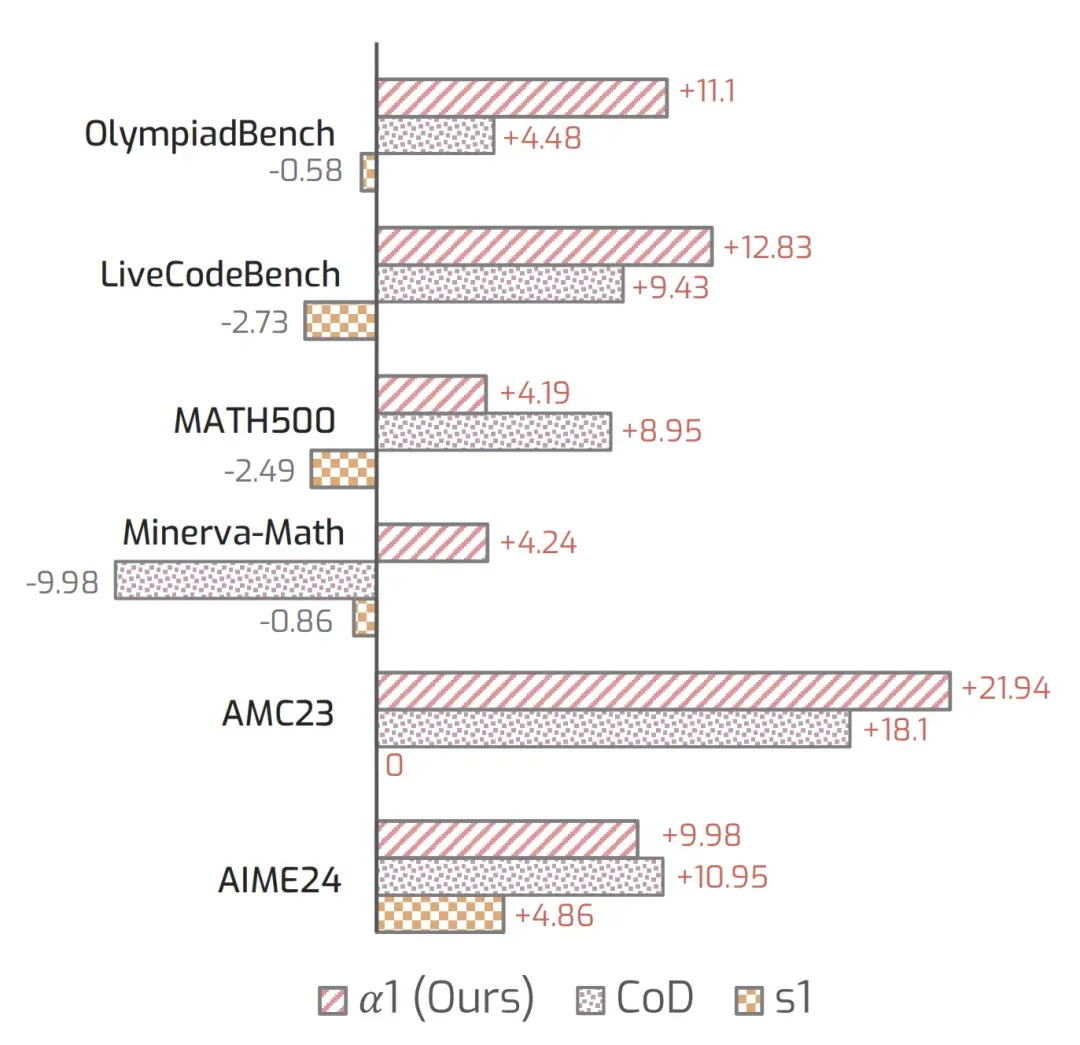
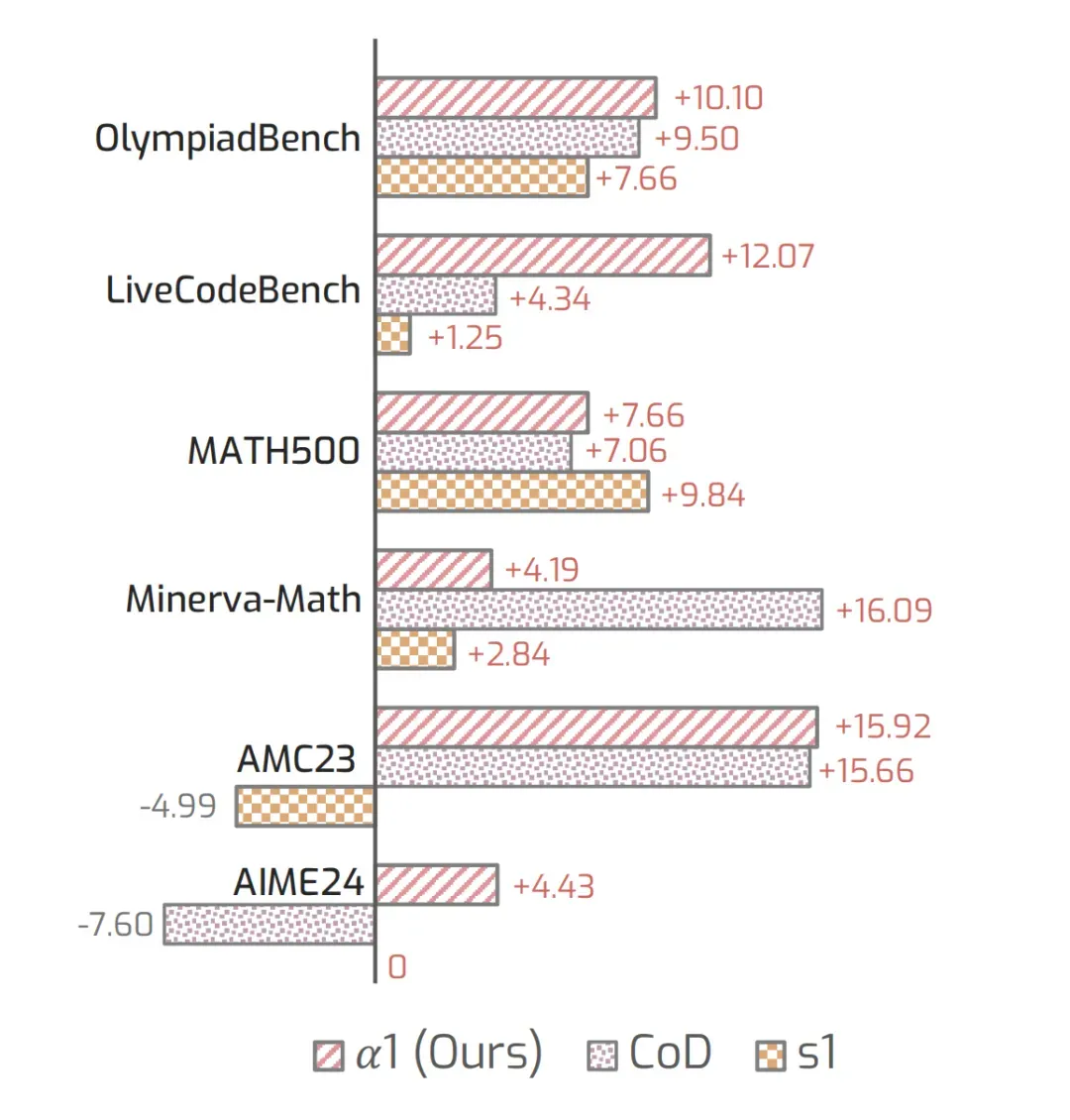
图 6: 基于 REP 指标的推理效率分析
- 慢思考标记的采样频率应如何设定?
通过调整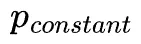 ,我们发现:过低或过高的采样频率都会降低模型性能,说明慢思考既不能太少,也不能太密。不过,α1 在较宽频率区间内依然表现稳健,说明只需设定一个适中频率,即可带来稳定的推理提升。
,我们发现:过低或过高的采样频率都会降低模型性能,说明慢思考既不能太少,也不能太密。不过,α1 在较宽频率区间内依然表现稳健,说明只需设定一个适中频率,即可带来稳定的推理提升。
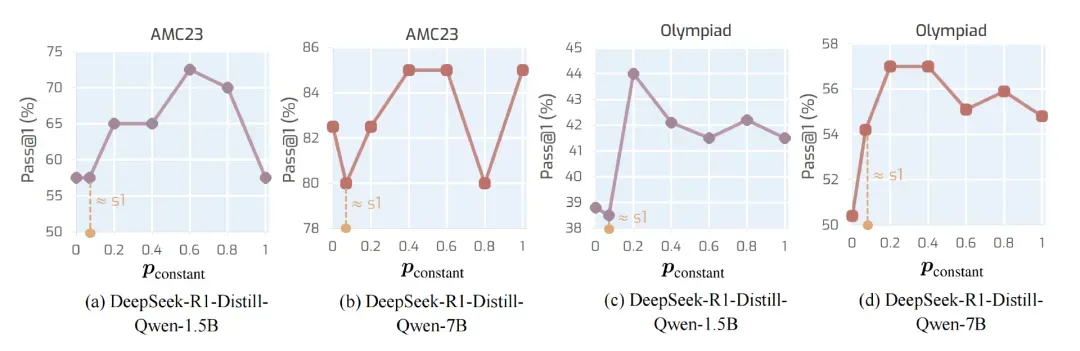
图 7: 常数调度下 wait 插入频率的缩放特性
- α-moment 后的快思考引导机制是否必要?
如果在 α-moment 后没有明确「结束慢思考」,模型容易陷入推理惯性,导致性能明显下降。实验证明,仅依赖前段慢思考调控是远远不够的。
α1 通过 α-moment 之后的显式终止操作,成功促使模型切换至快思考,验证了从快到慢的双阶段调控策略对于提升推理效果的必要性。
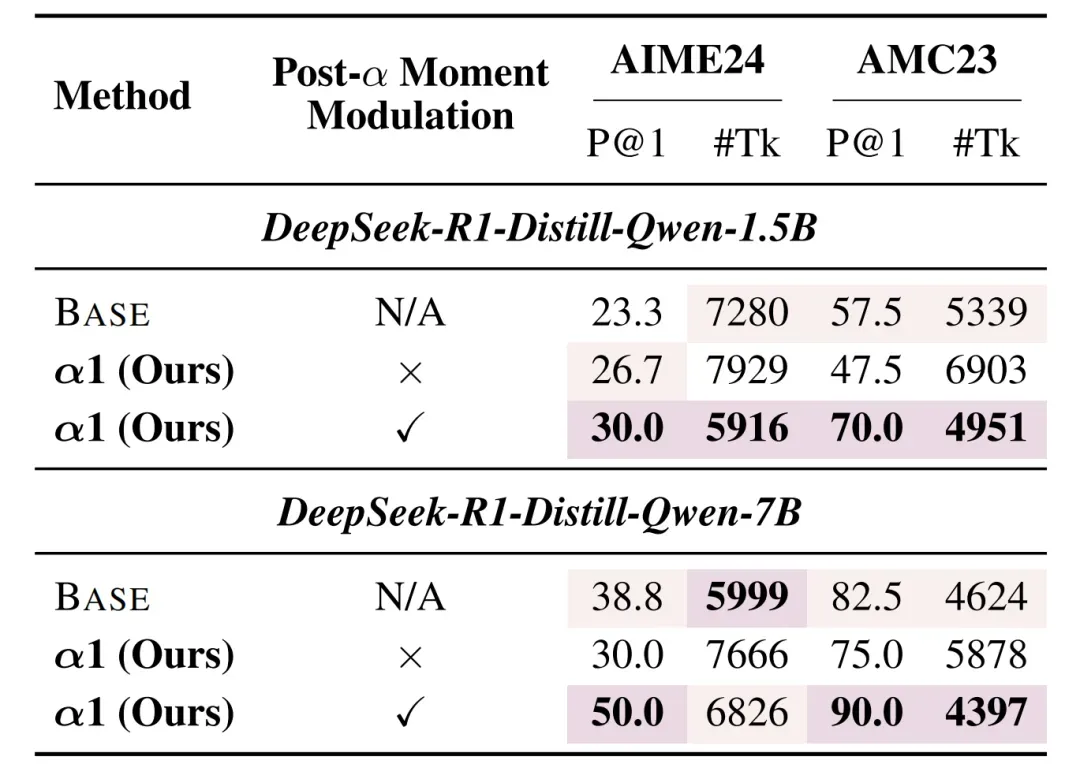
表 2: 是否启用后 α-moment 调控机制对推理性能的影响
具体案例
为了更直观地理解 α1 的作用,研究者展示了来自不同基准的推理案例,分别对应模型在使用 α1 后的成功与失败。
- 成功案例:化学混合题(OlympiadBench)

- 失败案例:多角恒等式推理(AMC23)

AlphaOne 之后,还有哪些可能?
α1 提供了一种无需训练、即可在测试阶段灵活调控推理过程的全新框架,初步验证了「慢思考→快思考」的策略对大模型推理效果与效率的显著提升。
但真正理解「思考」如何被更好地建模,仅仅迈出了一小步。研究者提出了几个值得关注的方向:
- 更复杂的慢思考调度策略:当前只探索了简单的「先慢后快」调控策略,未来可以设计更精细的调度函数,甚至发展出独立的推理调控模块。
- 摆脱特定标记的依赖:现阶段调控往往依赖 wait 等特殊转移标记,但不同模型对这些标记的响应不同。未来若能完全摆脱这些「外部标签」,将极大增强泛化能力。
- 跨模态推理的扩展:当前工作聚焦于文本推理,而多模态大模型(如图文、视频大模型)正快速崛起。未来可将 α1 框架扩展至多模态场景,探索语言与感知信息的协同推理。


