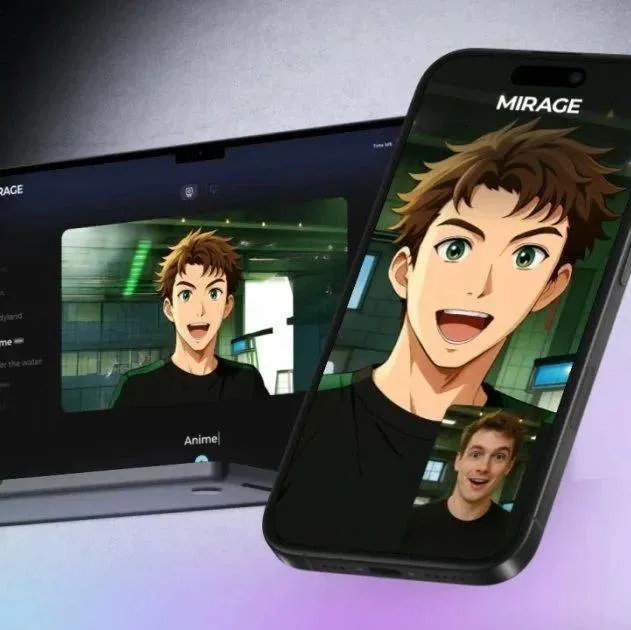
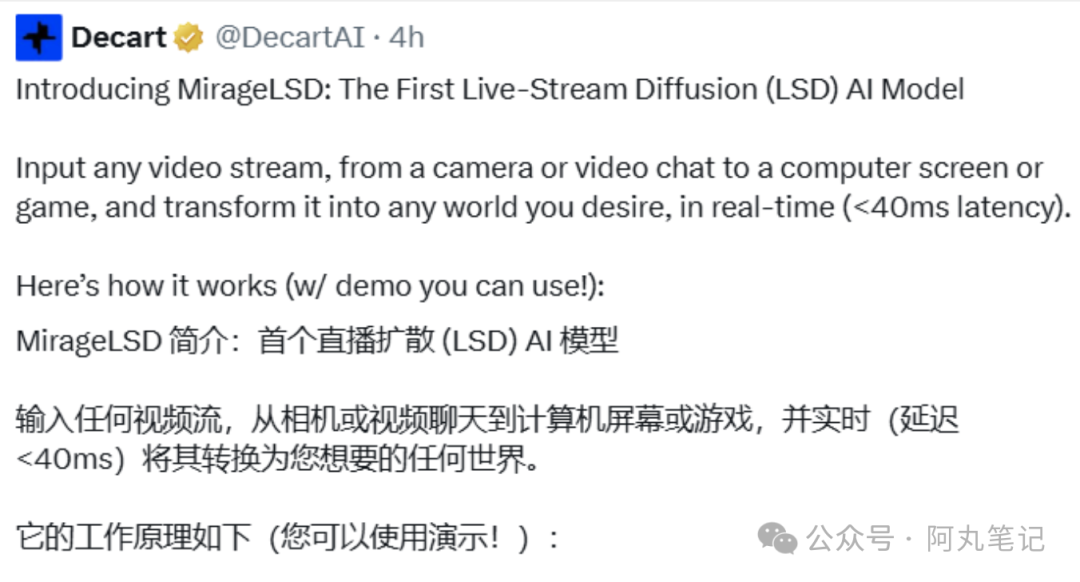
昨天看到DecartAI团队在X上发布了一条消息:"我们很兴奋地推出MirageLSD:首个直播流扩散AI视频模型。"
 图片
图片
说实话,刚看到这个宣传语的时候,我第一反应是又来一个宣传过度的AI工具。
但仔细研究了一下他们的技术细节,发现这次可能真的不一样。
如果你用过Runway、Pika这些AI视频工具,肯定对一件事印象深刻:等待。输入提示词,点击生成,然后就是漫长的等待时间。
传统的AI视频工具通常需要等待10秒以上才能生成一个5-10秒的短视频。而且生成完成后,如果你想要修改其中某个细节,就得重新开始整个流程。
从"小时级"到"毫秒级"的技术突破
MirageLSD最核心的突破在于实现了真正的实时视频生成。什么叫实时?就是你对着摄像头做一个动作,AI立即就能把你变成钢铁侠,延迟低到你基本感觉不到。
具体来说,MirageLSD的响应时间是40毫秒以下,能够以24帧每秒的速度进行实时视频转换。相比之下,其他AI视频模型的响应速度要慢16倍以上。
我试着在他们的网站上测试了一下这个功能。打开摄像头,输入"cyberpunk style"的提示词,然后就看到自己实时变成了赛博朋克风格的角色。这种感觉真的很奇特,就像魔法一样。
"MirageLSD是首个实现无限、实时视频生成且零延迟的系统。这是在屏幕上看魔法和亲自制造魔法之间的区别。" —— DecartAI团队
技术层面的两大突破
为什么以前的AI视频工具做不到这一点?主要有两个技术难题:
第一个难题:错误累积
传统的自回归视频生成模型有个致命问题:每一帧都依赖于前一帧,小的错误会逐渐累积,最终导致画面完全崩坏。就像传话游戏一样,传到最后往往面目全非。
DecartAI通过两个技术解决了这个问题:
• Diffusion Forcing - 对每一帧独立加噪声,让模型学会在不依赖完整视频上下文的情况下清理图像
• History Augmentation - 在训练时故意给模型展示损坏的历史帧,让它学会识别和纠正常见错误
第二个难题:延迟优化
要实现真正的实时生成,每一帧必须在40毫秒内完成。这对GPU的计算能力提出了极高要求。
DecartAI的解决方案包括:
• 定制CUDA内核 - 专门为英伟达Hopper GPU架构优化的代码
• 架构感知剪枝 - 去除模型中不必要的参数,同时保持输出质量
• 捷径蒸馏 - 训练小模型来复制大模型的结果
这技术能用来干什么?
实时AI视频转换开启了很多之前不可能的应用场景:
直播和视频通话:你可以在视频会议中实时变换背景和风格,把普通的Zoom会议变成科幻电影场景。
游戏和娱乐:想象一下,你挥舞一根木棍,AI实时把它变成光剑。这种即时反馈的体验是传统技术无法提供的。
内容创作:对于YouTuber和直播主来说,这意味着可以实时创造出更有趣的内容,而不需要复杂的后期制作。
我特别看好的是教育领域的应用。想象一下历史课上,老师可以实时把自己"变"成拿破仑,或者在讲物理时让学生看到分子的实时运动。
不过也有局限性
当然,MirageLSD目前还不完美。
首先是记忆窗口有限。模型只能"记住"最近几帧的内容,这意味着在长时间的视频流中,一致性可能会降低。
其次是控制精度的问题。虽然你可以通过文字描述来引导风格转换,但要精确控制特定物体或区域的变化还比较困难。
还有就是在极端风格转换时,偶尔会出现物体结构扭曲的情况。不过DecartAI说他们正在解决这些问题,今年夏天会定期发布更新。
这意味着什么?
MirageLSD的出现标志着AI视频生成进入了一个新阶段。从之前的"离线生成"模式转向"实时交互"模式,这不仅仅是技术上的进步,更是用户体验的根本性改变。
想想看,当AI可以实时响应你的每一个动作和想法时,创作的过程就变得更加自然和直观。你不再需要预先计划每一个镜头,而是可以像演员一样即兴表演,让AI成为你的实时特效师。
不过话说回来,技术再先进,最终还是要看能否真正解决用户的实际需求。MirageLSD目前还处于早期阶段,真正的价值还需要时间来验证。
如果你也对这个技术感兴趣,可以去他们的网站 mirage.decart.ai 试试,据说iOS和Android应用下周就会上线。
至少从技术角度来说,AI视频的"等等党"时代可能真的要结束了。