闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
长期以来,AGI都笼罩在“类人智能”的模糊表述中。
都说它像人一样聪明,那到底有多聪明呢?
图灵奖得主Yoshua Bengio联合Center for AI Safety、加州大学伯克利分校等机构的新作《A Definition of AGI》给AGI下了个可衡量的定义。
“AGI is an AI that can match or exceed the cognitive versatility and proficiency of a well-educated adult.”
AGI是能匹配或超越受过良好教育成年人的认知广度(versatility )和熟练度( proficiency)的人工智能。

该定义包含两个关键维度:
- 确定了参照系
- 直接锚定“受过良好教育的成年人”,避免了“AGI是超人类智能”这类模糊表述,让评估有了具体标准。
- 强调全面性
- 不看AI在单一任务上的表现,而是要求它在多个核心认知领域(如推理、记忆、感知等)都达标,不能有严重的偏科。
研究团队设计了一套量化方法来评估当前AI离AGI的距离。
为了把这个标准落地,研究者参考了心理学里验证过的卡特尔-霍恩-卡罗尔(CHC)理论这个研究人类认知能力的经典模型。
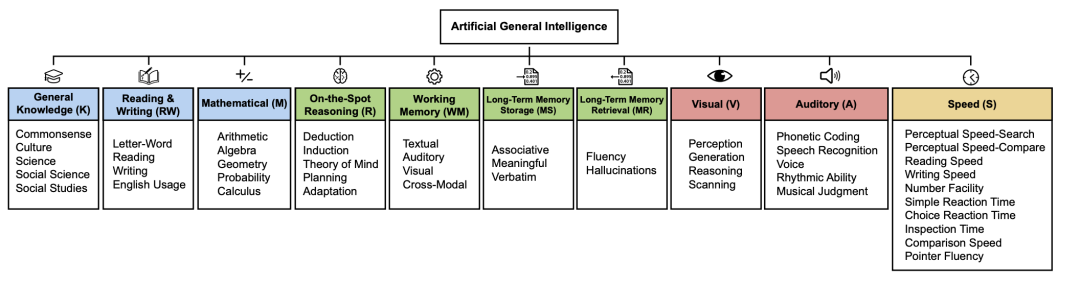
该模型将人类通用智力拆解为10个相互独立但又关联的核心认知领域,涵盖了从基础感知到高阶推理的完整认知链条,基于这10个领域,研究团队对人类传统认知测试题进行了AI适配改造。
剔除依赖人类生理感知(如触觉测试)或特定场景(如驾驶场景测试)的题目,保留核心认知逻辑,形成了一套包含500余道题目的AGI评估题库。具体包括:
- 知识(K):主要测试常识、自然科学、社会科学、历史、文化等方面的知识储备。
- 读写(RW):考察阅读和写作能力,包括对文本的理解、语言表达、文字创作等。
- 数学(M):涉及数学计算、定量推理、数字概念的掌握等数学能力。
- 临场推理(R):即处理新颖问题、进行逻辑分析与抽象思维的能力,也就是流体推理能力。
- 工作记忆(WM):指短期信息的保持与实时加工能力。
- 长时记忆存储(MS):衡量AI系统将信息进行长期稳定存储的能力。
- 长时记忆提取(MR):考查AI能否从长期记忆中高效地提取所需信息。
- 视觉(V):包括图像识别、空间定位、视觉信息解读等视觉加工能力。
- 听觉(A):涉及声音识别、语音理解、听觉信息处理等听觉加工能力。
- 速度(S):主要评估AI快速处理简单认知任务的效率。
评估采用百分制,每个认知领域满分10分,系统总分达到100分即判定为达到AGI水平,分数越高代表离AGI的距离越近。
研究团队运用上述评估体系,对当前主流LLM进行了全面测试,结果既展现了AI的快速进步,也暴露了其与AGI的巨大差距。
从总分来看,2023年发布的GPT-4总分仅为27分,而2025年版GPT-5总分提升至58分.
两年间,分数增幅超过115%,反映出大模型在认知能力上的快速迭代。

但从AGI的及格线100分来看,即使是GPT-5,也尚未突破半程线,甚至在长时记忆存储领域中拿了0分。
具体来说,当前AI与论文中定义的AGI更关键的差异体现在认知领域的不均衡性上。
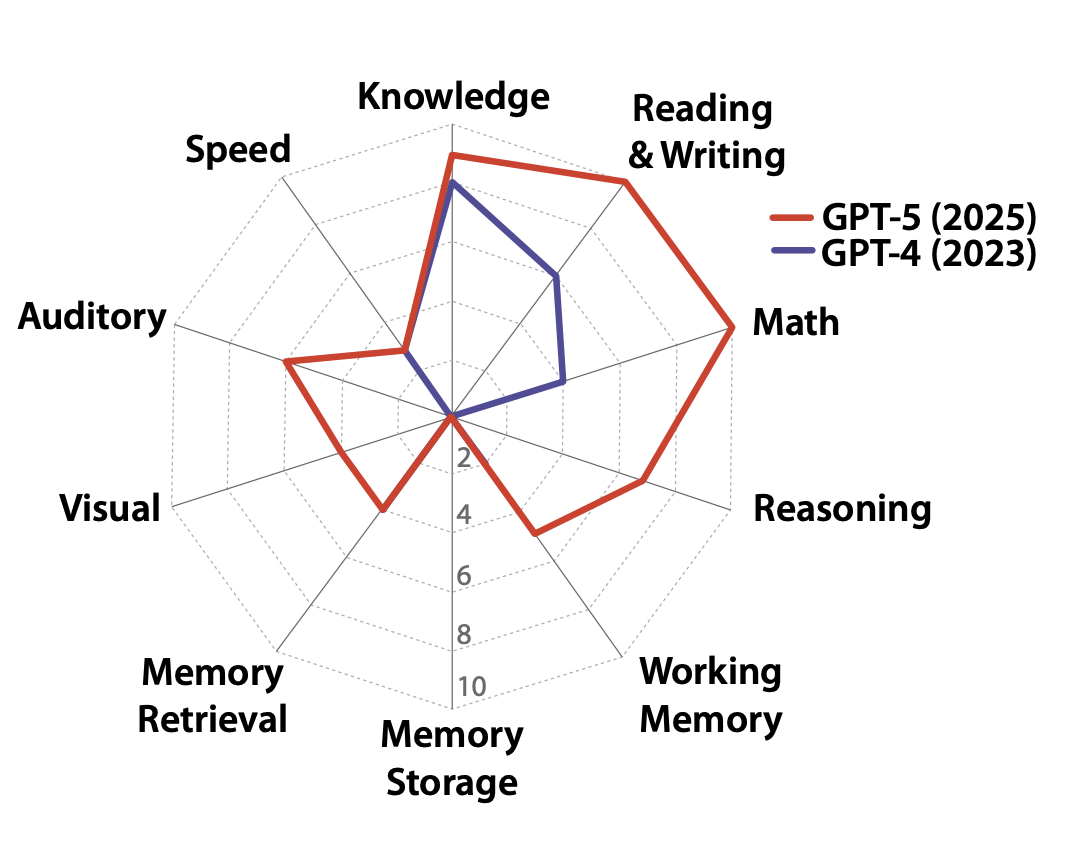
据实验结果来看,当前AI的优势高度集中于知识储备与符号处理类领域。
在知识(K)、读写(RW)、数学(M)三个领域表现突出,GPT-5在这三项的得分都超过了8。
 △知识(K)领域评估
△知识(K)领域评估
 △读写(RW)领域评估
△读写(RW)领域评估
 △数学(M)领域评估
△数学(M)领域评估
这些优势的共性在于均围绕文本符号的理解与应用展开,是大模型在万亿级数据训练中形成的模式匹配能力的集中体现。
AI在依赖海量数据训练的任务中,在这些方面展现出了接近人类成年人的水平。
与集中的优势形成鲜明对比,实验暴露出AI在感知、记忆、推理等基础认知领域存在致命短板,并且这些短板无法通过单纯的扩大规模弥补。
在 “视觉(V)” 、 “听觉(A)”领域,大模型的表现堪称惨淡。
 △视觉(V)领域评估
△视觉(V)领域评估
 △听觉(A)领域评估
△听觉(A)领域评估
GPT-4完全不具备图像识别与声音处理能力,即使GPT-5也仅能完成简单的猫犬分类、基础语音转文字,远无法实现人类级别的复杂场景解读与情感识别。
“长时记忆存储(MS)”与“提取(MR)”是另一致命缺陷,说明AI有健忘症。
 △长时记忆存储(MS)领域评估
△长时记忆存储(MS)领域评估
 △长时记忆提取(MR)领域评估
△长时记忆提取(MR)领域评估
无法实现信息的长期稳定存储,也就做不到对学习的内容灵活运用。
部分大模型看似具备多任务处理能力,实则是通过技术手段掩盖短板。
例如,部分模型通过扩大上下文窗口(如支持128k tokens的文本输入),假装具备长期记忆能力,但本质上仍是短期工作记忆的扩展,无法实现信息的长期存储与跨场景调用。
还有模型依赖联网搜索功能补充知识,看似无所不知,实则暴露了自身知识更新滞后、易产生幻觉的缺陷。
而这项研究的评估体系明确排除了外部工具的辅助,仅衡量AI系统的原生认知能力,使得这些伪全能表现无所遁形。
当然了,论文也明确指出,这套评估只看AI自身的认知硬实力,不管它能调用多少外部工具,也不看它能赚多少钱、替代多少工作,纯粹聚焦于智力本身。
就算某个AI总分再高,只要像长期记忆这样的核心领域是零分,本质上还是有严重缺陷的“残次版”智能,离真正的AGI也还差得远。
这下,AGI有了可以衡量的定义,从概念到现实,还有多久呢?
论文地址:https://www.agidefinition.ai/paper.pdf 参考链接:https://x.com/DanHendrycks/status/1978828377269117007
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态


